파이프라인
- 여러 ML모델을 전처리 프로세스에 연결
- 그리드서치를 통해 여러 하이퍼파라미터를 쉽게 연결
from sklearn.pipeline import make_pipeline
pipe = make_pipeline(
OneHotEncoder(),
SimpleImputer(),
StandardScaler(),
LogisticRegression(n_jobs=-1)
)
pipe.fit(X_train, y_train)
print('검증세트 정확도', pipe.score(X_val, y_val)) #파이프라인에서는 SCORE 안에 트렌스폼이 있음named_steps: 유사 딕셔너리 객체(dictionary-like object)로 파이프라인 내 과정에 접근 가능
결정트리(Decision Tree) 모델
 : 데이터를 분할해 가는 알고리즘
: 데이터를 분할해 가는 알고리즘
- 스무고개를 하는 것과 같이 특성들의 수치를 가지고 질문을 통해 정답 클래스를 찾아가는 과정
- 노드(node):질문이나 말단의 정답
엣지(edge): 노드를 연결하는 선

- 노드의 구성: 뿌리(root)노드, 중간(internal)노드, 말단(external, leaf, terminal) 노드(부모 노드-자식 노드)
- 결정트리는 분류와 회귀문제 모두 적용 가능
- 분류 과정은 새로운 데이터가 특정 말단 노드에 속한다는 정보를 확인한 뒤 말단노드의 빈도가 가장 높은 범주로 데이터를 분류
(+) 쉽고 직관적이며, 스케일링과 정규화같은 전처리 작업의 영향도가 크지 않다
(-) 모델이 복잡해지고 과적합에 빠지기 쉽다
결정트리 학습 알고리즘
- 결정트리를 학습하는 것은 노드를 어떻게 분할하는가에 대한 문제
- 노드 분할 방법에 따라 다른 모양의 트리구조가 만들어짐
- 트리모델 학습 알고리즘: 결정트리의 비용함수를 정의하고 그것을 최소화 하도록 분할하는 것
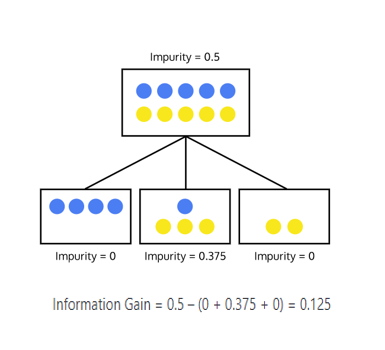
비용함수: 지니불순도 VS 엔트로피
지니불순도와 엔트로피은 목적은 같은것
불순도란? 여러 범주가 섞여 있는 정도
- (45%, 55%)인 샘플(두 범주 수가 비슷): 불순도가 높은 것
- (80%, 20%)인 샘플: 상대적으로 위의 상태보다 불순도가 낮은 것(<-> 순수도는 높은것)
- 불순도가 낮은경우 지니불순도나 엔트로피는 낮은값을 가짐
노드를 분할하는 시점에서 가장 비용함수를 줄이는 분할특성과 분할지점을 찾아 내는 프로세스가 필요
사이킥런으로 결정트리
from sklearn.tree import DecisionTreeClassifier classifier = DecisionTreeClassifier() classifier.fit(training_points, training_labels) predictions = classifier.predict(test_data) print(classifier.score(test_data, test_labels))
결정트리 시각화

from sklearn.tree import export_graphviz
e_columns= X_val.columns
model_dt = DecisionTreeClassifier(random_state=156)
export_graphviz
dot_data = export_graphviz(model_dt
, max_depth=3
, feature_names=e_columns
, class_names=['no', 'yes']
, filled=True
, proportion=True)
display(graphviz.Source(dot_data))과적합 해결하기
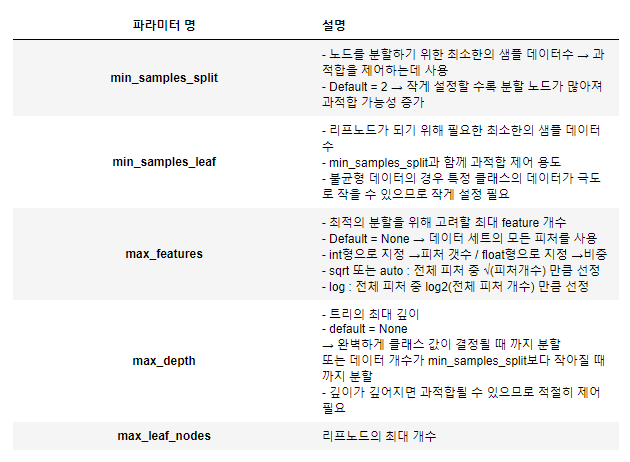
트리의 복잡도를 줄이기 위해 자주 쓰는 하이퍼파라미터
min_samples_split\: 노드의 분기를 만들기 위해 최소한 샘플이 노드에 얼마나 있는지 확인min_samples_leaf: 리프 노드에 최소한 샘플이 설정할 수 있음max_depth: (가장 강력함) 트리 깊이를 설정할 수 있음(층의 갯수)
특성 중요도
- 항상 양수값이며, 그 값을 통해 특성이 얼마나 일찍, 자주 분기에 사용되는지 결정
model_dt = DecisionTreeClassifier(random_state=156)
importances = pd.Series(model_dt.feature_importances_, e_columns)
plt.figure(figsize=(10,30))
importances.sort_values().plot.barh();비선형, 비단조, 특성 상호작용의 데이터
-
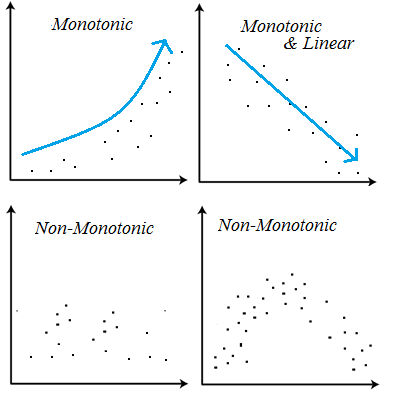
결정트리모델은 비선형, 비단조(non-monotonic), 특성상호작용(feature interactions) 특징을 가지고 있는 데이터 분석에 용이
-
특성 상호작용: 특성상호작용은 특성들끼리 서로 상호작용을 하는 경우
- 회귀분석에서는 서로 상호작용이 높은 특성들이 있으면 개별 계수를 해석하는데 어려움이 있음-> 학습의 어려움 有
- 트리모델은 이런 상호작용을 자동으로 걸러내는 특징
-
비선형에서도
max_depth를 더할수록 선에 적합이 되어 비선형 데이터를 학습할 수 있음을 시각적으로 확인
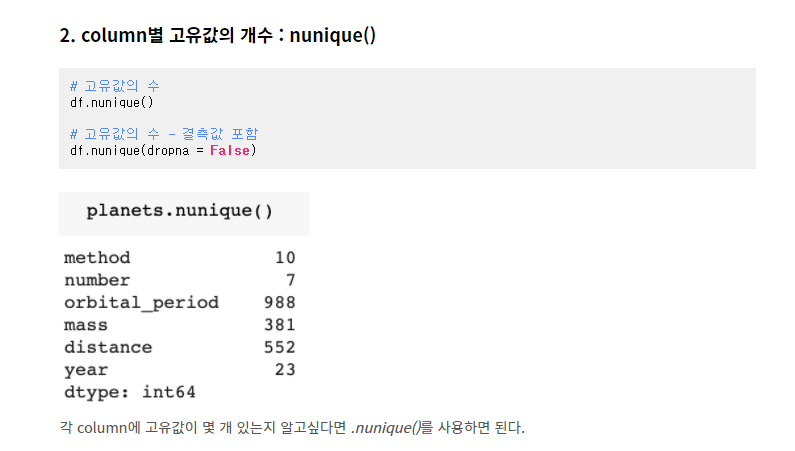
unique VS nunique
-
데이터에 고유값이 무엇이 있는지 알고 싶다면 unique
-
총 고유값의 수가 몇 개인지 알고 싶다면 nunique
-
값별로 데이터의 개수를 알고 싶다면 value_counts


마루에 미친자