Computer Vision Applications
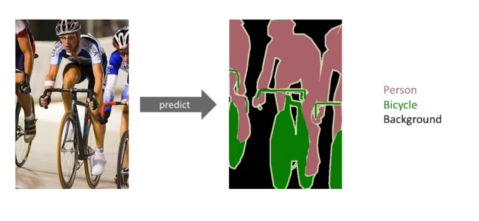
Semantic Segmentation
- 어떤 이미지가 있을때, 각 픽셀마다 분류를 하는것
- 활용 예시: 자율주행, 운전보조장치
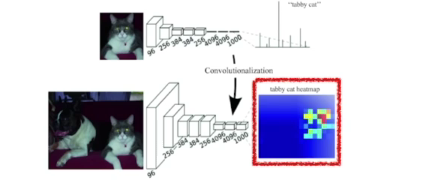
Fully convolutional Network
- 기본적인 CNN구조: 이미지 하나가 들어오면 어떠한 과정을 걸치고 마지막에 dense layer를 통과시켜 1000개짜기 아웃풋을 생성
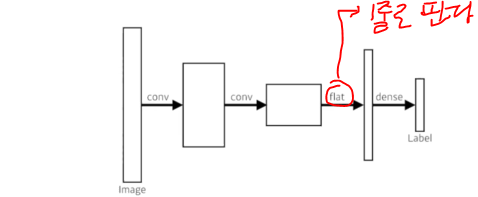
- flat -> 20 x 20 x 1000 => 400000개로 만듬
- Fully convolutional Network은 dense layer을 없애는 것(convolutionalization)
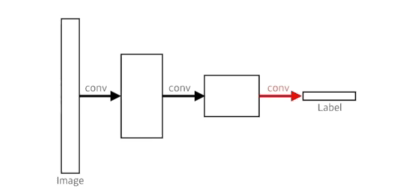

- 기존 CNN과 Fully convolutional Network의 인풋과 아웃풋이 동일함 =>파라미터가 정확히 일치
- why? 20 x 20 x 1000짜리 필터를 만들어서 1 X 1 X 1000개 짜리 피처맵을 만듬
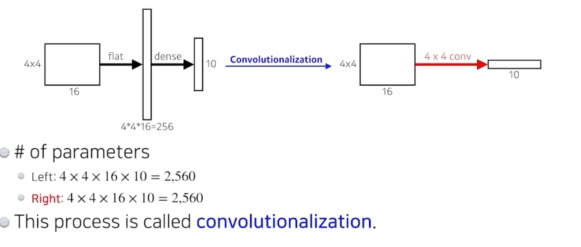
- why? 20 x 20 x 1000짜리 필터를 만들어서 1 X 1 X 1000개 짜리 피처맵을 만듬
- 파라미터도 인풋, 아웃풋도 똑같은데 왜 할까?(특히나 Semantic Segmentation 관점에서)
- Fully convolutional Network의 가장 큰 특징은 인풋차원(특히나 인풋의 spatial 차원의 디펜던트)
- 인풋 사이즈에 상관없이 네트워크가 돌아간다. 아웃풋을 커지게 되면 비례해서 뒷단의 네트워크(spatial 디멘션)도 커짐
=> convolution는 인풋 이미지의 상관없이 동일한 convolution 필터가 찍기 때문에 그게 찍어져서 나오는 결과 spatial 차원도 커짐(이런 동작이 heatmap과 같은 효과)
- FCN은 어떤 인풋 사이즈도 돌아가긴 하지만, 아웃풋 차원이 줄어듬(ex. 100 x 100 -> 10 x 10)
- 그래서 다시 늘리는 방법이 필요함(deconvolution,umpooling 등)
deconvolution(conv transpose)
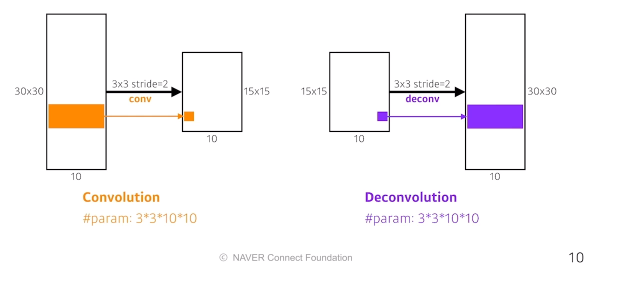
- spatial 차원을 키워주는 것(convolution 역연산)
- 정확히 말하면 역연산은 아님(convolution 연산 3x3 정보를 합쳐서 하나로 만들어주기에 역으로 복원하는 것은 불가능)
=> 엄밀히 말하면 역은 아니지만 파리미터 숫자와 네트워크의 입력과 출력의 측면에서는 동일함
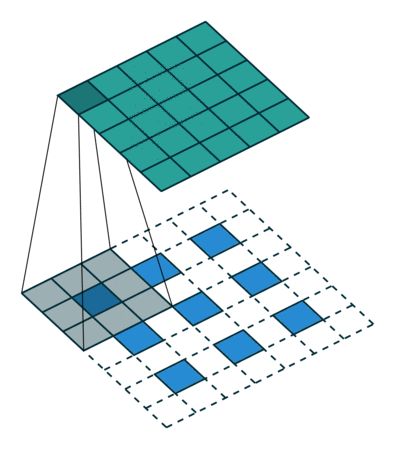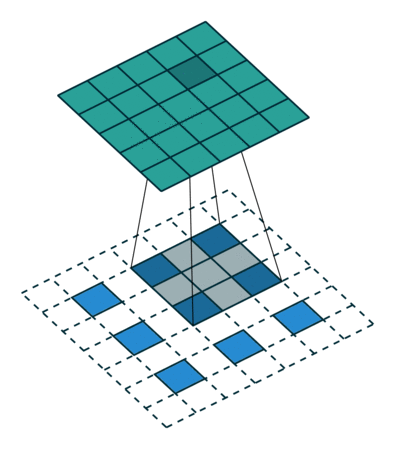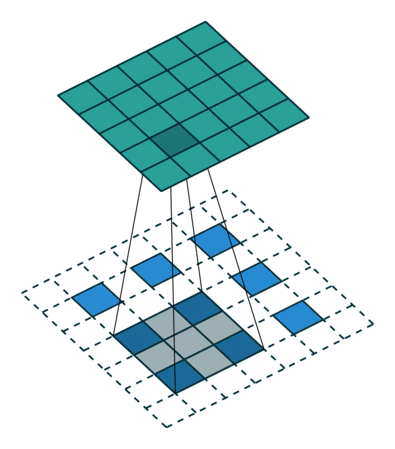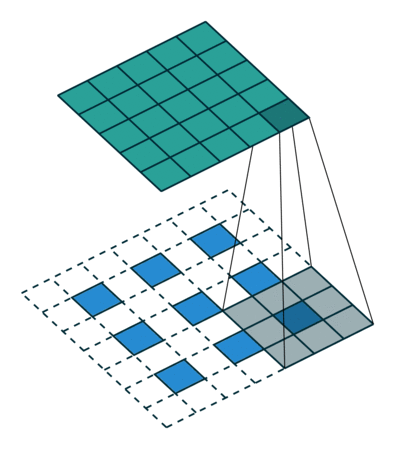
- 정확히 말하면 역연산은 아님(convolution 연산 3x3 정보를 합쳐서 하나로 만들어주기에 역으로 복원하는 것은 불가능)
- padding을 많이 줌 => 결과론적으로 원하는 사이즈가 나옴
Detection
이미지 안에서 어디 물체가 어디에 있는지를 하고 싶은데 perpixel로 하는게 아니라 바운딩박스를 찾는것
R-CNN
이미지에서 2000개의 region(바운딩박스)을 뽑고 똑같은 크기로 맞추고 support vector machine로 분류를 함 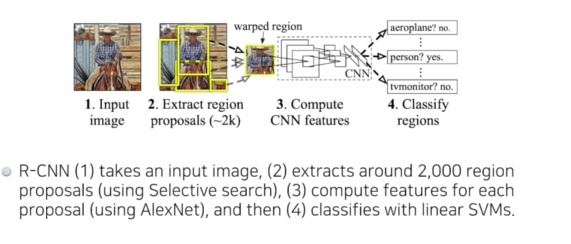
- 시간이 오래걸리고 정확하지 않음
SPPNet
- R-CNN의 문제점: 이미지에서 2000개의 region(바운딩박스)을 뽑으면 2000개 이미지(혹은 패치)를 CNN에 모두 통과시켜야 함(CPU에서는 하나의 이미지를 지나가는데 1분이 걸림)
- SPPNet - 이미지 안에서 CNN 한번만 통과하자 : 이미지안에서 바운딩박스를 뽑고 이미지 전체에 대해서 convolutional feature map을 만든 다음에 뽑힌 바운딩박스에 위치에 해당하는 convolution의 feature map 텐서만 가져오자
- R-CNN는 훨씬 더 빨라진다~
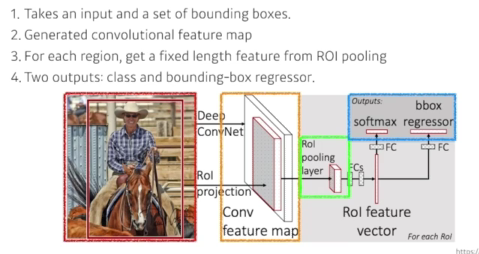
Fast R-CNN
- SPPNet도 결국에는 바운딩박스에 해당하는 텐서를 여러개 뜯어와서 spatial Pyramid pooling으로 하나의 벡터를 만들고 그것도 분류해줘야 하기때문에 느릴수밖에 없다.
- Fast R-CNN의 과정
- 인풋이미지가 들어오고 바운딩박스를 selective search를 미리 2000개를 뽑음
- 하나의 conv feature map을 생성(cnn 한번 통과)
- 각각의 region에 대해서 ROI pooling을 통해 fixed length feature을 뽑음
- 뉴럴네트워크를 통해서 바운딩박스 regression, 얻어지는 바운딩박스가 어떻게 움직이면 좋을지 아니면 바운딩박스에 대한 라벨을 찾게됨
Faster R-CNN
- 바운딩박스를 뽑아내는 region proposal도 학습하자!![]
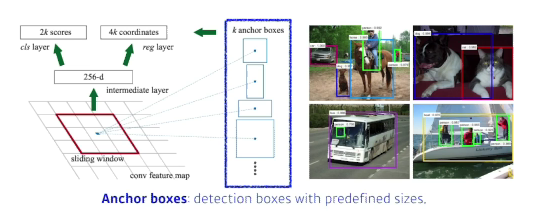
- region proposal network + Fast R-CNN
- region proposal network: 이미지에 있는 특정 영역(패치)이 바운딩박스로서 의미가 있을지 없을지(물체가 있는지 없는지)를 찾아주는 것
- 이를 해주기 위해서 필요한 것은 anchor boxes: 미리 정해놓은 바운딩박스의 크기
- 어떤 크기의 물체가 있을 것 같다 라는것을 미리 알고 있는것
- k개의 템플렛들을 만들어놓고 이 탬플렛들이 얼마나 바뀔지를 정하고
궁극적으로는 템플렛을 미리 고정해놓는것
- Fully convolutional Network의 역할: 모두 영역을 돌아가며 찍기에 해당하는 영역에 물체가 있는지 없는지에 대한 정보를 가지고 있는것
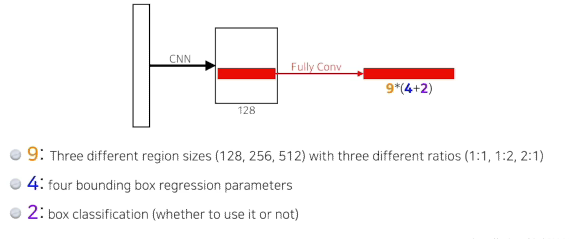
- 9: anchor boxes 또는 region sizes -> 9개 중 하나를 고르게 됨
- 4: 바운딩박스를 얼마나 키우고 줄일지!
- 2: 해당 바운딩박스를 쓸모있는지 없는지!
YOLO (v1)
- Faster R-CNN보다 훨씬 더 빠름 why? 바운딩박스를 따로 뽑는 스텝이 없기 때문에 속도가 빠름

- 이미지가 들어오면 이미지를 SxS 그리드로 나누게 됨
- 이미지 안에 내가 찾고싶은 물체의 중앙이 해당 그리드안에 들어가면 그리드셀이 해당 물체에 대한 바운딩박스와 해당 물체가 무엇인지를 같이 예측
- 바운딩 박스를 찾아줘야 함 즉, 바운딩 박스는 b개를 예측(논문에서는 5개)
- 그 바운딩박스가 쓸모있는지 없는지 boxes probabilities 예측
- 그와 동시에 바운딩박스(혹은 이 그리드셀이 속하는 중점에 있는 어떤 물체)가 어떤 클래스인지 예측

마루에 미친자