(24년 12월 추가)
글 내용과 관련해 강의를 런칭하였습니다. 더 많은 정보가 필요하신 분들은 참고해주세요!!
▪ 쿠폰코드: PRDTEA241202_auto
▪ 할인액: 4만원 (~25/1/5 까지 사용가능)
▪ 강의링크: https://bit.ly/3BayH1F
AutoRAG의 retrieval_gt 이해하기
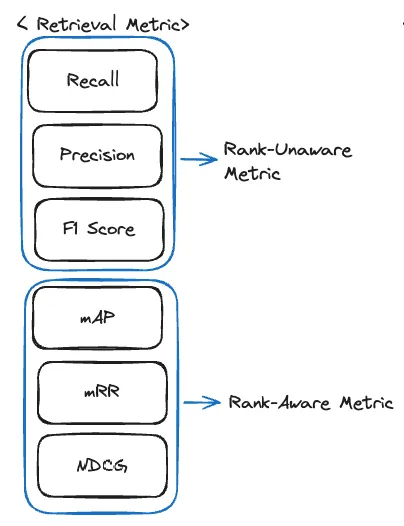
Retrieval Metrics in AutoRAG
✅ Basic Example
retrieval gt = [['test-1', 'test-2'], ['test-3']]
retrieval result = ['test-1', 'pred-1', 'test-2', 'pred-3']
AutoRAG의 gt는 retrieval_result에 ‘test-1 or test-2’ 둘 중 하나 그리고 ‘test-3’이 포함되어야 모두 정답으로 인정된다.
따라서 retrieval_result에 정답을 1, 오답을 0으로 표기한다면 [1, 0, 1, 0] 이 된다.
더 자세한 정보를 알고 싶다면, AutoRAG의 공식 Dataset Format Docs를 참고해주길 바란다.
이해가 안 되었다고 해도 괜찮다!
아래의 Apply Basic Example에서 다음 gt와 result를 이용해 설명할 것이니 천천히 따라가보자.
1. Precision
📌 Definition
정밀도란 모델이 True라고 분류한 것 중에서 실제 True인 것의 비율이다.
(Positive 정답률, PPV(Positive Predictive Value)라고도 불린다.)
❗따라서 AutoRAG에서 Precision은 (result 속 정답의 수) / (result의 길이) 가 된다.
✅ Apply Basic Example
Retrieval result에 정답은 [1, 0, 1, 0]이었다.
Precision = (result 속 정답의 수) / (result의 길이) 이므로, 이 경우에 precision은 2/4, 즉 0.5다.
⌛ Summary
- Precision = 2/4 = 0.5
2. Recall
📌 Definition
재현율이란 실제 True인 것 중에서 모델이 True라고 예측한 것의 비율이다.
- 통계학에서는 sensitivity으로, 그리고 다른 분야에서는 hit rate라는 용어로도 사용한다.
❗따라서 AutoRAG에서 Recall은 (gt속 정답에서 정답이 포함된 list의 수) / (gt의 길이) 가 된다.
✅ Apply Basic Example
Recall = (gt속 정답에서 정답이 포함된 list의 수) / (gt의 길이) 이므로, example gt의 두 list 중 정답이 포함된 list가 몇 개인지 확인해봐야 한다.
-
['test-1', 'test-2']:list속 2개의 정답 중 하나라도 result에 포함되어 있다면 이 list는 정답이다. result에 test-1, test-2 모두가 포함되어 있다. 따라서 이 list는 정답이다.
-
['test-3']: result에 test-3는 포함되어 있지 않다. 따라서 이 list는 오답이다.
정답이 포함된 list는 1개였고, gt의 길이는 2이다. 따라서 Recall은 1/2, 즉 0.5다.
⌛ Summary
- Recall = 1/2 = 0.5
3. F1 Score
📌 Definition
F1 score는 Precision과 Recall의 조화평균이다.
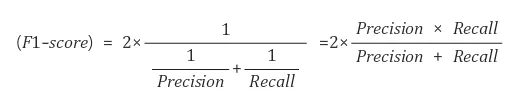
✅ Apply Basic Example
위의 결과 값을 참고하자. Precision = 0.5, Recall = 0.5이다.
따라서 F1 Score는 2 (0.5 0.5) / (0.5 + 0.5) = 0.5 이다.
⌛ Summary
- Recall = 1/2 = 0.5
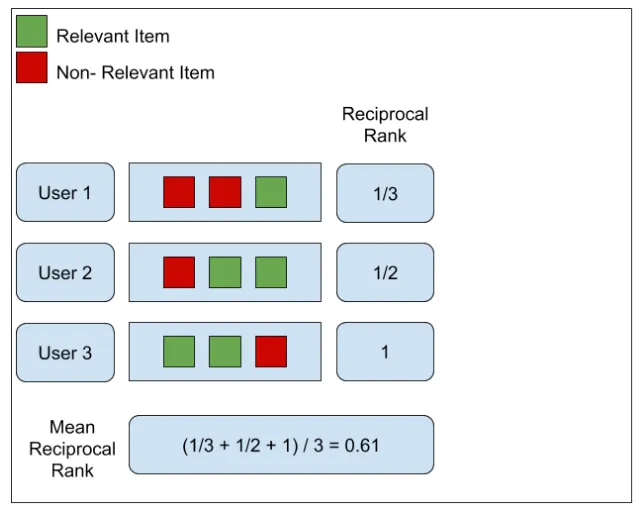
4. MRR (Mean Reciprocal Rank)
📌 Definition
MRR(Mean Reciprocal Rank)은 쿼리와 제일 관련 있는 passage가 몇 번째로 위치했는지에 대한 평균이다.
✅ Apply Basic Example
-
['test-1', 'test-2']
result에 test-1과 test-2중 먼저 나온 것의 위치를 찾아보자.
result의 첫 번째에 test-1이 있으므로, 이 list의 RR은 1 이다 -
['test-3']
result에 test-3는 포함되어 있지 않다.
따라서 이 list의 RR은 0이다.
따라서 MRR은 (1 + 0) / 2 = 1/2 다.
⌛ Summary
-
RR list = [ 1, 0 ]
-
MRR = 1/2
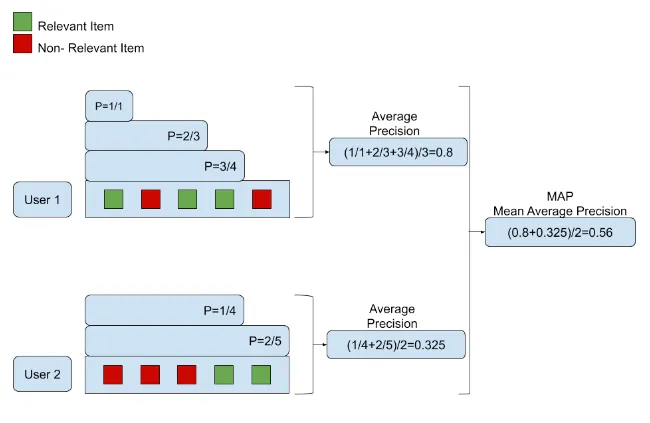
5. MAP (Mean Average Precision)
📌 Definition
MAP(Mean Average Precision)는 이름 그대로 AP(Average Precision)의 평균, 즉 평균의 평균이다.
- Precision → Average Precision → Mean Average Precision 순으로 계산한다.
✅ Apply Basic Example
-
['test-1', 'test-2']
a. test-1은 result의 첫 번째에 있다. 따라서 Precision = 1
b. test-2는 result의 세 번째에 있다. 따라서 Precision = 2/3
⇒ AP(Average Precision) = (1 + 2/3) / 2 = 5/6 -
['test-3']
test-3는 result에 포함되어 있지 않다. 따라서 Precision = 0, AP = 0
⇒ 따라서, MRR = (1 + 0) / 2 = 1/2
⌛ Summary
- Precision → Average Precision → Mean Average Precision
6. NDCG (Normalized Discounted Cumulative Gain)
📌 Definition
- CG → DCG → IDCG → NDCG 순으로 계산한다.
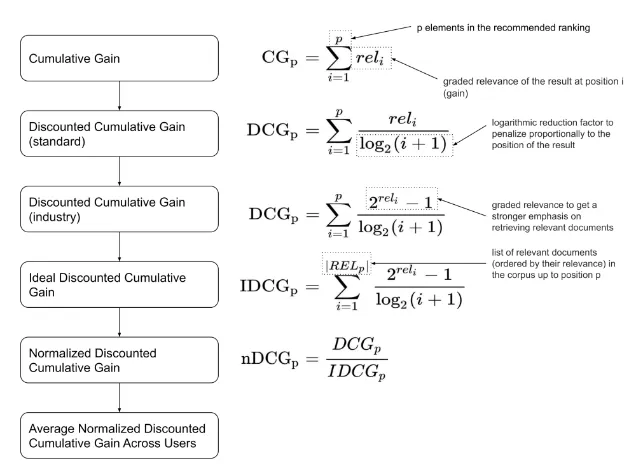
1️⃣ CG (Cumulated Gain)
Cumulated Gain (CG)는 말 그대로 관련성의 누적 합을 의미한다. 다만 CG의 경우 TopN에 포함된 Passage의 종류가 같으면, 더 관련성 있는 Passage가 높은 순위에 있는 모델과 그렇지 않은 모델의 성능이 같게 측정될 수 있다.
따라서, 이 값을 직접 사용하지 않고, discount 를 적용한 DCG를 사용한다.
2️⃣ DCG (Discounted Cumulated Gain)
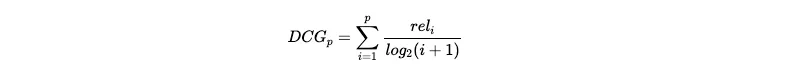
Discounted Cumulated Gain (DCG)는 관련성을 로그를 씌운 순위로 나누어 합한 값이다. 순위에 로그를 씌우면 값이 완만하게 증가하는데, 관련성을 이 값으로 나누게 되면 관련성의 영향력이 후순위일수록 작아지게 된다.
DCG에서 discounted는 이렇게 후순위의 영향력을 줄이는 것을 의미한다. 즉 DCG의 값은 상위 순위의 관련성의 영향을 많이 받고, 하위 순위 아이템의 관련성의 영향은 적게 받게 된다.
3️⃣ IDCG (Ideal Discounted Cumulated Gain)
Ideal Discounted Cumulated Gain (IDCG)는 DCG 결과의 가장 이상적인 값을 말한다. 이는 모델과 직접 관련없이 절대적이다.
4️⃣ NDCG
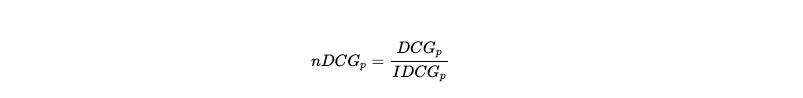
normalized Discounted Cumulated Gain (nDCG)은 정규화된 DCG를 말하는데, 이 정규화는 모델의 랭킹에 대한 DCG를 이상적인 DCG, 즉 IDCG로 나누어 0~1 사이의 값으로 나타낸다는 것을 의미한다.
NDCG = DCG / IDCG
✅ Apply Basic Example
retrieval_result에 정답을 1, 오답을 0으로 표기한다면 [1, 0, 1, 0] 이다.
DCG = 1 / log2(1+1) + 0 + 1 / log2(1+3) = 1.5 이다.
IDCG의 경우, result에 정답인 test-1, 2, 3 이 모두 들어있는 경우가 가장 이상적이다. 따라서 이상적인 result는 [1, 1, 1, 0] 이다.
IDCG = 1/log2(1+1) + 1/log2(1+2) + 1 / log2(1+3) = 2.13… 이다.
따라서, NDCG = 1.5 / 2.13 … = 0.7039180890341347 이다.
