1. Underfitting & Overfitting
fit: 데이터를 잘 설명할 수 있는 능력
-
Underfitting: 데이터를 설명하지 못함
-
Overfitting: 데이터를 과하게 설명
-
우리의 데이터셋은 전체 일부분
-
if 우리의 데이터셋이 전체와 유사하다면 Overfitting is best(거의 없음)
Underfitting 방지
- 더 많은 데이터로 더 오래 훈련
- 피처를 더 많이 반영
- variance 높은 모델을 사용
Overfitting 제어
-
Regularization
-
early stopping
-
parameter norm penalty
-
Data augumentation
-
Noise robustness
-
Label smoothing
-
Dropout
-
Batch normalization
- 진한 부분은 정형 데이터에서도 사용가능
-
early stopping
validation error가 지속적으로 올라갈때 stop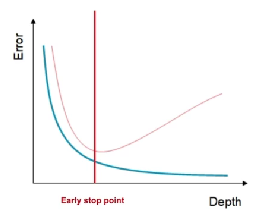
trad-off -> 최적의 결과를 찾는 과정
parameter norm penalty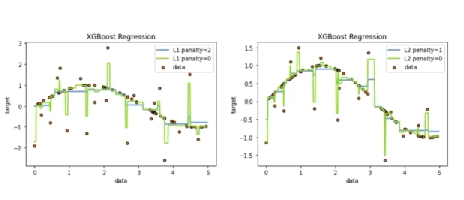
penalty의 계수를 적절하게 선택
Data augumentation
원본 이미지는 회전,축소, 확대 등 이미지 데이터 갯수를 늘리는 방법
- 의도적으로 증강시켜 머신러닝 모델에게 다양한 경험을 할 수 있게 하는 방법
- SMOTE
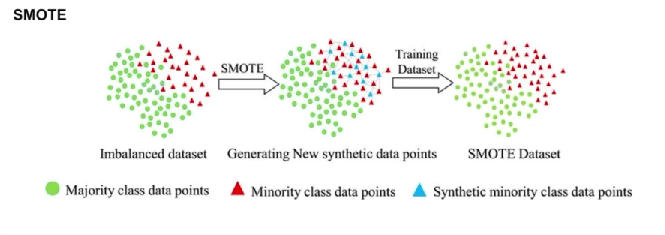
- imbalance한 데이터를 위주로 수행:
- imbalance한 데이터을 기준으로 선정하고 인접한 데이터를 찾음
- imbalance한 데이터와 인접한 데이터 사이에 있는 데이터들을 증강시키는 방법
Dropout
(딥러닝에서)무작위로 노드의 연결을 끊어버리는 것,
(정형데이터에서)피처의 일부분과 사용하여 모델을 생성(pruning)
2. Validation 전략
test
가장 중요한 데이터: 프로젝트 결과물과 직결되는 데이터로 경진대회에서 등 test 데이터로 정량적인 평가를 함
- 전체 데이터와 매우 유사한 데이터로 진행하는 것이 좋음 또한, 자주 바꿔서는 안됨
Validation
주요 목적: 학습된 머신러닝을 test 데이터에 적용하기 전에 성능평가하기 위함
이를 이용해 early stopping, Dropout를 적용할지 판단
- test 데이터와 유사한 것으로 선정
- But, test 데이터(미래)를 볼 수 없다는 것을 주의
- 좋은 Validation데이터는 문제의 배경을 파악하고 전체 데이터와 유사한 데이터를 만드는것
EX)
train
noise 데이터를 train에 포함하냐? 안하냐? 고민이 있음
데이터 분리방법
1. hold-out Validation :하나의 train, 하나의 Validation을 구성
:하나의 train, 하나의 Validation을 구성
-
imbalance한 데이터가 몰릴 수 있음
-
샘플링 방법
-
random sampling
Validation의 대표성을 안 띌수 있음(데이터 사이즈가 크고, Validation이 크다면 랜덤하게 해도 대표성이 있을 수 있음) -
stratified split
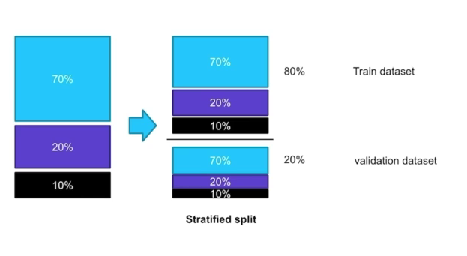
categorical feature의 비율을 유지하면서 split할 수 있는 방법이 있음
- 보통은 8:2,데이터가 많으면 9:1, 테스트를 많이하면 7:3
-
- Cross Validation
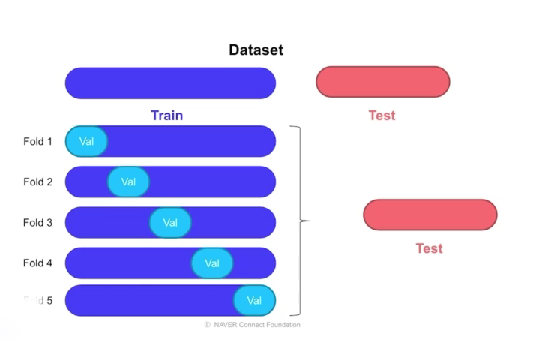 : train, Validation의 쌍을 여러개 구성하는 방법(k-fold 방식)
: train, Validation의 쌍을 여러개 구성하는 방법(k-fold 방식)
랜덤하게 할 수 도 있고 stratified하게 분리할 수 있음
- stratified K-fold
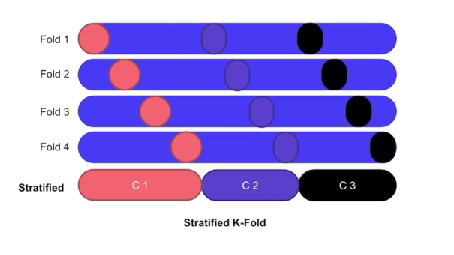
- 레이블이나 카테고리 피처를 기준으로 split한 방식
- 폴드별로 동일한 비율을 맞춤
- 분류문제에서는 보통 비율이 맞아서 성능이 좋기에 권장
- 보통을 8:2
- Group K-fold
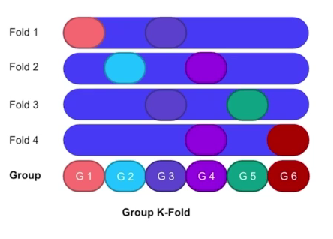
- 그룹들을 하나의 덩어리라고 생각하고 train과 test를 나눌때 뭉쳐있는 구성하는 방식
- 같은 그룹이 폴드안에 들어가지 않도록 하는 방식(그룹의 갯수> 폴드의 갯수)
- Time series split
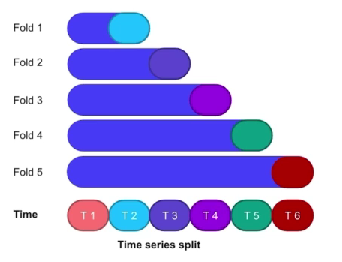
- 시간을 고려해서 Validation구성
- 미래데이터로 과거데이터를 예측하는 일을 방지
- 과거일수록 train데이터가 작아진다는 점을 고려
3. Reproducibility(재현성)
재현성이 필요한 이유??
- Cross Validation
실행할때마다 다르게 샘플링되기 때문에, 실행할때마다 다른 성능이 나온다. 하지만 우리가 반복해서 실행했을 때 동일하게 샘플링되어야 정확한 성능을 평가할 수 있는것 => 재현성 필요 - 머신러닝 모델
랜덤하게 작동되기때문에 작업을 했던 것들을 복원하기 어려움이 있음
랜덤성 제거하기 위한 방법: Fix seed
# 예시
seed = 42
# step 1
os.environ['PYTHONHASHSEED'] = str(seed)
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
# step 2
torch.use_deterministic_algorithms(True)
torch.backends.cudnn.benchmark = False4.Machine learing workflow
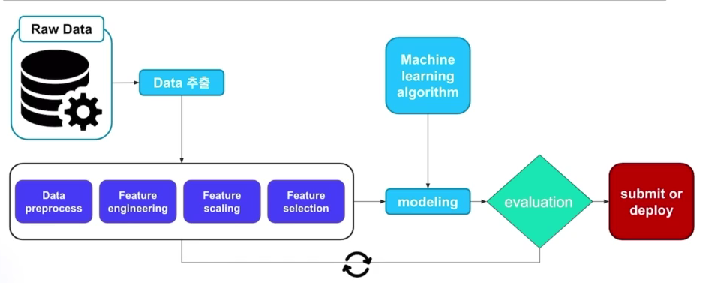
일반적인 머신러닝 모델의 workflow를 간략하게 표현
- 데이터 준비과정이 가장 중요한 단계
