Warm-up
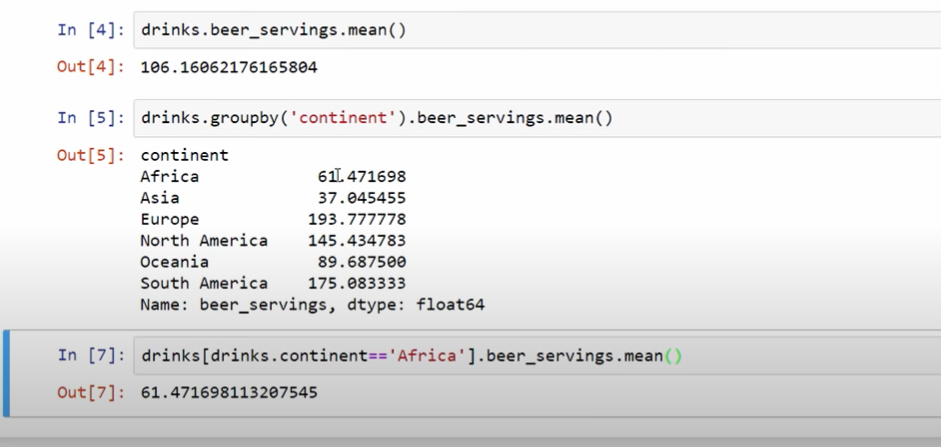
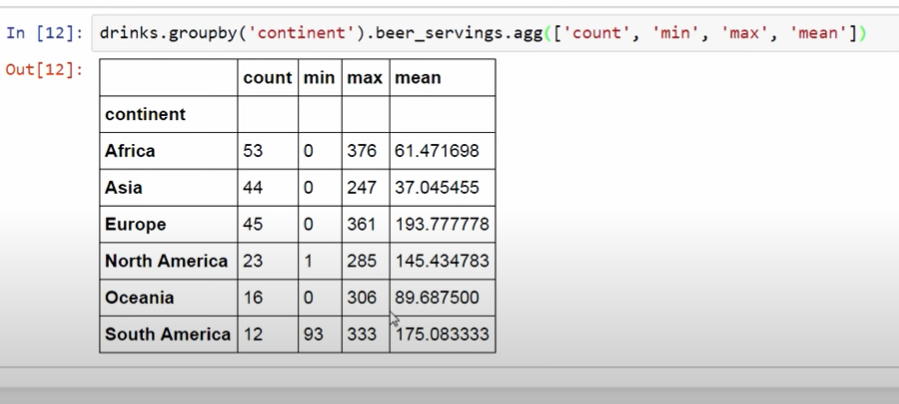
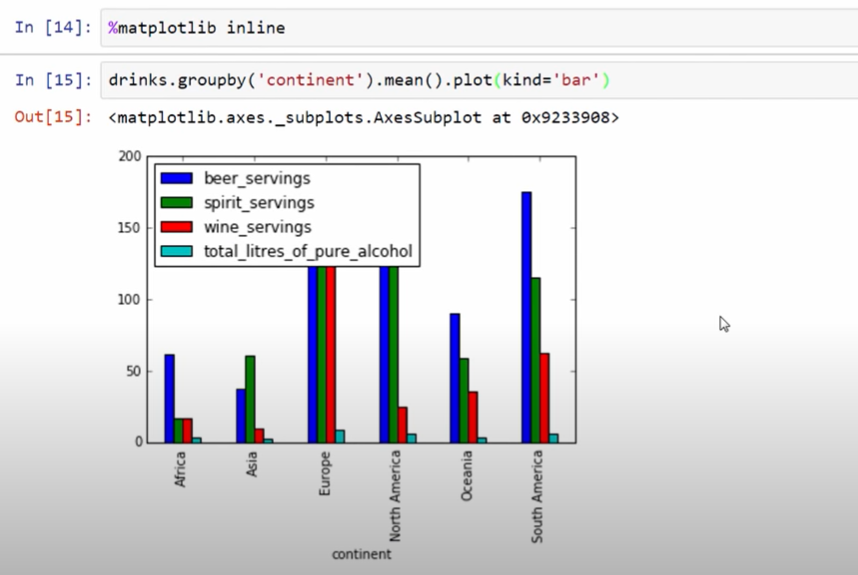
데이터 랭글링
분석을 하거나 모델을 만들기 전에 데이터를 사용하기 쉽게 변형하거나 맵핑하는 과정
- 데이터 전처리, 클리닝와 혼용, 포괄적으로 봤을 때 EDA로 보는 사람도 있음(문맥에 따라 사용)
Preview
from IPython.display import display
import pandas as pd
def preview():
for filename in glob('*.csv'):
df = pd.read_csv(filename)
print(filename, df.shape)
display(df.head())
print('\n')isdisjoint()
: 같은 값이 하나도 없으면 True로 반환하나 1개라도 값은 값이면 False 반환
>>>mySet = set("ever")
>>>mySet2 = set("tomo")
>>>print(mySet.isdisjoint(mySet2))
--------------------------------------
Trueset()
- set은 수학에서 이야기하는 집합
- 순서가 없고, 집합안에서는 unique한 값 가짐.
- mutable 객체
set 자세히 나옴
중복샘플 있는지 확인
len(df.feature1.unique()) == len(df)최빈값(가장 빈번하게 나타나는 데이터)
df['feature 이름'].mode()N232
value_counts() 데이터프레임으로 출력
df['Item ID'].value_counts().rename_axis('unique_values').reset_index(name='counts')더 알아야 할것
Leature Note에
끝에 3) 바나나 구매 횟수와 4) 최근 몇일 전에 바나나를 구입했는지? 에 대한 코드 이해할 것

마루에 미친자