랜덤포레스트(Random Forests)
랜덤포레스트 모델은 여러개의 결정트리를 '병렬(parallel)'로 학습하여 각 결과값을 집계(분류의 경우 다수결, 회귀의 경우 평균)하여 최종 예측값을 리턴
앙상블 방법
한 종류의 데이터로 여러 머신러닝 학습모델(weak base learner, 기본모델)을 만들어 그 모델들의 예측결과를 다수결이나 평균을 내어 예측하는 방법
- 앙상블 모델에는 bagging, boosting, stacking 모델이 있다. 랜덤포레스트는 그 중 bagging 모델에 해당
- 랜덤포레스트는 결정트리를 기본모델로 사용하는 앙상블 방법
- 랜덤포레스트는 결정트리보다 일반적으로 성능이 좋으니 분류문제 일 경우, 랜덤포레스트를 하는 것이 좋다
랜덤포레스트의 기본모델은 어떻게 만들까?
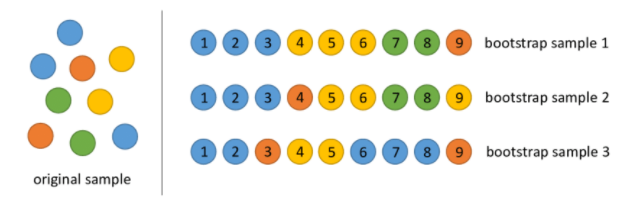
앙상블에 사용하는 작은 모델들은 부트스트래핑(bootstraping)이라는 샘플링과정으로 얻은 부트스트랩세트를 사용해 학습을 한다
- 원본 데이터에서 샘플링을 하는데 복원추출을 한다는 것인데 복원추출은 샘플을 뽑아 값을 기록하고 제자리에 돌려놓는 것
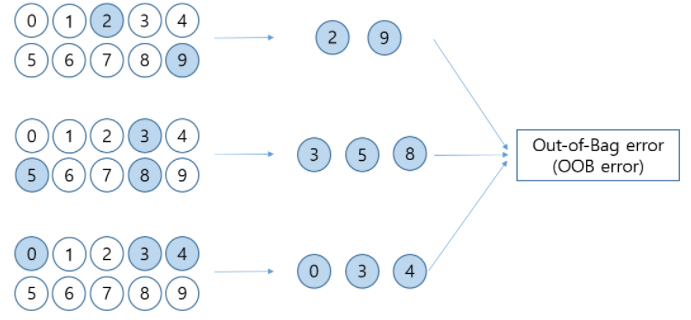
-추출되지 않은 샘플이 Out-Of-baf 샘플= test sets
부트스트랩세트의 크기가 n이라 할 때 한 번의 추출과정에서 어떤 한 샘플이 추출 되지 않을 확률
n회 복원추출을 진행했을 때 그 샘플이 추출되지 않았을 확률
n을 무한히 크게 했을 때
- 즉 데이터가 충분히 크다고 가정했을 때 한 부트스트랩세트는 표본의 63.2% 에 해당하는 샘플을 가짐
- Out-Of-Bag 샘플은 36.8%의 샘플을 가짐
랜덤포레스트는 기본모델들의 트리를 만들 때 무작위로 선택한 특성세트를 사용
기본모델(weak learner, 작은 모델들)은 어떻게 합치나요?
부트스트랩세트로 만들어진 기본모델들을 합치는 과정을 Aggregation 이라고 합니다.
- 회귀문제일 경우 기본모델 결과들의 평균으로 결과를 냄
- 분류문제일 경우 다수결로 가장 많은 모델들이 선택한 범주로 예측
파이프라인으로 랜덤포레스트
from category_encoders import OneHotEncoder from sklearn.ensemble import RandomForestClassifier from sklearn.impute import SimpleImputer from sklearn.pipeline import make_pipeline pipe = make_pipeline( OneHotEncoder(use_cat_names=True), SimpleImputer(), RandomForestClassifier(n_jobs=-1, random_state=10, oob_score=True) ) pipe.fit(X_train, y_train) print('검증 정확도: ', pipe.score(X_val, y_val))OOB 정확도
pipe.named_steps['randomforestclassifier'].oob_score_
oob score vs validation set score
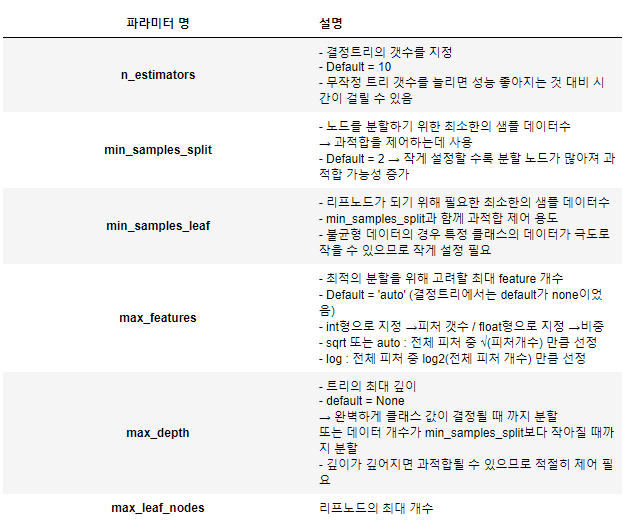

트리 앙상블 모델이 결정트리모델보다 상대적으로 과적합을 피할 수 있는 이유가 무엇일까요?(2가지)
결정트리는 데이터 일부에 과적합하는 경향이 있음
다르게 샘플링된 데이터로 과적합된 트리를 많이 만들고 그 결과를 평균내 사용하는 모델이 랜덤 포레스트임 이렇게 하면 과적합이 줄고 성능이 유지 된다는 것이 알려져 있음
- 랜덤포레스트에서 학습되는 트리들은 배깅을 통해 만들어짐(
bootstrap = true) 이때 각 기본트리에 사용되는 데이터가 랜덤으로 선택- 각각 트리는 무작위로 선택된 특성들을 가지고 분기를 수행(
max_features = auto.)
순서형(ordinal) 인코딩
순서형 인코딩은 범주에 숫자를 맵핑
예) ['a', 'b', 'c'] 세 범주가 있다면 이것을 -> [1, 2, 3] 이렇게 숫자로 인코딩
- 결측치에 대해서는 지정한'handle_missing="value"속성에서 리턴(이 경우 -2가 리턴됨) 된 것이 아니라, 'handle_unknown' 속성에서 unknown 값이 있을 경우 (-1) 로 리턴된 것
- 수치형 데이터는 인코딩 하지 않음
공식문서


원핫인코딩 vs 순서인코딩
트리구조에서는 중요한 특성이 상위노드에서 먼저 분할이 일어납니다.
그래서 범주 종류가 많은(high cardinality) 특성은 원핫인코딩으로 인해 상위노드에서 선택될 기회가 적어집니다.원핫인코딩 영향을 안 받는 수치형 특성이 상위노드를 차지할 기회가 높아지고 전체적인 성능 저하가 생길 수 있습니다.
- 순서 인코딩을 통해서 high cardinality인 특성도 고려 할 수 있음
- but, 원핫인코딩을 사용해야 할 범주형 데이터에 순서형 데이터를 사용하면 모델의 성능에 도움이 안 될것
- OrdinalEncoder를 사용해 무작위로 수치를 인코딩하여서 범주들을 순서가 있는 숫자형으로 바꾸면 원래 그 범주에 없던 순서정보가 생길 수 있음
예) 빵,밥=> 빵-1, 밥-2- but, 랜덤포레스트 경우에는 여러개의 결정트리를 '병렬(parallel)'로 학습하기 때문에 순서인코딩 사용가능
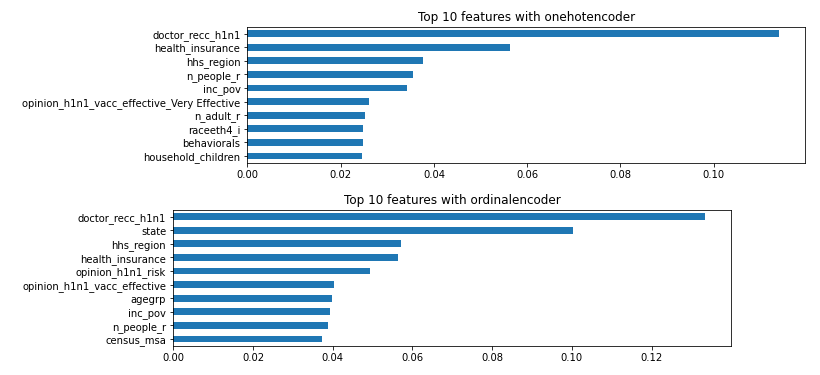
랜텀포레스트 특성 중요도 비교 (onehot vs ordinal)
- 중요도는 노드들의 지니불순도(Gini impurity)를 가지고 계산하고 노드가 중요할 수록 불순도가 크게 감소함
- 노드는 한 특성의 값을 기준으로 분리가 되기 때문에 불순도를 크게 감소하는데 많이 사용된 특성이 중요도가 올라갈 것
# 특성 중요도(onehot) rf = pipe.named_steps['randomforestclassifier'] colnames = pipe.named_steps['onehotencoder'].get_feature_names() importances = pd.Series(rf.feature_importances_, colnames) # 특성 중요도(ordinal) rf_ord = pipe_ord.named_steps['randomforestclassifier'] importances_ord = pd.Series(rf_ord.feature_importances_, X_train.columns)결과
- onehot과 ordinal 특성중요도가 다름을 알 수 있음
N223
GridSearchCV()
- 시도해 볼 하이퍼파라미터들을 지정하면, 모든 조합에 대해 교차검증 후 가장 좋은 성능을 내는 하이퍼파라미터 조합을 찾음.
- 하이퍼파라미터 값들이 많아지면 시간이 오래 걸린다는 단점이 있음.
from sklearn.model_selection import GridSearchCV params = { 'n_estimators' : [10, 100], 'max_depth' : [6, 8, 10, 12], 'min_samples_leaf' : [8, 12, 18], 'min_samples_split' : [8, 16, 20] } # RandomForestClassifier 객체 생성 후 GridSearchCV 수행 pipe = RandomForestClassifier(random_state = 10, n_jobs = -1, oob_score=True) grid_cv = GridSearchCV(pipe, param_grid = params, cv = 3, n_jobs = -1) grid_cv.fit(X_train_imputed, y_train) print('최적 하이퍼 파라미터: ', grid_cv.best_params_) print('최고 예측 정확도: {:.4f}'.format(grid_cv.best_score_))

Count Encoding
- 카운트 인코딩은 각 범주형 값들을 데이터셋에 나타나는 횟수로 바꾼다.
- 예를 들어 값 "GB"가 country 특성에서 10번 나타났다면, "GB"를 10으로 바꿔준다.
- 수치형 데이터에는 인코딩이 되지 않고 매 "GB"마다 10으로 표시됨
출처
