최적화의 주요 용어 이해하기
introduction
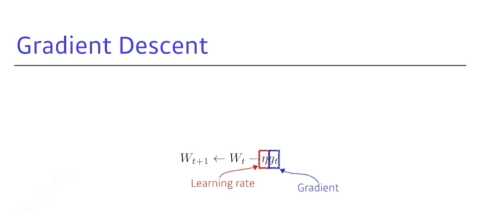
Gradient descent
로컬 미디엄을 찾기위해 1차 미분을 반복적으로 최적화하는 알고리즘
improtant Concepts
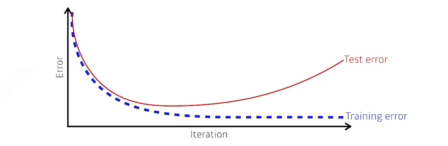
일반화 성능을 높이는게 목표임 그렇다면 일반화는 뭘까?
generalization:training error와 test erorr 차이와 관련
- 일반적으로 일반화가 좋다는것은 test가 train만큼 좋게 나온다
Underfitting VS Overfitting
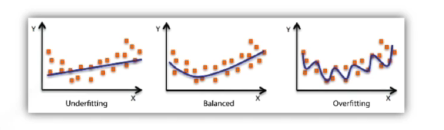
- Overfitting: 학습데이터는 다 맞추고 있는데, 네트워크가 이상해
- Underfitting: 네트워크가 너무 단순하거나 훈련을 많이 안해서 학습데이터도 잘 못 맞춤
Cross-validation(K-hold validation)
- 학습 데이터와 test(valid)데이터를 K개로 나눠서, K-1개를 학습하고 1개로 validation함
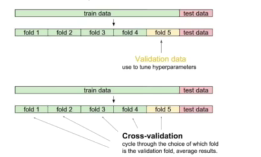
- Cross-validation을 통해 최적의 하이퍼파라미터를 찾고 학습시킬 때는 모든 학습데이터 사용
- test 데이터는 어느 방법으로도 사용해서는 안된다.
Bias and Variance
- Variance: 출력이 얼마나 일관적인가?
- Bias: 내가 원하는 값과 얼마나 차이가 있는가?
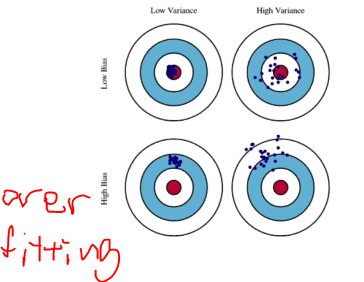
- bias는 줄이게 되면 Variance가 높아질 가능성이 크고, Variance를 줄이게 되면 bias가 높아질 가능성이 높다

Boostrapping
- 학습데이터가 고정되어 있을때 subsampling을 통해서 모델을 여러개 만들고 이를 활용하겠다
- 예를 들어 학습데이터가 100개가 있을 때 그 중 80개씩 뽑아서 모델을 만들고, 그렇게 모델을 여러개 만듬 -> 각 모델을 예측하는 값들이 얼마나 일치하는지 보고 전체적인 모델의 불일치를 예측하고자 할때 활용
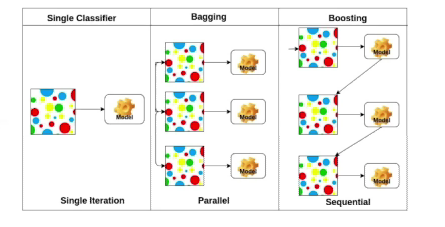
Bagging VS Boosting
- Bagging: Boostrapping을 활용하여 여러개의 모델을 학습시키고 모델들의 출력값을 평균을 내겠다(앙상블)
- Boosting: 학습데이터를 100개가 있으면 간단한 모델을 만들어 학습시키고 두번째 모델을 만들때 잘 예측하지 못한 데이터에 대해서만 잘 동작하게 만드는것 -> 여러개의 모델을 만들어서 하나로 합치는것
Gradient Descent Methods
- stochastic Gradient descent: 10만개 중 한개를 구해서 진행해서 업데이트하고 그 다음에도 한개만 활용해서 업데이트
- Mini-batch Gradient descent: 128개(256개)를 한개를 보고 학습을 진행(일반적으로 사용)
- batch Gradient descent: 한번에 모든 학습데이터를 활용하는것
Batch-size Matters
Large batch를 활용하면 sharpe minizer에 도달, small batch를 활용하면 flat minizer에 도달
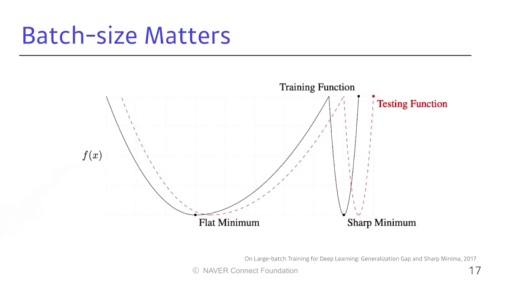
- flat minimum은 generalization이 높음 반면, sharpe minizer은 낮음
- 그러므로 Large batch를 활용하면 좋음
- Gradient descent
- learning rate, stepsize 찾는게 너무 어려움
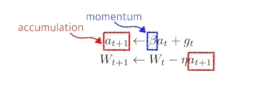
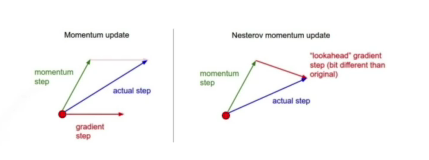
- Momentum
- 한번 흘러간 Gradiention 유지하기 때문에 그래디언트가 왔다갔다해서 잘 학습시킴
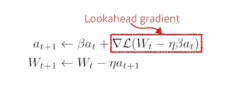
- Nesterov Accelerate
- 한번 이동후 그래디언트 계산하고 accumulation함
- Momentum보다 local minimum에 더 빠르게 도달
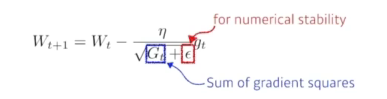
- Adagrad
(1):지금까지 얼마나 파라미터가 변했는지를 제곱해서 더한 값
- 역수에 있기 때문에 많이 변했으면 좀 적게, 적게 변했으면 많이 변화를 줌
- (1)이 점점 무한대로 가면서 뒤로 갈수록 학습이 잘안됨
- Adadelta
- 학습률이 없기 때문에 잘 활용하지 않음
- RMsprop
- 학습이 잘되서 많이 활용했었음
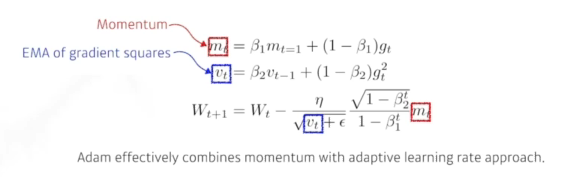
- Adam
그래디언트 크기가 따라서 adative하게 학습률을 변화하는 것 + Momentum을 같이 활용함

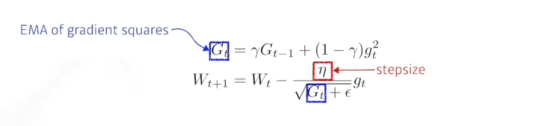

마루에 미친자