1.앙상블 러닝이란?
1.1 앙상블 러닝의 정의
- 여러개의 결정 트리를 결합하여 하나의 결정 트리보다 더 좋은 성능을 내는 머신러닝기법
- 앙상블 학습의 핵심은 여러 개의 약 분류기를 결합하여 강 분류기 만드는 과정
- 여러 개의 단일 모델들의 평균치를 내거나, 투표를 해서 다수결에 의한 결정을 하는 등 여러 모델들의 집단 지성을 활용하여 더 나은 결과를 도출해 내는 것에 주 목적이 있음
장점
- 성능을 분산시키기 때문에 과적합 감소 효과
- 개별 모델 성능이 잘 안 나올때 앙상블 학습을 이용하여 성능이 향상될 수 있음
1.2 앙상블 러닝의 기법
-
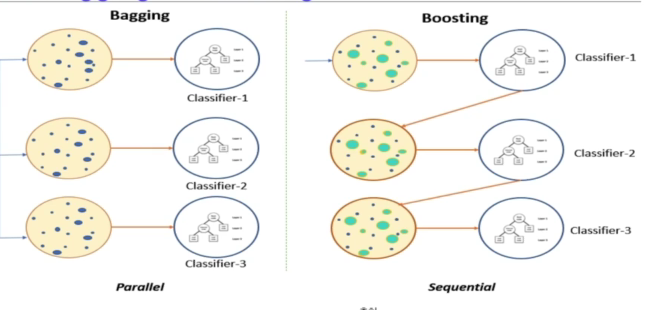
Bagging(Boostrap Aggregation)
- 훈련세트에서 중복을 허용하여 샘플링하는 방식(<->중복허용하지 않은 방식:페이스팅)
- 같은 모델을 사용
- 예) 랜덤포레스트
-
Voting(투표): 투표를 통해 결과 도출
-
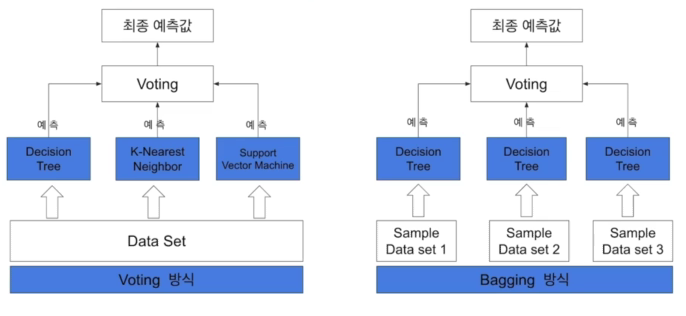
Bagging VS Voting
- Bagging은 같은 알고리즘 내에서 다른 Sample 조합 사용하는 것
- Voting은 다른 알고리즘 model 조합을 사용
-
Voting은 서로 다른 알고리즘이 도출해 낸 결과물에 대하여 최종 투표하는 방식
-
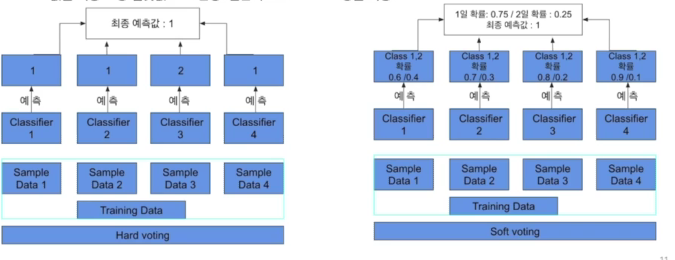
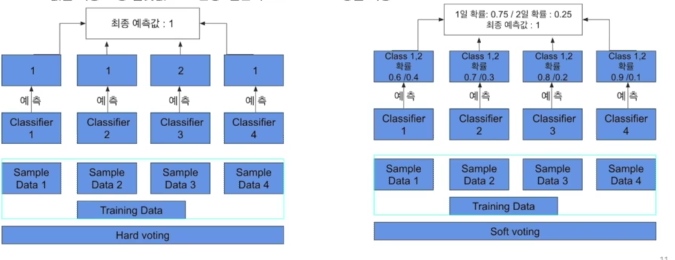
hard vote와 soft vote로 나뉨
- hard voete는 결과물에 대한 최종 값을 투표해서 결정하고(다수결의 원칙),
- soft vote는 분류기들의 레이블 값 결정 확률을 모두 더하고 이를 평균해서 이들 중 확률이 가장 높은 레이블 값을 최종 보팅 결괏값으로 선정.
- soft vote 일반적으로 적용
-
-
Boosting: 이전 오차를 보완하여 가중치 부여
- 여러개의 분류기를 순차적으로 학습하는 방법,
- 이전 분류기가 잘못 예측한 데이터를 잘 예측할 수 있도록 다음 분류기에 가중치를 부여하면서 학습과 예측을 진행
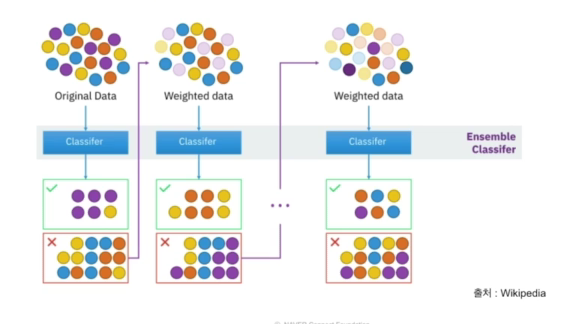
- Bagging보다 성능이 좋지만, Bagging보다 속도가 느리고 오버피팅될 가능성이 높다
-
Stacking: 여러 모델을 기반으로 meta 모델
- 여러 모델들을 활용해 각각의 예측 결과를 도출한 뒤 그 예측 결과를 결합해 최종 예측 결과를 만들어 내는것
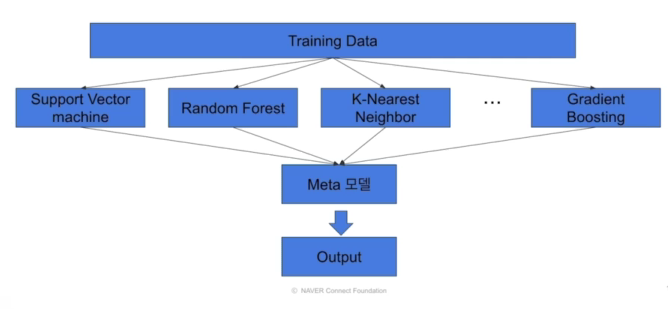
- 여러 모델들을 활용해 각각의 예측 결과를 도출한 뒤 그 예측 결과를 결합해 최종 예측 결과를 만들어 내는것
2. Tree 계열 알고리즘
2.1 Decision Tree:
Impurity
- 해당 노드 안에서 섞여 있는 정도가 높을수록 복잡성이 높고, 덜 섞여있을수록 복합성이 낮다. -> Decision Tree: 복잡성이 낮도록 하는것
- Impurity(복잡성)를 측정하는 측도에는 다양한 종류가 있는데, Entropy, Gini에 대해서만 알아보자!
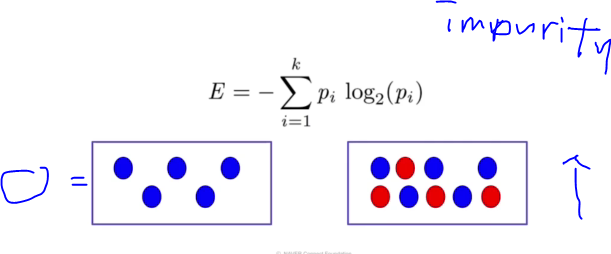
Gini index
- 불순도를 측정하는 지표로서, 데이터의 통계적 분산정도를 정량화해서 표현한 값
- Gini index가 높을수록 분산정도가 높은것
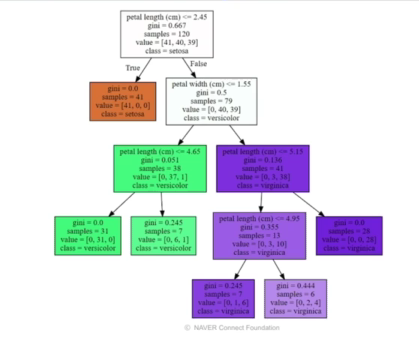 (graphviz 활용)
(graphviz 활용)
2.2 Gradient Boosting
XGboost
- Gradient Boosting + Regularization
- 다양한 Loss function을 지원해 task에 따른 유연한 튜닝이 가능하다는 장점
LightGBM
-
XGboost(level-wise-growth)의 경우 트리의 깊이를 줄이고 균형있게 만들기 위해서 root노드와 가까운 노드를 우선적으로 순횐하여 수평성장하는 방법
-
LightGBM(leaf_wise-growth)의 경우 loss변화가 가장 큰 노드에서 분할하여 성장하는 수직 성장방식
-
XGboost은 학습시간이 느리다점과 하이퍼파라미터가 많다는 단점을 보완
-
LightGBM은 대용량 데이터를 처리하는데 좋으나 데이터가 작으면 오퍼피팅될 가능성이 있음
-
GOSS(Gradient-based One-side Sampling):기울기가 큰 데이터 개체 정보 획득에 있어 더욱 큰 역할을 한다는 아이디어에 입각해 만들어진 테크닉, 작은 기울기를 갖는 데이터 객체들은 일정 확률에 랜덤하게 제거
-
EFB(Exclusive Feature Bunding)
:변수객수를 줄이기 위해 상포배타적인 변수들을 묶는 기법- 일종의 차원축소 기법
- but, 어떤걸 줄이는가?
Catboost
- 순서형 원칙을 제시: Target leakage를 피하는 표준 그래디언트 부스팅 알고리즘을 수정하고 범주형 Feature를 처리하는 새로운 알고리즘
- Random Permutation:데이터를 셔플링하여 뽑아냄
- 범주형 feature 처리방법
- Ordered Target Encoding
- Categorical Feature Combinations
- One-Hot encoding
- Optimized Parameter Tuning (파라미터 튜닝을 크게 신경쓰지 않아도 됨)
3.TaNet
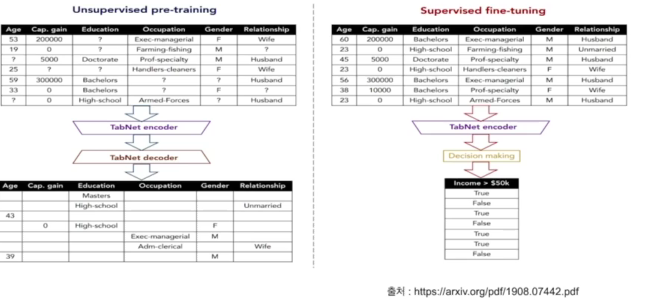
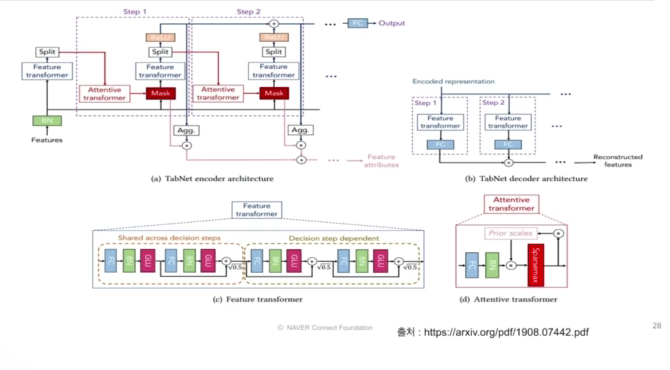
정형데이터를 위한 딥러닝 모델, 순차적인 어텐션을 사용해서 각 의사결정단계에서 추론할 피처를 선택하고 학습능력이 가장 두드러진 기능을 사용되므로 interpretability와 효과적인 학습이 가능하는 장점이 있음
- 전처리 과정을 필요하지 않음
- 정형 데이터에 대해서는 기존의 desicion tree-based gradient boosting(xgboost, lgbm, catboost)와 같은 모델에 비해 신경망 모델은 아직 성능이 안정적이지 못하는데, 두 구조의 장점을 모두 갖는 신경망 모델
- Feature selection, interpretability(local, global)가 가능한 신경망 모델, 설명가능한 모델
- Feature값을 예측하는 Unsupervised pretrain단계를 적용하여 상당한 성능 향상을 보여줌
- 순차적인 어텐션을 사용하여 각 의사 결정단계에서 추론할 특징을 선택하여 학습 능력이 가장 두드러진 특징을 사용
- 기존의 머신러닝 방법에서는 이러한 특징 선택과 모델학습 과정이 나누어져 있지만, TaNet에서는 한번에 가능
- 특징 선택이 이루어지므로 어떠한 특징이 중요한지 설명 가능함