타겟
어떤 타겟은 구분 안가는 경우도 있다
- 이산형, 순서형, 범주형 타겟 특성도 회귀문제 또는 다중클래스분류 문제로
- 회귀, 다중클래스분류 문제들도 이진분류 문제로 바꿀 수 있음
결측치 있는 특성 확인
[(x, df[x].isnull().sum()) for x in df.columns if df[x].isnull().any()]any: 하나라도 True 인지 비교 출처
re sub
import re
pattern = "내가 찾고 싶은 문구"
sub_word = "바꾸고 싶은 문구"
script = "문구를 찾을 대상"
result = re.함수(pattern,sub_word, script)
[예시]
import re
pattern = '동'
sub_word = '구'
script = '나는 서초동에 삽니다. 친구는 송파동에 삽니다.'
result = re.sub(pattern, sub_word, script)
print(result)
[출처](https://blog.naver.com/mathesis_time/222219401818)def txt_prep(text):
replacements = [
['Dom Rep|DR|Domin Rep|Dominican Rep,|Domincan Republic', 'Dominican Republic'],
['PNG', 'Papua New Guinea, '],
]
for i, j in replacements:
text = re.sub(i, j, text) # https://blog.naver.com/mathesis_time/222219401818
return text논리합, 논리곱
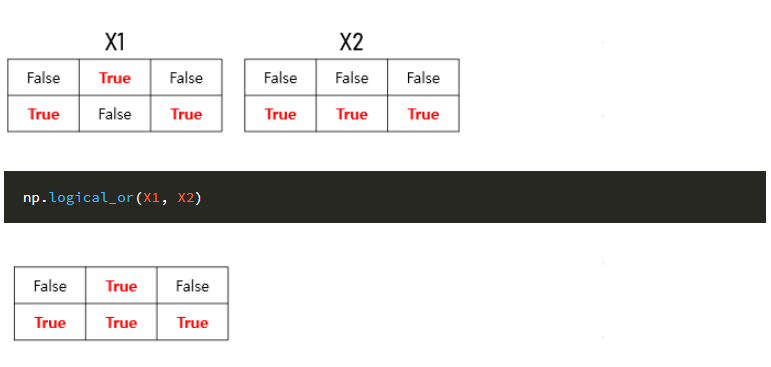
정보의 누수
모델을 만들고 평가를 진행했는데 예측을 100% 가깝게 잘 하는 경우를 종종 보게 될 것
but, 정보의 누수가 존재할 가능성이 크다.
- 타겟변수 외에 예측 시점에 사용할 수 없는 데이터가 포함되어 학습이 이루어 질 경우
- 훈련데이터와 검증데이터를 완전히 분리하지 못했을 경우
정보의 누수가 일어나 과적합을 일으키고 실제 테스트 데이터에서 성능이 급격하게 떨어지는 결과를 확인할 수 있음
그러므로 정보의 누수가 일어나는 특성을 제거해줘야한다.
- 평가지표를 Accuracy뿐 만 아니라 정밀도, 재현율, ROC curve, AUC 도 같이 사용해야함
- AUC가 0.5이면 학습이 거의 일어나지 않은것
불균형 타겟
불균형 클래스
타겟 특성의 클래스 비율이 차이가 많이 나는 경우가 있음
- 대부분 scikit-learn 분류기들은 class_weight 와 같은 클래스의 밸런스를 맞추는 파라미터를 가지고 있음(분류)
- 데이터가 적은 범주 데이터의 손실을 계산할 때 가중치를 더 곱하여 데이터의 균형을 맞춤
- 적은 범주 데이터를 추가샘플링(oversampling)하거나 반대로 많은 범주 데이터를 적게 샘플링(undersampling)하는 방법이 있습니다.
class-weight
y_train.value_counts(normalize=True) ----------------------- False 0.824268 True 0.175732custom = len(y_train)/(2*np.bincount(y_train)) custom -------------------- array([0.60659898, 2.8452381 ])DecisionTreeClassifier(max_depth=5, class_weight{False:custom[0],True:custom[1]}, random_state=2)DecisionTreeClassifier(max_depth=5, class_weight='balanced', random_state=2)
회귀문제에서 타겟의 분포
- 회귀문제일 경우 특히, 타겟의 분포를 주의깊게 살펴봐야함
why?
1. 일반적으로 특성과 타겟간에 선형관계를 가정
2. 특성 변수들과 타겟변수의 분포가 정규분포 형태일때 좋은 성능을 보임
방법 1. 이상치 제거
df['SalePrice'] = df[df['SalePrice'] < np.percentile(df['SalePrice'], 99.5)]['SalePrice']
df = df[df['SalePrice'].notna()]방법 2. 로그 변환
- 타겟이 right-skewed 상태라면 로그변환을 사용하여 정규분포형태로 변환
from sklearn.compose import TransformedTargetRegressor pipe = make_pipeline( OrdinalEncoder(), SimpleImputer(), RandomForestRegressor(random_state=2) ) tt = TransformedTargetRegressor(regressor=pipe, func=np.log1p, inverse_func=np.expm1) tt.fit(X_train, y_train) tt.score(X_val, y_val)

마루에 미친자