
평화로운 AutoRAG 커뮤니티, 한 유저분의 질문이 올라왔다.
질문은 다음과 같다.
2) (hybrid_rrf의 rrf_k 값) 4 라는 의미는 무엇인가요?
LangChain에서는 0.5, 0.5 로 일단 해놨었는데,
이 비율을 최적하려면 Yaml 파일을 어떻게 구성해야 할까요?
또는 weight를 어떻게 해석해야 할까요??
이 분께서는 AutoRAG를 이용해서 Retrieval 성능을 최적화하여 최적의 Retrieval 값을 찾았다. 그것을 이제 Langchain으로 구현하여 사용하고 싶은 것이다! 어떻게 해야 할 것인지에 대한 질문이다.
자, 그렇다면 Langchain 문서를 들어가서 살펴보자.

출처 : https://python.langchain.com/v0.1/docs/modules/data_connection/retrievers/ensemble/
분명이 Reciprocal Rank Fusion, 즉 rrf를 사용한다고 되어 있다. 그런데 왜 weights를 [0.5, 0.5]와 같은 방식으로 넣는 것이지???? 그렇다면 rrf가 아니라 cc인가?
자, 일단 왜 필자가 혼란에 빠졌는지 모르는 분들이 있을 것이다. 그것을 알기 위해서는, Hybrid Retrieval을 정리해 볼 필요가 있다.
Hybrid Retrieval 요약 정리
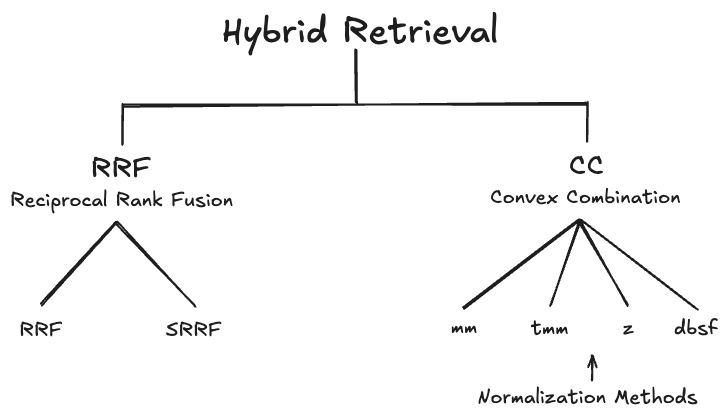
기본적으로 Hybrid Retrieval에는 크게 RRF와 CC 방법이 있다.
RRF는 순위를 이용한다. 무슨 말이냐면, 각기 다른 Retriever에서 나온 문서들의 순위가 있을 것이다. 단락 A는 1번 Retriever에서는 3등, 2번 Retriever에서는 5등과 같은 식으로 말이다. 이 순위를 이용해서 결과를 하나로 합쳐서 최종 순위를 결정하는 방식이다.
반면에 CC는 각 Retriever의 연관성 점수를 더해서 순위를 결정한다. 이 때, 가중치를 사용해서 어떤 Retriever의 연관성 점수에 더 비중을 둘지를 결정한다.
이 때, 각 Retriever간의 점수 분포가 다를 수 있으므로 Normalization을 사용한다. 그리고 이 Normalization 기법에 따라서 CC는 조금씩 다른 결과값이 도출된다.
RRF에 대해 더욱 자세히 알고 싶다면 이 글을, CC에 대해 자세히 알고 싶다면 이 글을 참고하자. (참고로 더 깊은 이해를 위해 읽고 오는 것을 강추한다)
좋다. 이제 어떤 방법들이 Hybrid Retrieval에 존재하는지 대략 알게 되었다. 그렇다면 뭐가 이상했던 것인가?
RRF의 파라미터와 CC의 파라미터
RRF는 랭크로 점수를 합치기 때문에, 가중치는 필요가 없다. 같은 양의 단락 내에서 검색을 하는 것이기 때문에, 모든 문서들은 똑같은 점수(등수) 분포를 가지게 되기 때문이다. 예를 들면, 100개의 단락 내에서 검색을 하면 어떤 Retriever를 사용하던 등수는 1등부터 100등까지이다. 그래서 weight가 필요가 없다.
반면에 CC는 당연히 가중치 합이므로 가중치가 필요하다.
자, 이제 이상한 것을 눈치챘을 것이다. Langchain의 Retriever 설명에는 분명히 Reciprocal Rank Fusion 즉, RRF를 사용한다고 나와있다. 그런데 갑자기 파라미터로는 가중치를 받는 것이다.
이게…. 뭐지?
Langchain의 내부를 뜯어보자.
자, 지금부터는 Langchain의 내부를 뜯어보는 탐험을 떠나보자.
(이 글은 Langchain 0.2.14, Langchain-core 0.2.33 버전을 기준으로 작성되었다)
class EnsembleRetriever(BaseRetriever):
retrievers: List[RetrieverLike]
weights: List[float]
c: int = 60
id_key: Optional[str] = None두 개의 변수를 주목할 수 있다. 첫 째로는 weights 그리고 c 이다. weights 는 각 retriever의 가중치라고 설명되있고, c 는 랭크에 더해주는 상수 값이라고 나와있다.
이 설명을 보면, weights 는 CC 방식의 가중치, c 는 rrf의 파라미터인 것으로 보인다. (AutoRAG에서는 rrf_k라고 부른다)
그러면, 정확히 어떻게 작동을 하는 것인가? 코드를 더 자세히 들여다 보자.
아래와 같은 함수를 찾을 수 있었다. (주의! 설명에 필요없는 부분은 임의대로 생략했다)
def weighted_reciprocal_rank(
self, doc_lists: List[List[Document]]
) -> List[Document]:
# Skip...
# Associate each doc's content with its RRF score for later sorting by it
# Duplicated contents across retrievers are collapsed & scored cumulatively
rrf_score: Dict[str, float] = defaultdict(float)
for doc_list, weight in zip(doc_lists, self.weights):
for rank, doc in enumerate(doc_list, start=1):
rrf_score[
doc.page_content
if self.id_key is None
else doc.metadata[self.id_key]
] += weight / (rank + self.c)
# Skip...인풋은 2차원 Document 리스트이다. 각 Retriever에 대한 결과가 있을 것이고, 여러 문서들에 대한 결과가 포함이 되어있을 것이다.
그렇게 이중 for문 안에서 하나의 문서에 대한 rrf 스코어가 계산이 된다.
말로만 말하면 이해가 안될 것 같다. 이 것을 수식화 해보면 다음과 같다.
(수식은 흔히 lexical retriever와 semantic retriever 두 가지를 사용하는 상황이다)
위 수식이 Langchain 내부에 구현된 Ensemble Retriever의 실체라고 할 수 있을 것 같다.
는 각 retriever의 가중치, 는 각 retriever의 단락 순위, 그리고 는 파라미터이다. (Langchain에서 c이다)
정리해 보면, RRF와 CC의 수식을 결합한 것으로 보인다.
원래 RRF의 수식은 아래와 같다.
가중치가 없고 1로 되어 있는 것을 확인할 수 있다.
원래 CC의 수식은 아래와 같다.
여기서 는 retriever의 연관성 점수 값이다. 원래는 랭크가 아니다!
그런데, 대신에 를 대입하면 Langchain의 수식과 같아진다.
결론적으로, RRF의 랭크 점수에 가중치를 붙힌 것이 Langchain의 Ensemble Retriever이다.
이게 효과가 있나?
일단, 얼마나 효과가 있는지 증거를 찾아보기 위해 Langchain 문서와 코드 등을 뒤져 보았지만 weighted RRF의 출처를 찾을 수 없었다.
더하여, Langchain에서 뭔가 실험하거나 블로그 등으로 리포트한 것도 찾을 수 없었다.
현재 실험적으로 RRF에 가중합을 적용한 Hybrid Retrieval이 효과가 있다는 자료는 찾지 못했다.
원본 논문에서도 분명히 가중합에 대한 언급은 없으며, Pinecone의 논문에도 이러한 방법에 대한 조사는 존재하지 않는다.
혹시나 관련한 자료를 찾는다면 꼭 꼭 댓글로 남겨주시면 감사하겠습니다!
하지만, 논리적으로 생각해보자. rank 함수도 일종의 관련성 스코어라고 볼 수 있다. 그렇기에, 관련성 스코어를 대신 rank 함수로 대체한 상황에서 가중합을 적용하는 것은 효과가 있을 수도 있다.
하지만, 아직 실험해보지 않아 얼마나 효과가 있는지는 미지수이다.
AutoRAG에서 평가한 것을 Langchain으로 구현하기
AutoRAG에서 Hybrid Retrieval의 성능을 최적화하여 최적의 파라미터와 Hybrid Module을 찾았다고 하자. 이를 동일하게 이용할 수 있는 방법은 무엇일까?
먼저, hybrid_rrf의 경우 Langchain의 Ensemble Retriever를 바로 사용할 수 있다. AutoRAG에서 rrf_k 값이 곧 c 값이다. 이 때, weights 파라미터는 따로 설정 없이 반드시 default로 두자.
그렇다면 hybrid_cc는 어떠할까? 안타깝게도 유사도 점수를 바로 가중합에 이용하는 Retriever를 Langchain에서 찾지 못했다... AutoRAG 팀에서 대책을 생각해 보겠다!
더 읽어보기

안녕하세요, 현재 langchain ensemble retriever 이용하여 hybrid retriever 구현중입니다.
langchain에서는 BM25, faiss retriever로 CC로 계산할수 있는 방법이 없을까요? ㅠㅠ