What is tree model
:칼럼값들을 어떤한 기준으로 group을 나누어 목적에 맞는 의사결정을 만드는 방법
- 하나의 질문으로 yes or no을 decision을 내려서 분류
- 일련의 분류기준을 설명한 뒤 데이터를 분류 예측하여 일련의 규칙을 찾는 알고리즘
(스무고개하는 느낌)
트리 모델의 발전

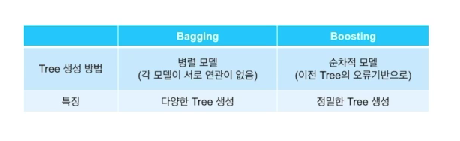
bagging & boosting
여러 개의 decision tree를 이용하여 모델 생성
train을 어떻게 활용하지는에 따라 달라짐
- bagging
- 데이터셋을 샘플링하여 모델을 만들어 나가는것이 특징
- 샘플링한 데이터셋을 하나로 하나의 decision tree가 생성
- 생성한 decision treed의 decision들을 취합하여 하나의 decision 생성
- bagging = bootstrap + aggregation
- bootstrap: data를 여러 번 sampling
- aggregation : 종합
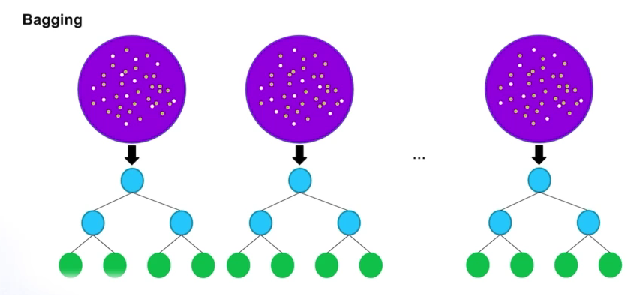
- 보라색 안 흰색이 훈련에 사용하지 않는 데이터들 => 다양한 데이터셋을 만들어 이를 기반으로 트리를 만드는 방식
- boosting
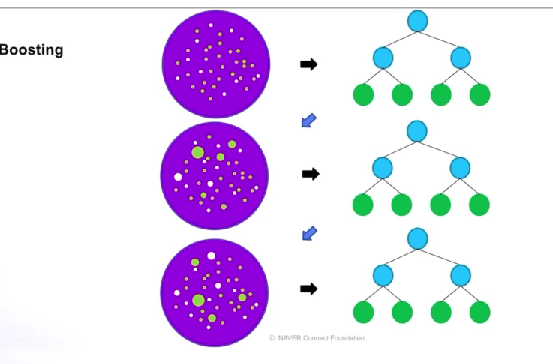
초기에 랜덤하게 선택된 데이터셋으로 하나의 트리를 만들고
잘 맞추지 못한 데이터에게 weight을 부여하여 다음 차례때 잘 맞출 수 있게 하는것
- boosting의 트리모델 종류
- LightGBM(비균형적 구조)
- XGBoost(균형적 구조)
- CatBoost(비균형적 구조)
hyper-parameter 살펴보기
- learning rate
이미지
너무 적게하면 수행속도가 너무 느려지고
너무 크면 발산할 수 있음 - 모델의 깊이와 잎사귀를 제한
제한없이 하다보면 overfitting이 될 수 있음 - column sampling ratio
이미지
회색이 학습에 사용하지 않은 feature (ovefitting 방지) - row sampling ratio
image
회색이 학습에 사용하지 않은 row
parameter 이미지
category 변수 다루기
- LightGBM, CatBoost는 pandas의 category 데이터타입 가능
- object 타입을 category로 변경
- XGBoost은 오직 numeric데이터 타입만 가능 -> 전처리 필요
- 모델 비교
- category 컬럼이 있는 데이터셋으로 세개 모델을 비교했을때
- CatBoost > LightGBM > XGBoost

마루에 미친자