1.feature engineering (1)
: 원본 데이터로부터 도메인 지식 등을 바탕으로 문제를 해결하는데 도움이 되는 feature를 생성, 변환하고 이를 머신 러닝 모델에 적합한 형식으로 변환하는 작업
- 머신러닝 성능의 80% 는 여기 부분에서 결정이 난다
1) pandas group by aggregation을 이용한 feature engineering
- 클래스에 따라 각 (숫자형)컬럼의 분포가 다른지 확인
- 컬럼의 특성을 파악해서 중복컬럼이 있는경우 제외(제거 방법은 8강에서 진행)
'''
입력인자로 받는 year_month와 변수 prev_ym 기준으로 train, test 데이터를 생성 하고
집계(aggregation) 함수를 사용하여 피처 엔지니어링을 하는 함수
'''
def feature_engineering1(df: pd.DataFrame, year_month: str):
df = df.copy()
# year_month 이전 월 계산
d = datetime.datetime.strptime(year_month, "%Y-%m")
prev_ym = d - dateutil.relativedelta.relativedelta(months=1)
prev_ym = prev_ym.strftime('%Y-%m')
# train, test 데이터 선택
train = df[df['order_date'] < prev_ym]
test = df[df['order_date'] < year_month]
# train, test 레이블 데이터 생성
train_label = generate_label(df, prev_ym)[['customer_id','year_month','label']]
test_label = generate_label(df, year_month)[['customer_id','year_month','label']]
# group by aggregation 함수 선언
agg_func = ['mean','max','min','sum','count','std','skew']
all_train_data = pd.DataFrame()
for i, tr_ym in enumerate(train_label['year_month'].unique()):
# group by aggretation 함수로 train 데이터 피처 생성
train_agg = train.loc[train['order_date'] < tr_ym].groupby(['customer_id']).agg(agg_func)
# 멀티 레벨 컬럼을 사용하기 쉽게 1 레벨 컬럼명으로 변경
new_cols = []
for col in train_agg.columns.levels[0]:
for stat in train_agg.columns.levels[1]:
new_cols.append(f'{col}-{stat}')
train_agg.columns = new_cols
train_agg.reset_index(inplace = True)
train_agg['year_month'] = tr_ym
all_train_data = all_train_data.append(train_agg)
all_train_data = train_label.merge(all_train_data, on=['customer_id', 'year_month'], how='left')
features = all_train_data.drop(columns=['customer_id', 'label', 'year_month']).columns
# group by aggretation 함수로 test 데이터 피처 생성
test_agg = test.groupby(['customer_id']).agg(agg_func)
test_agg.columns = new_cols
test_data = test_label.merge(test_agg, on=['customer_id'], how='left')
# train, test 데이터 전처리
x_tr, x_te = feature_preprocessing(all_train_data, test_data, features)
print('x_tr.shape', x_tr.shape, ', x_te.shape', x_te.shape)
return x_tr, x_te, all_train_data['label'], features2)Cross Validation을 이용한 Out Of Fold 예측
모델 Training시 Cross Validation을 적용해서 Out of Fold Validation 성능 측정 및 Test 데이터 예측을 통해 성능 향상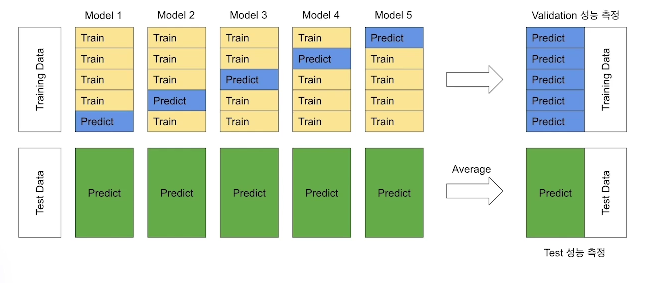
3) LightGBM Early Stopping 적용
-
Early Stopping:
iteration을 통해 반복학습이 가능한 머신러닝모델에서 Validation을 성능 측정을 통해 Validation 성능이 가장 좋은 하이퍼파라미터에서 학습을 조기종류하는 regularization 방법- 예) boosting 트리 모델 트리 개수, 딥러닝의 epoch 수
-
LightGBM Early Stopping
- n_estimatiors: LightGBM에서 몇 개의 트리를 만들지 설정
but, 설정한 트리 개수가 최적의 값이라고 볼 수 없음 - Early Stopping은 Validation을 데이터가 있을시, LightGBM 트리개수인 n_estimatiors는 충분히 크게 설정하고, early_stopping_rounds를 적절한 값으로 설정
- 트리를 추가할때마다 Validation 성능을 측정하고 이 성능이 early_stopping_rounds 값 이상 연속으로 성능이 좋아지지 않으면 더 이상 트리를 만들지 않고 가장 Validation성능이 좋은 트리개수를 최종 트리개수로 사용
- n_estimatiors: LightGBM에서 몇 개의 트리를 만들지 설정
2.feature engineering (2)
pandas group by 누적합을 이용한 feature engineering
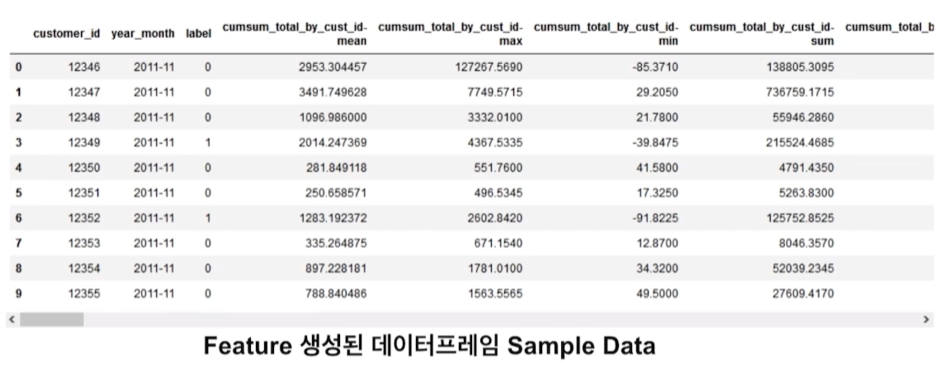
주문, 상품 데이터를 활용한 feature engineering
-order_id, product_id를 이용하여 피쳐 생성
Time Series특성을 이용한 feature engineering
-month, year를 이용하여 피쳐 생성 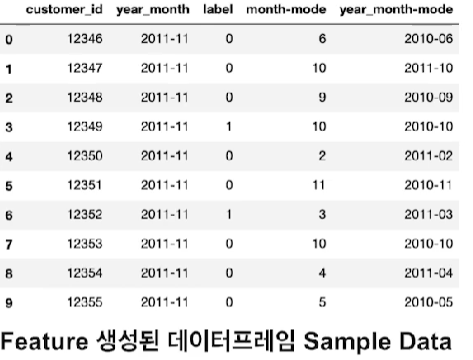
3.피처 중요도와 피처 선택
피처 중요도란?
타겟 변수를 예측하는 데 얼마나 유용한 지에 따라 피처에 점수를 할당해서 중요도를 측정하는 방법
Model-specific vs Model-agnostic
- 머신러닝 모델 자체에서 피처 중요도 계산이 가능하다면 전자
- 모델에서 제공하는 기능에 의존하지 않고 모델을 학습한 후에 적용되는 피처 중요도 계산방법은 후자
Model-specific
- LightGBM 피처 중요도 함수
- Trining된 LightGBM 모델 클래스에 feature_importance(importance_type)함수로 피처 중요도 계산 기능 제공
- importance_type 값에는 split(디폴트), gain 있음
- split:트리를 만드는데 피처가 몇번이나 사용됐느냐 -> 많이 사용할수록 중요하다
- gain:피처를 사용해서 split해서 그 gain을 얻는데 얼마나 gain값이 나오는지 계산하는 방식
- XGBoost 피처 중요도 함수
- Trining된 XGBoost 모델 클래스에 get_score(importance_type)함수로 피처 중요도 계산 기능 제공
- importance_type 값에는 weight(디폴트) 있음
- weight = LightGBM의 split
- gain = LightGBM의 gain
- cover
- total_gain

- CatBoost 피처 중요도 함수
- Trining된 CatBoost 모델 클래스에 get_feature_importance(type)함수로 피처 중요도 계산 기능 제공
- FeatureImportance가 디폴트!

3.Permutation 피처중요도란?
- Model-agnostic 한 방법
- 피처에 있는 값들을 랜덤하게 셔플링한 후 모델의 에러를 측정해서
만약에 피처가 중요하다면 피처의 값들을 섞어버리면 모델의 에러가 커질 것
만약에 중요하지 않다면 성능 측정하면 에러가 작은 경우 - 최근에 많이 사용하는 방법(실제에도 많이 쓰임)
- 의사코드
input: Trained model, feature matrix, target vector, error measure
1.원본 데이터, 기존 모델로 loss 함수로 에러를 계산
2.피처 하나씩 루프를 들면서, 피처 하나씩 데이터를 랜덤 셔플링한 다음 에러를 구함
3.기존 에러와 비교
4.에러 차가 큰 순서대로 sorting
피처 선택
- 머신러닝모델에서 사용할 피처를 선택하는 과정
- 머신러닝 모델에서 타켓 변수를 예측하는데 유용한 피처와 유용하지 않은 피처를 구분해서 유용한 피처를 선택하는 과정
- 피처 선택을 통해 모델의 복잡도를 낮춤으로써 오버피팅 방지 및 모델의 속도 향상 가능
- 피처 선택방법
- Filter Method: 통계적인 방법을 이용해 피처들의 상관계수를 이용한 방법
- 계산속도가 빠르고 피처들간의 상관관계를 알 수 있기에 Wrapper Method전 전처리 과정에서 진행
- 방식1: 피처들간의 correlation을 계산해서 correlation이 굉장히 높은 피처들은 같은 피처로 봐도 되기때문에 둘 중에 하나 제거
- variance threshold(방식2): 피처의 데이터 분산(얼마나 퍼져있는가)을 계산
- 분산이 작다면 값이 차이가 거의 없다는 얘기
- 분산이 작은것은 훈련에 사용하지 않음
- Wrapper Method: 예측모델을 사용해서 피처의 subset를 계속 테스트
- 기존 데이터에서 성능을 측정할 수 있는 hold-out 데이터를 따로 구축하여 valitation을 측정할 수 있는 방법이 필요 -> 계속 체크해서 어떤 피처를 중요한지 파악
- Embedd Method: Filter Method + Wrapper Method
- 학습 모델 자체에서 fetuer selection 기능에 들어가 있는 방식
- Filter Method: 통계적인 방법을 이용해 피처들의 상관계수를 이용한 방법

마루에 미친자