교차검증(Cross-validation)
Hold-out교차검증
:한번 훈련/검증/테스트 세트로 나누어 학습한 방법
어떤 문제점이 있을까?
1.데이터가 충분히 많다면 문제가 되지 않는다. but, 데이터가 충분히 많이 않으면 문제가 됨
2. 검증세트 크기가 충분히 크지 않아 비율을 줄인다면 예측 성능에 대한 추정이 부정확함
모델선택(Model selection)
- 우리 문제를 풀기 위해 어떤 학습 모델을 사용해야 할까?
- 어떤 하이퍼파라미터를 사용할 것인가?
데이터가 크지 않을때, 모델선택의 문제 해결을 위한 한 방법으로 교차 검증이 있다
- 시계열 데이터에는 교차검증이 적합하지 않음
k-fold cross-validation(CV)
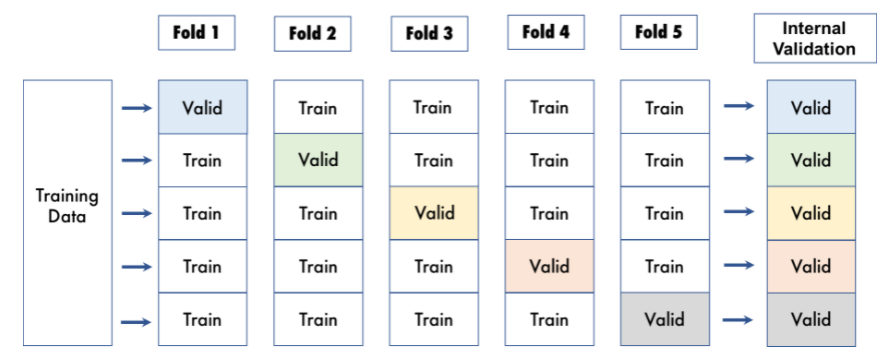
데이터를 k개로 등분하여야 하고, k개의 집합에서 k-1 개의 부분집합을 훈련에 사용하고 나머지 부분집합을 테스트 데이터로 검증
- 예) 3-fold CV -데이터를 3등분으로 나누고 검증(1/3)과 훈련세트(2/3)를 총 세번 바꾸어가며 검증
- K는 결정하는 것은 도메인마다 다르지만 보통 5~10사이로 결정(default=5)
from sklearn.model_selection import cross_val_score scores = cross_val_score(pipe, X_train, y_train, cv=k, scoring='f1') print(f'f1 for {k} folds:', scores) # K 만큼 score 나옴scores.mean() scores.std()
분류, 회귀, 군집 등에 따라서 scoring가 달라짐
- 회귀에 경우 negative(음수) 평가지표로 사용하는 것도 있음(예. neg-mae)
밑에 링크로 모델에 따른 scoring 확인
The scoring parameter
TargetEncoder
범주 값을 대상의 다른 특성의 평균값으로 대체하는 범주형 변수 인코더
- 예)'Lotshape' feature에 Reg라는 값이 어떤 특성에 대한 평균값을 계산되어 Reg 대신 그 값이 나타남
from category_encoders import TargetEncoder encoder = TargetEncoder(min_samples_leaf=1, smoothing=1000) df['Animal Encoded'] = encoder.fit_transform(df['Animal'], df['Target'])
특징
이는 종종 발생 횟수가 적은 값의 분산을 줄이기 위해서, 전체 데이터셋에 대한 타겟 확률과 섞여서 사용
타겟을 사용해서 새로운 특성을 만드므로 타겟 인코딩에 검증, 테스트 데이터를 포함시키는 것은 타겟 누출(target leakage)의 한 형태
but,훈련 데이터 셋에서만 타겟 인코딩을 학습시키고, 다른(검증, 테스트) 데이터 셋에 적용
(+) 데이터세트의 차원을 추가하지 않기에 간단하고 빠른 인코딩 가능-> 인코딩의 첫번째 시도로도 사용함
(-) target의 분포에 따라 달라지기에 과적합되기 쉬우므로 신중한 검증이 필요

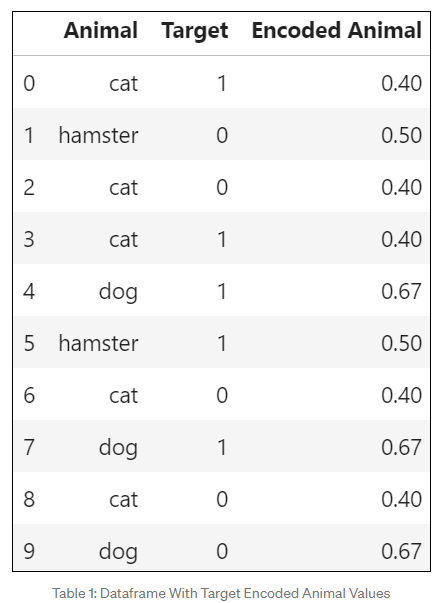
TargetEncoder 이해해보기
 Animal에 인코딩을 해보자
Animal에 인코딩을 해보자
1. Animal의 데이터마다 그룹화해주고 0,1 각각 발생횟수를 계산하자
- 예) cat는 총 5번 중에 1은 3번 0은 2번 발생함
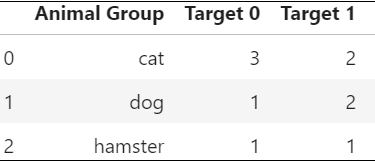
2.타겟 1의 발생확률을 계산하라
- 예) cat의 경우 5번중에 1은 2번나왔으므로 0.4이다

이렇게 하면 인코딩 된것을 확인할 수 있다.
공식문서
참고
참고
하이퍼파라미터 튜닝
- 최적화는 훈련 데이터로 더 좋은 성능을 얻기 위해 모델을 조정하는 과정
- 일반화는 학습된 모델이 처음 본 데이터에서 얼마나 좋은 성능을 내는지를 이야기 함

검증곡선(validation curve)
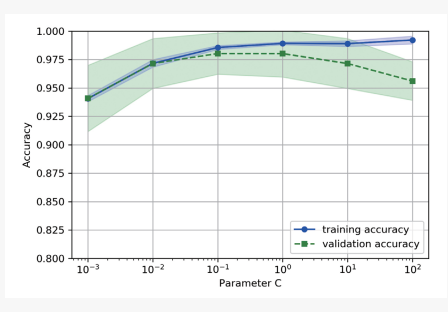 : 하이퍼파라미터에 따른 정확도 변화를 나타냄
: 하이퍼파라미터에 따른 정확도 변화를 나타냄
- y축: 스코어 / x축: 하이퍼파라미터 로 그린 그래프
- 사이킥런을 이용해 다양한 하이퍼파라미터 값에 대해 훈련/검증 스코어 값의 변화를 확인


최적의 하이퍼파라미터 조합을 찾아주는 도구
GridSearchCV는 DAY27
Randomized Search CV
:검증하려는 하이퍼파라미터들의 값 범위를 지정해주면 무작위로 값을 지정해 그 조합을 모두 검증
- 모든 조합을 다 시도하지는 않고, 각 반복마다 임의의 값만 대입해 지정한 횟수만큼 평가
- n_iter * 교차검증(cv)= Task 양 이므로 이를 고려하여 설정(너무 많은면 시간이 오래 걸림)
rt =RandomForestClassifier() param = { 'max_depth':range(1, 21), 'max_leaf_nodes':range(5, 101, 5), 'criterion':['entropy','gini'] } n_iter = 80 rs = RandomizedSearchCV(rt, param_distributions=param, n_iter=n_iter, cv=5, scoring='f1' n_jobs=-1) rs.fit(X_train, y_train)print('최적 하이퍼파라미터: ',rs.best_params_) print('f1: ', rs.best_score_)best_estimator and refit
bestestimator 는 CV가 끝난 후 찾은 best parameter를 사용해 모든 학습데이터(all the training data)를 가지고 다시 학습(refit)한 상태
from sklearn.metrics import f1_score pipe2= rs.best_estimator_ y_pred = pipe2.predict(X_test) f1 = f1_score(y_test, y_pred) print(f'테스트세트 f1: ${f1:,.0f}')
튜닝할때 다양한 상황
- 파이프라인처럼 한가지 말고 다양한 메소드의 하이퍼파라미터 튜닝해야 할때
dists = { 'targetencoder__smoothing':[2.,20.,50.,60.,100.,500.,1000.], 'simpleimputer__strategy': ['mean', 'median'],
- 랜덤함수 이용해 범위지정하기
dists = { 'targetencoder__min_samples_leaf': randint(1, 10), 'randomforestregressor__max_features': uniform(0, 1)튜닝할때 추천 하이퍼파라미터



