Sequential Models - RNN
Sequential Model
- Sequential data: 말, 음성, 영상, 모션..등
- 어려운 점: 얻고 싶은것은 하나의 라벨, 정보인데 받아드려야 하는 차원(몇 개의 음절,음성) 을 알 수 없음
- 가장 기본적인 Sequential Model여러 입력 데이터가 들어왔을 때, 다음번 입력에 대한 예측
- 과거에 고려해야하는 데이터의 양이 점점 늘어남
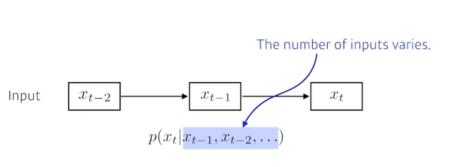
- 위 문제를 해결하기 위해서 -> 과거의 데이터 r개만 보겠다
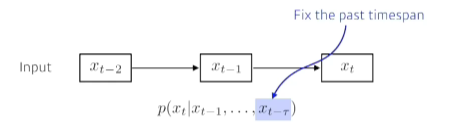
- Markov model: 내가 가정을 하기에 나의 현재에만 과거에만(바로 전 과거) 고려하겠다
- 많은 정보를 버리게 되는 단점이 있다.
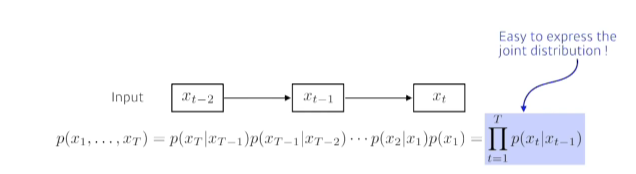
- Latent autoregressive model: 중간에 히든스테이트가 들어있어서 이게 과거의 정보를 요약해줌
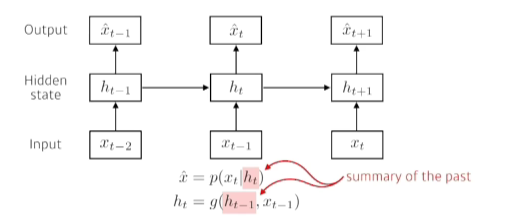
- 과거에 고려해야하는 데이터의 양이 점점 늘어남
Recurrent Neural Network
- 앞에서 봤던 NLP와 똑같은데 차이점이 있다면 자기자신으로 돌아오는 구조가 하나 있는것
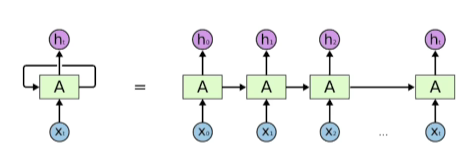
- 시간순으로 푼다라고 표현:현재 입력과 이전의 입력이 Recurrent하게 들어옴
-> 타입스탭 t에서 보고있는건 t-1에서 전달된 정보 - short-term dependencies은 잘 이행하나 Long-term dependencies은 그렇지 않다
- why? 과거에 얻어진 정보들이 다 취합되어 미래에 그걸 고려해야하는데, RNN 자체는 어떠한 하나의 fix rule로 정보들을 계속 취합하기 때문에 이전 먼 과거에 있던 정보가 미래까지 남아있는게 어렵다
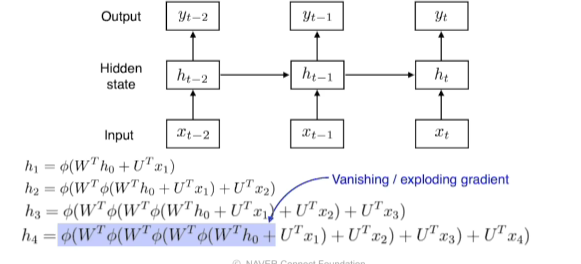
- if 활성함수가 sigmoid라면, sigmoid는 정보를 축소시키는 성질이 있기에 H0 정보를 단계를 거쳐갈수록 학습이 안되지만 Relu는 반대로 H0을 계속 곱해주기 때문에 네트워크가 폭발하여 학습이 안됨
- why? 과거에 얻어진 정보들이 다 취합되어 미래에 그걸 고려해야하는데, RNN 자체는 어떠한 하나의 fix rule로 정보들을 계속 취합하기 때문에 이전 먼 과거에 있던 정보가 미래까지 남아있는게 어렵다
- 기본 바닐라 RNN
Long Short Term Memory
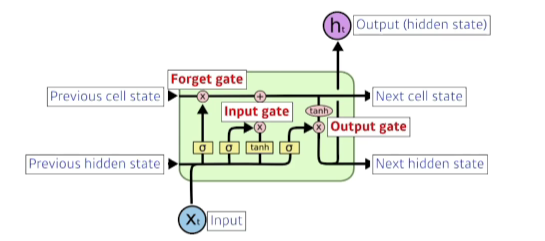
- previous cell state: 내부에서만 흘러가고 h0~ht까지 들어온 정보를 취합해서 요약해줌
- previous hidden state(=previous output)
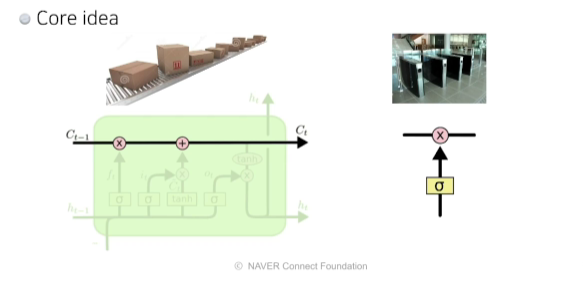
- 핵심 idea: cell state(정보 취합및 요약)
- 게이트는 어떤 정보를 취합하고 버릴지를 정하는 문의 역할
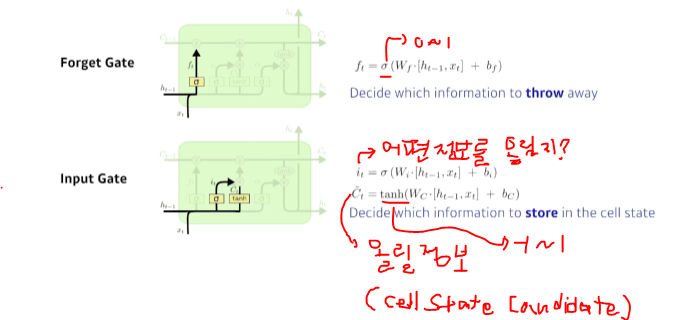
- 게이트는 어떤 정보를 취합하고 버릴지를 정하는 문의 역할
- Forget Gate: 이전에 들어온 정보 중에서 버릴 것을 정하는 역할!
- Input Gate: 현재 입력 중 어떤 정보를 올릴지 말지를 정하는 역할
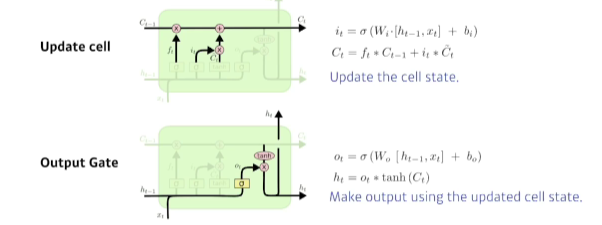
- Update Gate: Forget Gate와 Input Gate에 나온 결과를 취합하여 새로운 cell에 업데이트하는 것
- Output Gate: 어떤 정보를 밖으로 내보낼지?
Gated Recurrent Unit
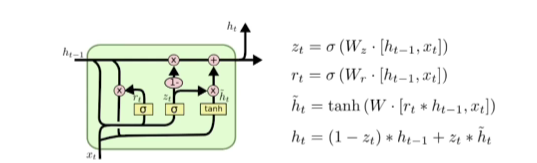
- reset gate, update gate(ouput gate없이 그대로 결과)만으로 LSTM과 비슷한 역할을 하게 됨
Sequential Models - Transformer
Transformer은 기본적으로 Sequential data에서 활용
Sequential Model
- 왜 Sequential Model이 어려울까?
- 예를 들어, 문장은 길이가 정해지지 않고, 혹은 중간에 단어가 빠질수도 있고 순서가 바뀌거난 중간에 밀리는 등의 문제가 있음
- 이러한 문제는 순차적으로 들어가야 하는 Sequential Model에 문제가 됨
- 이런 문제를 해결하기 위해 Transformer 사용
Transformer
- 가장 큰 특징으로 어탠션으로 활용함
- Sequential data 뿐만 아니라 이미지 분류, 이미지 Detection 등 다양한 분야에서 활용
- Sequence to Sequence model: 어떤 Sequence이 주어지면 다른 Sequence로 바꿈
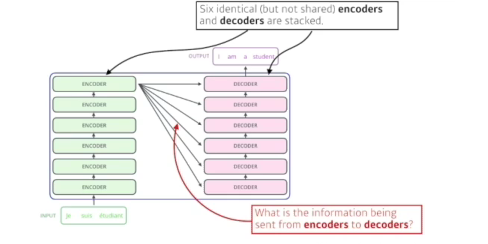
- 입력 시퀀스(3개)와 출력 시퀀스(4개)의 단어개수가 다를수도 있고, 도메인이 다를 수 있구나
- 파라미터가 다른 6개의 인코더와 디코더가 stack되어 있다.
- 인코더가 N개의 단어를 어떻게 한번에 처리할 수 있는지(N은 변할 수 있다)
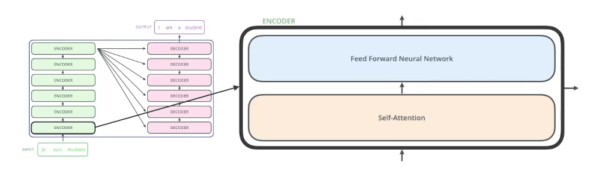
- self-attention(중요)
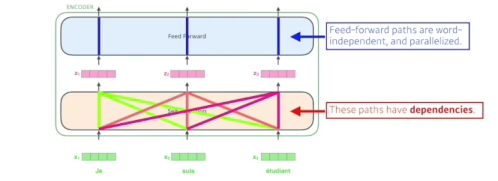
- 3개의 단어를 주어지면, 3개의 벡터로 바꿔줌
- x1의 정보가 z1으로 넘어갈때 단순히 x1만 활용하는게 아니라 x2,x3모두 활용(dependencies가 있음, 반면에 FF은 없음)
-> x1가 어떤 의미인지만 중요한게 아니라 다른 단어와 어떤 인터랙션이 있는지가 중요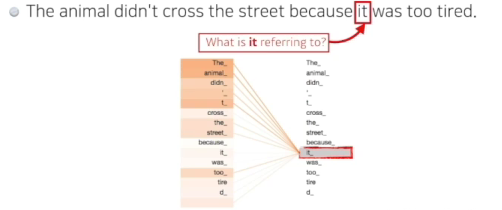
- it이 animal가 깊은 관계가 있구나!
1) 하나의 단어가 주어졌을때 일반적으로 3개의 벡터(queries, keys, value)를 만들게 됨
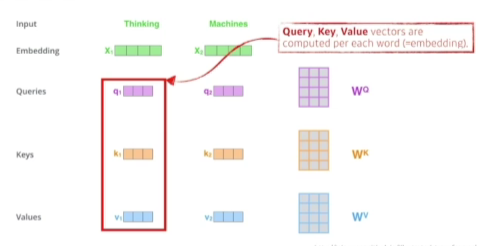
- queries, keys의 차원은 같아야함(내적해야 하기 때문에)
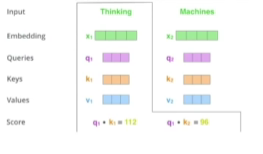
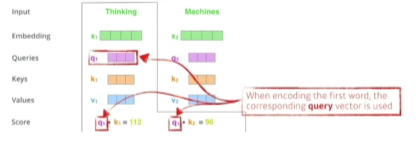
- score 벡터: 내가 인코딩을 하고자 하는 query 벡터와 나머지 모든 N개 단어의 key 벡터를 내적 -> 이 두 벡터가 얼마나 align이 잘 되어있는지를 보고 얼마나 유사도가 있는지, 관계가 있는지!
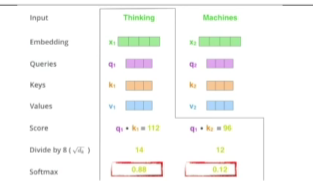
2) 그 다음은 normalize해줌 : 8로 나눠줌(key vector의 demension에 dependency)
3) softmax 취해줌
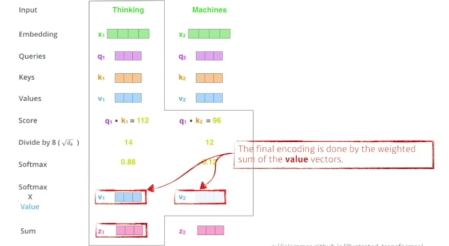
4) 최종적으로 나오는 것은 위에 구한 값과 나머지 모든 단어의 value 벡터와 weighted sum을 해준 벡터
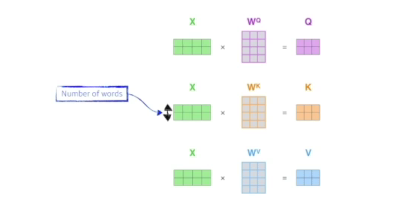
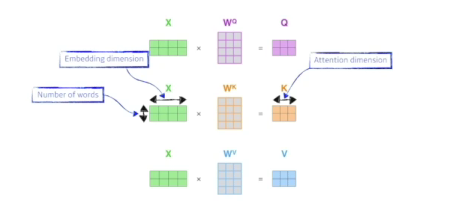
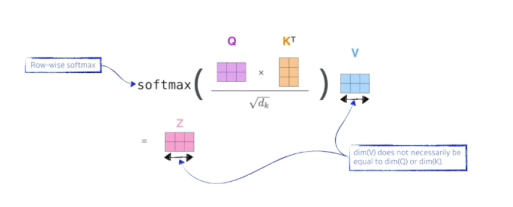
- 이게 왜 잘될까? 입력이 고정되더라도 옆에 있는 단어가 달라지면 출력이 달라질 여지가 있고 더 많은 것을 표현할 수 있음=> 훨씬더 플렉서블하고 더 많은 computation이 필요함
- tramsformer: N개의 단어가 주어지면 N x N attention map 을 만들어야 함(한번에 처리) -> 메모리가 많이 먹음
- RNN은 1000번을 돌리면 됨
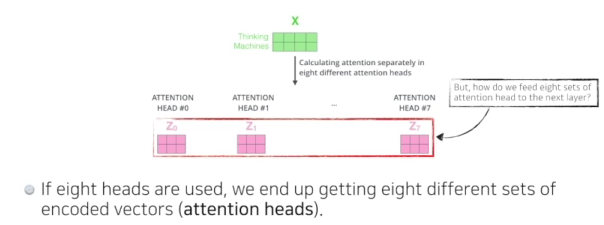
- Muti-headed attention을 하는건 위에 있는 과정을 여러번하는 것
- 하나의 단어(임베딩된 벡터)에 되어서 N개의 queries, keys, value 벡터를 만드는것
- N개의 인코된 벡터가 나옴
- but, 임베딩벡터와 인코드되어서 셀프어텐션에서 나온 벡터가 같은 차원이어야 함
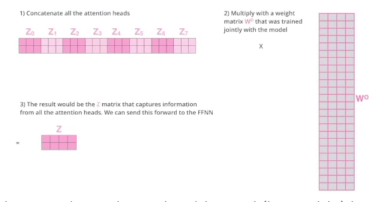
- 다 더하고 나서 원래 사이즈를 줄여줌(구현이랑은 조금 다르다)
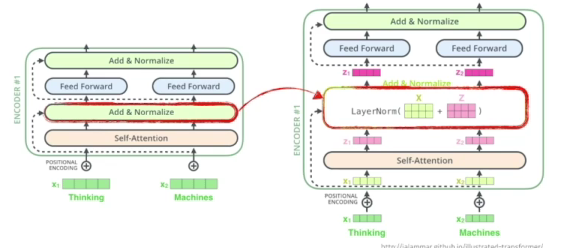
- positional encoding: 입력의 값의 특정 값(bias)를 더해주는 것
- 왜 필요할까? N개의 단어를 순차적으로 나왔다고 치지만 Sequential한 정보가 이 안에 포함되어있지 않는다. ex) a,b,c,d// b,c,d,a// d,a,c,b => 각각의 a,b,c,d의 인코드된 값을 달라질 수 없다.(order에 independent함)
- 왜 필요할까? N개의 단어를 순차적으로 나왔다고 치지만 Sequential한 정보가 이 안에 포함되어있지 않는다. ex) a,b,c,d// b,c,d,a// d,a,c,b => 각각의 a,b,c,d의 인코드된 값을 달라질 수 없다.(order에 independent함)
디코더
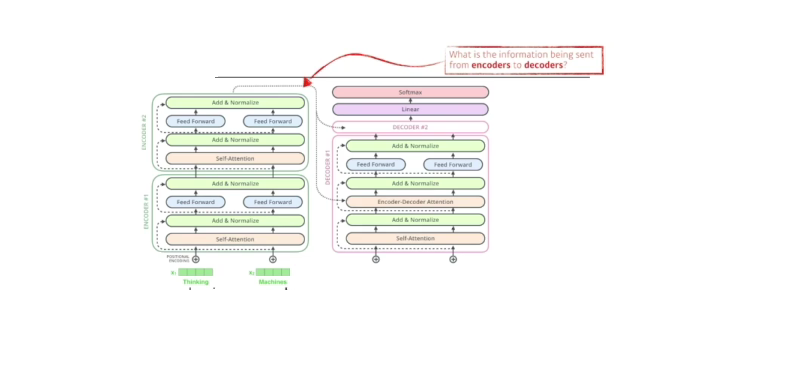
- 인코더에서 디코더로 어떤 정보가 전해질까? key와 value를 보냄
- 출력은 하나의 단어씩 만들게 됨
- 학습할때는 모든 단어를 알고 있으면 학습하는 의미가 없기 때문에 마스킹 단계을 거침
- 이전 단어들만 dependent하고 뒤에 있는 단어에 대해서 independent->미래 정보를 사용하지 않겠다.
- Encoder-Decoder Attention: Encoder와 Decoder의 관계
- 디코더에 들어온 단어들만 가지고 쿼리를 만들고 key와 value는 input 인코디드 벡터를 활용한다.
- 최종적으로 단어 분포를 만들어서 그것들의 단어 하나 샘플링하는 식으로 돌아감
- 이미지 도메인에도 많이 쓰임
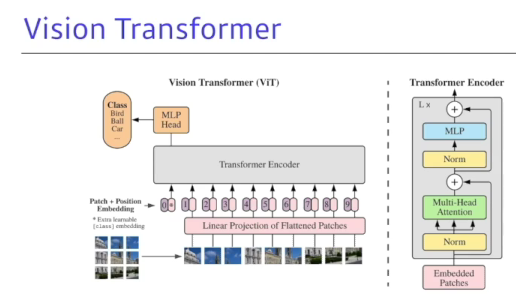
[참고]파이토치로 시작하는 딥러닝 기초
Lab-11-0 RNN intro
- RNN: 데이터의 순서도 중요한 의미를 가지는 데이터
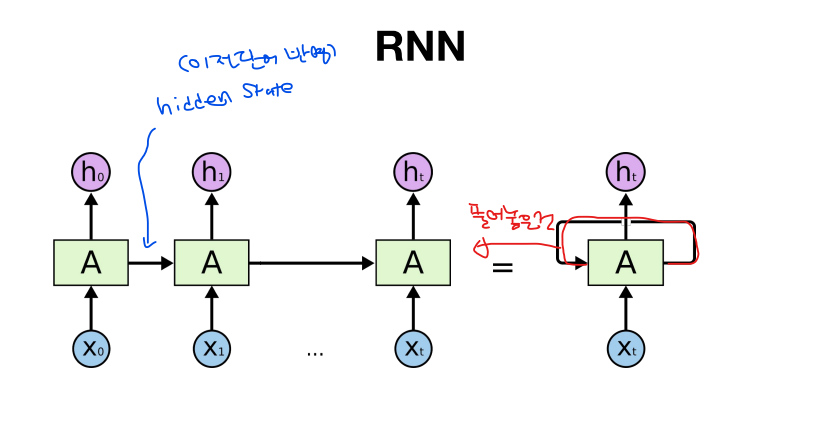
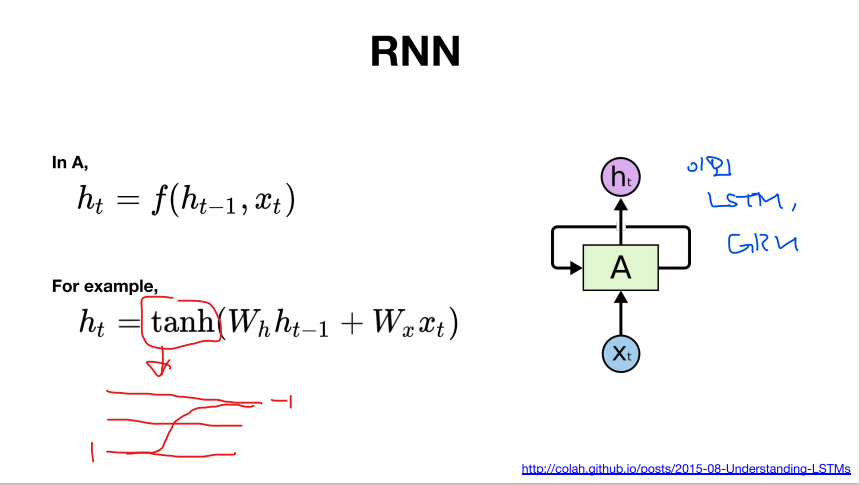
- 셀A의 파라미터들은 학습의 대상이기때문에 구조가 복잡하면 복잡해질수록 학습되는 정도가 감소
- 복잡한 셀을 쓰면 같은 수준의 학습은 좋은 수준이겠지만 그 학습 수준을 내기까지 많은 자원이 필요하다
- 셀의 복잡도는 RNN<GRU< LSTM
Lstm설명블로그
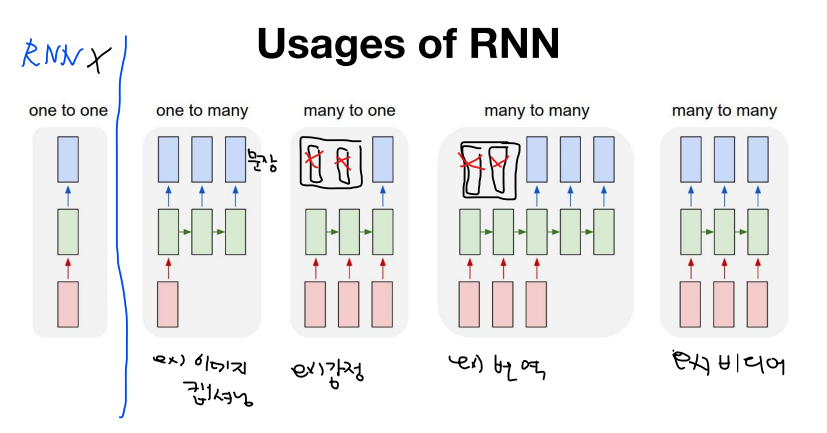
lec12: NN의 꽃 RNN 이야기(모두를 위한 딥러닝 강좌 시즌1)
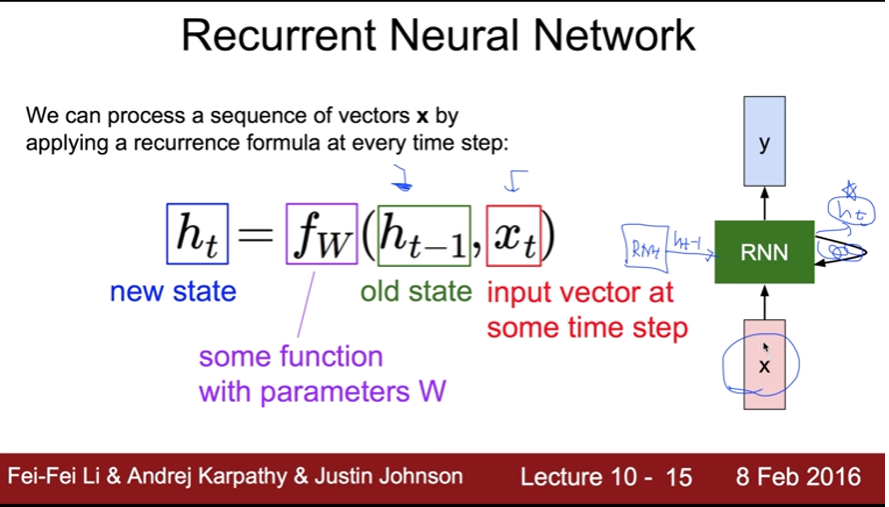

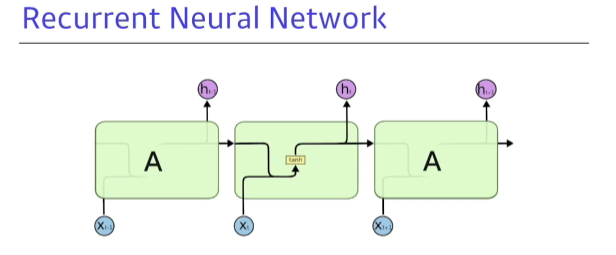
- 각 단계의 계산하는 함수가 모두 같다!
- 각 단계의 W_hh,W_xh, W_hy 가중치가 같다
-> 그래서 위의 그림처럼 표시하는 것
- Language Model
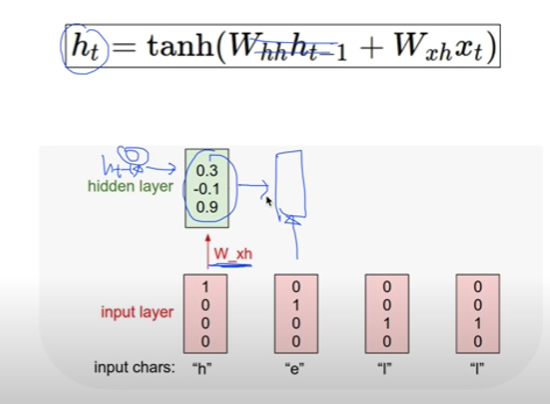
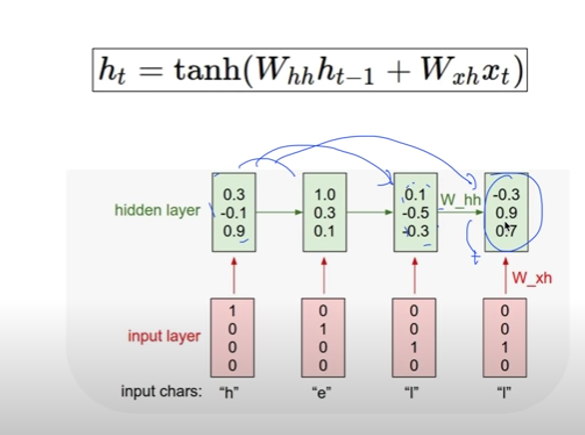
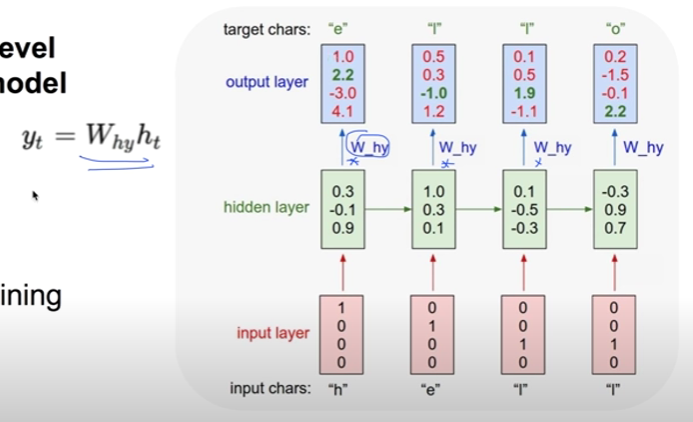
Lab-11-1 RNN basics
RNN
# 셀 A을 선언하는 과정
rnn = torch.nn.RNN(input_size, hidden_size)
# 셀 A에 인풋데이터를 넣어 결과를 추출하는 과정
outputs, _status = rnn(input_data) ## 3개의 차원을 가지고 텐서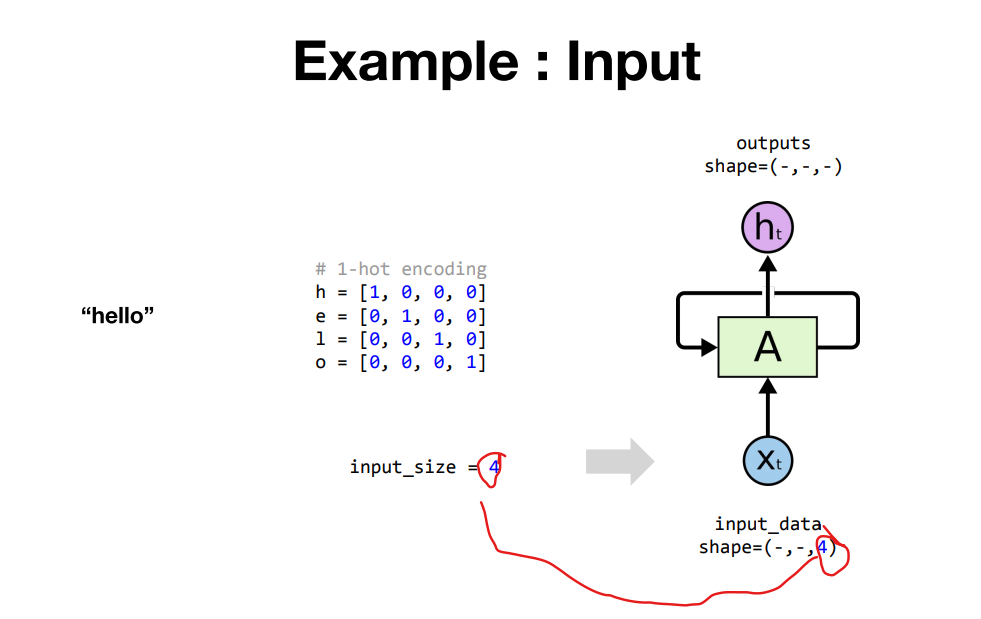
- embedding 벡터를 만든 경우에는 그 벡터의 차원이 인풋 사이즈가 됨
- 미리 셀A 에게 알려주기 위해 사전에 선언
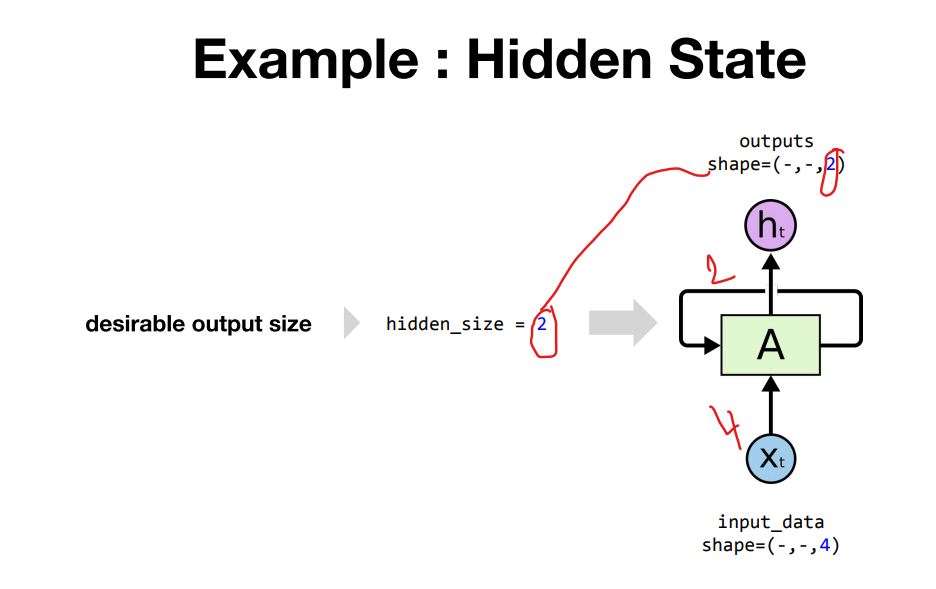
- hidden size를 정의했는데 어떻게 output 사이즈를 정의하냐?
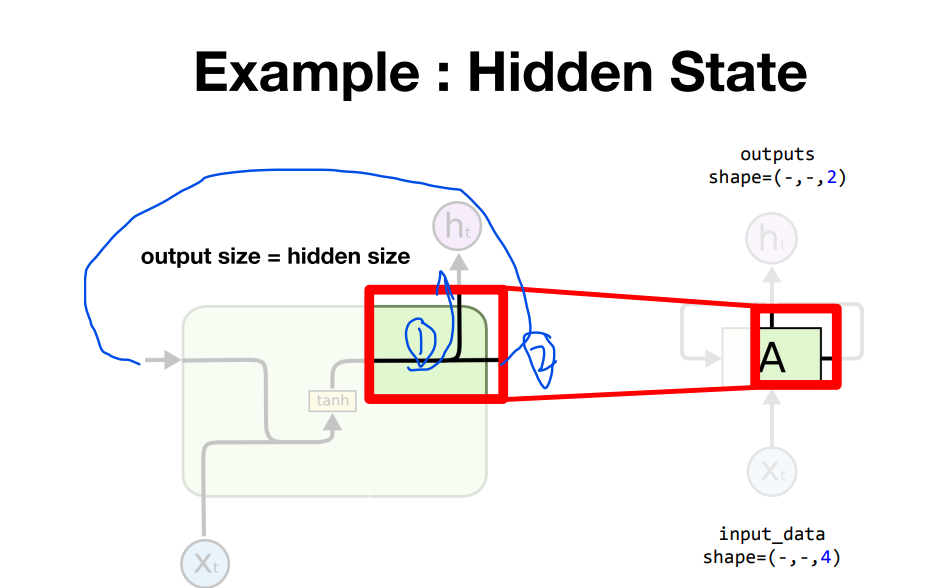
- 동일하게 1,2에 나가기 때문이다!
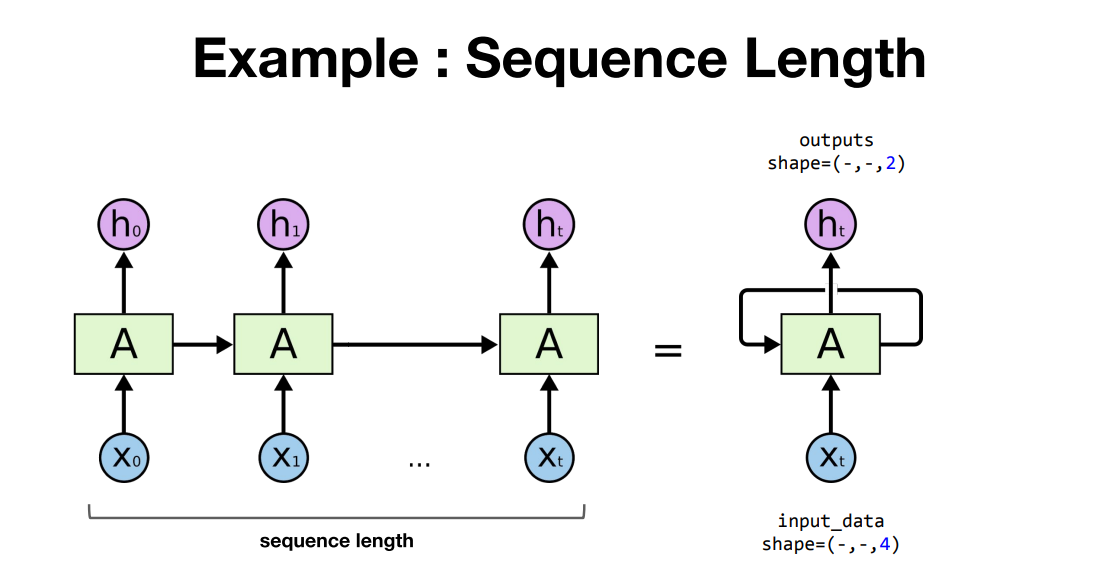
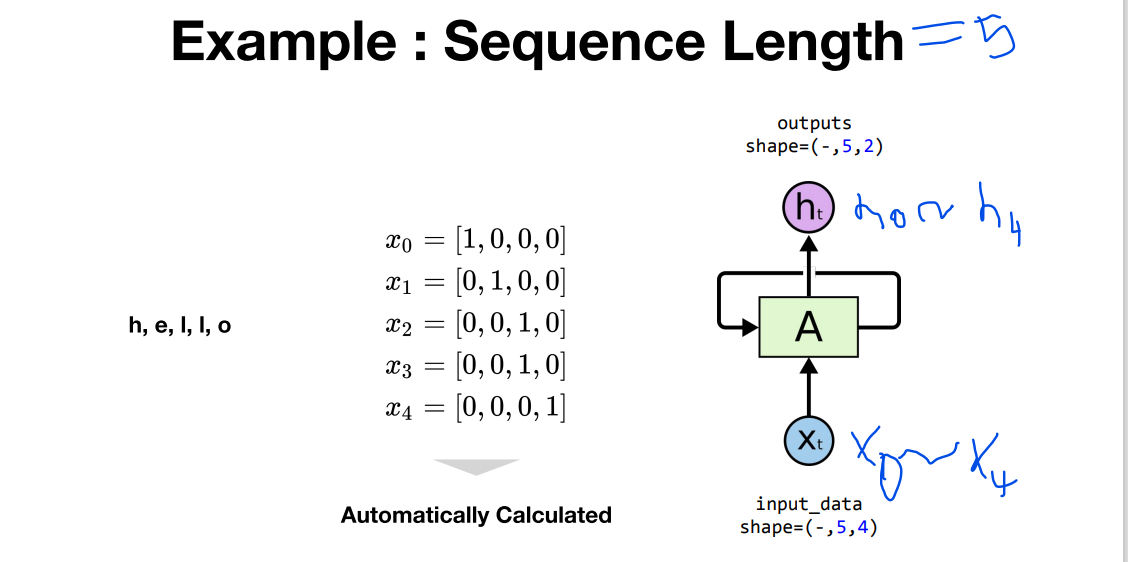
- 시퀀스 길이를 알려주지 않아도 파이토치가 자동으로 인식함
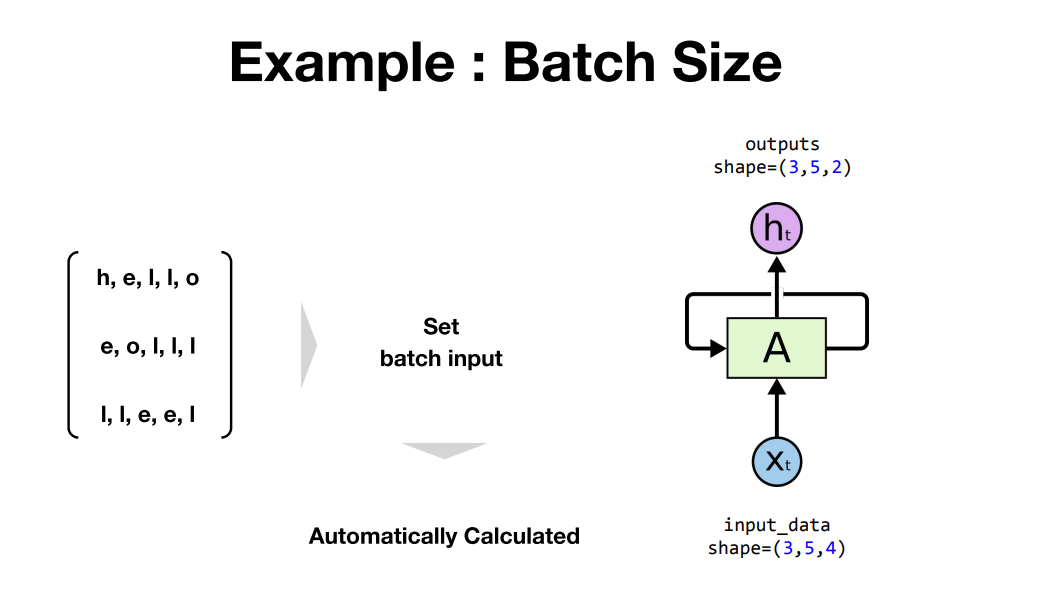
- 배치 사이즈도 알려주지 않아도 파이토치가 자동으로 인식함
import torch
import numpy as np
input_size = 4
hidden_size = 2
######### 인풋데이터를 텐서로 변환하는 과정
# 1-hot encoding
h = [1, 0, 0, 0]
e = [0, 1, 0, 0]
l = [0, 0, 1, 0]
o = [0, 0, 0, 1]
# batch:3, length:5
input_data_np = np.array([[h, e, l, l, o],
[e, o, l, l, l],
[l, l, e, e, l]], dtype=np.float32)
# transform as torch tensor
input_data = torch.Tensor(input_data_np) #넘파이로 만든 텐서를 토치에서 사용하는 텐서로 바꿔주는 것
#########
rnn = torch.nn.RNN(input_size, hidden_size)
outputs, _status = rnn(input_data) # (3,5,2) shapeLab-11-2 RNN hihello and charseq
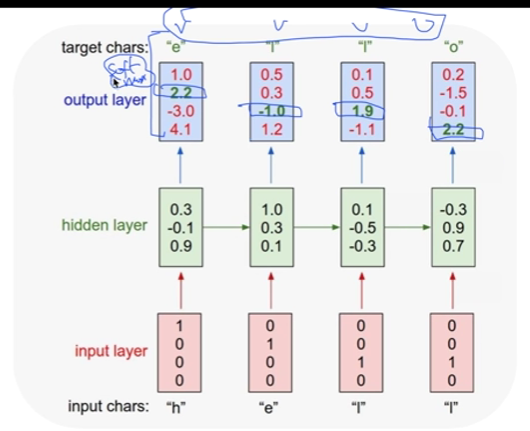
hihello 예측하기

- x data와 x_one_hot 마지막 5번째(o)는 없는 이유?
- 다음문자를 예측하는 모델이기에 h,i,h,e,l,l 은 인풋으로 사용
i,h,e,l,l,o은 y의 아웃풋으로 사용
- 다음문자를 예측하는 모델이기에 h,i,h,e,l,l 은 인풋으로 사용

# loss & optimizer setting
criterion = torch.nn.CrossEntropyLoss()
…
loss = criterion(outputs.view(-1, input_size), Y.view(-1)) # 인수: 아웃풋 ,정답레이블- hihello version
har_set = ['h', 'i', 'e', 'l', 'o']
# hyper parameters
input_size = len(char_set)
hidden_size = len(char_set) # 인풋 사이즈와 상관없음
learning_rate = 0.1
# data setting
x_data = [[0, 1, 0, 2, 3, 3]]
x_one_hot = [[[1, 0, 0, 0, 0],
[0, 1, 0, 0, 0],
[1, 0, 0, 0, 0],
[0, 0, 1, 0, 0],
[0, 0, 0, 1, 0],
[0, 0, 0, 1, 0]]]
y_data = [[1, 0, 2, 3, 3, 4]]
# transform as torch tensor variable
X = torch.FloatTensor(x_one_hot)
Y = torch.LongTensor(y_data)
- 일반화된 버전
sample = " if you want you"
# make dictionary
char_set = list(set(sample)) # unique한 문자열만!
char_dic = {c: i for i, c in enumerate(char_set)}
# hyper parameters
dic_size = len(char_dic)
hidden_size = len(char_dic)
learning_rate = 0.1
# data setting
sample_idx = [char_dic[c] for c in sample]
x_data = [sample_idx[:-1]]
x_one_hot = [np.eye(dic_size)[x] for x in x_data]
y_data = [sample_idx[1:]]
# transform as torch tensor variable
X = torch.FloatTensor(x_one_hot)
Y = torch.LongTensor(y_data# declare RNN
rnn = torch.nn.RNN(input_size, hidden_size, batch_first=True) # batch_first=True -> batch_first guarantees the order of output = (B, S, F)
# loss & optimizer setting
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.Adam(rnn.parameters(), learning_rate)
# start training
for i in range(100):
optimizer.zero_grad() # 매 스텝마다 새로운 그래디언트를 할 수 있음(하지 않으면 기존에 구했던 그래디언트에 축적이 됨)
outputs, _status = rnn(X)
loss = criterion(outputs.view(-1, input_size), Y.view(-1))
loss.backward() #백프로파겐 실행
optimizer.step() # optimizer의 파라미터가 업데이트 됨
# 모델이 실제로 어떻게 예측했는지를 알아보는 코드
result = outputs.data.numpy().argmax(axis=2) #argmax: 인덱스가 2인 디멘션에서 가장 큰 숫자를 가져오는것
result_str = ''.join([char_set[c] for c in np.squeeze(result)]) # squeeze:디멘션에서 1인 축을 없애줌
print(i, "loss: ", loss.item(), "prediction: ", result, "true Y: ", y_data, "prediction str: ", result_str)
마루에 미친자