1. 강의 수강 목적
1) NLP 심화 공부 및 협업 기회
- NLP 프로젝트를 진행하다보니 지식의 한계를 깨달았습니다. 특히, NLG부분에 대해서 기초 쌓기도 어렵고 자료를 찾기 힘들어서 이번에 관련된 논문을 많이 접하면서 NLG에 대해 보다 지식 습득을 목표로 하고 있습니다.
- Pytorch를 사용한 적이 있었는데, 잘 알지 못하는 라이브러리로 사용하니 기능 개선이나 전반적인 발전에 크게 어려움이 있었습니다. 그래서 이번에 Pytoch에 익숙해지는 것이 목표입니다.
- 개인 프로젝트를 진행한 적은 많으나, 협업을 진행한 적이 없었기에 이번에 협업 프로젝트 진행하는 것이 목표입니다.
2) 취업가능성 높이기
- 해당 공부 및 프로젝트를 통해 포트폴리오를 강화하여 서류 합격률을 높이는 것이 목표입니다.
- 참가기업 중 기존에 관심있는 회사가 있기에 해당 기업의 취업 및 정보 습득이 목표입니다.
2. NLP Sub tasks
2-1) Language Modeling: Speech Recognition
(1) 해결하고자 하는 문제
: 오디오의 음성을 인식하여 텍스트로 변화하는 문제를 해결합니다.
(2) 데이터: LibriSpeech
- LibriVox 프로젝트의 결과인 약 1,000시간 분량의 영어 오디오북 데이터입니다.
- 훈련데이터는 100시간, 360시간, 500시간으로 3 부분으로 나뉘고 각 테스트 데이터의 오디오 길이는 약 5시간입니다.
- 자동인식시스템이 수행이 잘되는지 힘든지에 따라 범주는 'clean', 'other' 로 구분됩니다
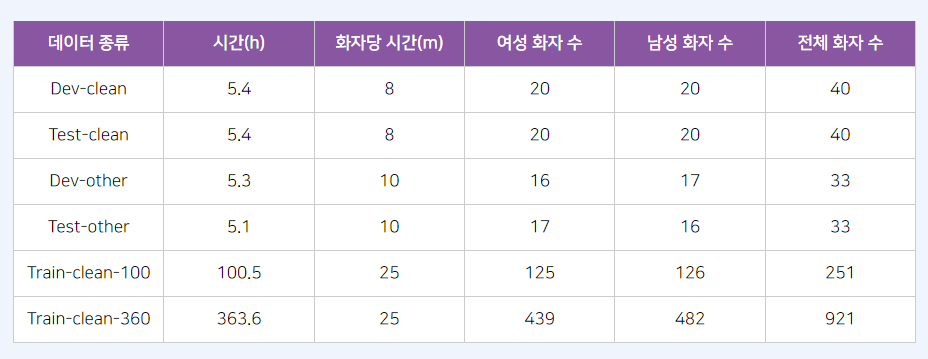
표 출처
(3) SOTA 모델: w2v-BERT XXL
- contrastive learning 과 MLM 결합된 프레임워크입니다.
- contrastive learning: 비슷한 데이터 샘플끼리의 representation은 가깝게, 비슷하지 않은 데이터 샘플끼리는 representation 멀게 하는 것을 말합니다.
- MLM: input에서 무작위하게 몇개의 token을 mask 시키고 주변 단어의 context만을 보고 mask된 단어를 예측
- 주요 키워드: Self-supervised learning, representation learning, unsupervised pre-training, BERT, wav2vec 2.0
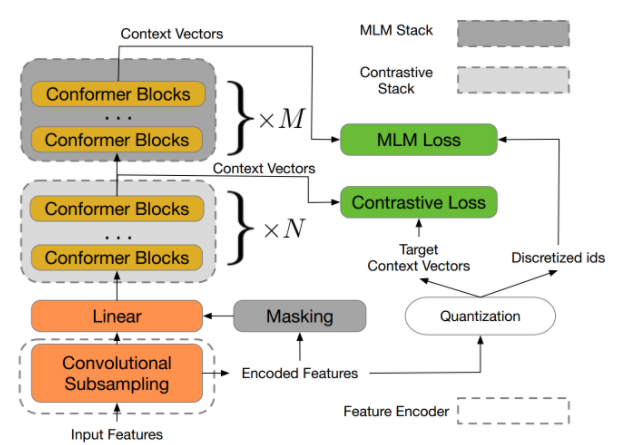
사진 출처
2-2) Text Generation: Dialogue Generation
: 사용자가 작성한 게시물에 대한 응답을 자동으로 생성하는 것은 텍스트 생성 작업을 말합니다.
- siri 및 Alexa와 같은 가상 비서의 기본 구성
(2) 데이터:PERSONA-CHAT
- 두명의 랜덤 클라우드 소서가 주어진 페르소나로 연극하듯이 대화하며, 15단어 미만의 대화로 6~8 턴으로 이루어진 데이터
- train: 8939개, validation: 1000개, test:968개

(3) SOTA 모델: P^2 Bot
- 최근 Language Generation 모델은 언어를 제대로 이해하기보단 pattern를 외우고 이를 바탕으로 언어를 생성합니다. 이런 문제를 해결하기 위해 P^2 Bot를 제시하였습니다.
- 이해를 명시적으로 모델링할 목적으로 transmitter-receiver 기반으로 한 프레임워크
- 대화 내용뿐만 아니라 대화에 참여하는 Persona라는 메타 정보를 명시적으로 고려하면서 대화가 이루어질 수 있도록 하는 모델
- 주요 키워드: P^2 Bot, Dialogue Generation, Mutual Persona Perception

마루에 미친자
5개의 댓글

2022년 2월 21일
같은 speech recognition을 조사했는데 다른 SOTA모델을 설명해주셔서 모델에 대해 간략하게 알아볼수 있었습니다. w2v-BERT는 마스킹과 contrastive를 주요개념으로 삼는 표현학습이라는 것을 알게 됐습니다.
답글 달기

2022년 2월 21일
이전에 NLP에 대해 배우면서 단어 유사도 개념과 Masking을 통한 추론 형태의 기법을 배웠던 것 같은데 2가지의 방법을 모두 사용해서 더 성능이 좋은 모델을 만듦과 동시에 Quantization을 통해 모델의 연산량을 줄이는 방법을 채택할 수 도 있다 라는 알고리즘을 배우게 되었네요.
답글 달기

2022년 2월 21일
저도 Speech Recognition에서 데이터셋을 'clean' 과 'other'로 나눈 기준이 뭔지 알고 싶었는데 위에서 댓글로 설명해주셔서 참고가 잘 되었습니다! 나눈 이유는 채은님 말씀처럼 한계점까지 학습시켜보겠다는 것 같기도 한데 논문 조금 더 읽어봐야겠네요.
답글 달기
Speech Recognition에서 데이터셋에 clean과 other을 나눈이유가 궁금합니다 clean으로 먼저 학습을 진행하고 other로 더 어렵게 학습하기위한 것일까요?