NLU
- NLU: understanding = syntactic(문법적으로 옳은가?) + semantic(문장의 의미를 아는가?)
| task | 실생활 | SOTA 모델 |
|---|---|---|
| 문법(CoLA) | 자동 문법 교정 | biLSTM, BERT(RoBERTa) |
| 감성 분석(SST) | 상품&서비스 리뷰 데이터 긍/부정 판별 | BERT(RoBERTa) |
| 문장 유사성(STS,MRPC, QQP) | 유사 문서 클러스터링 | BERT(RoBERTa) |
| 추론(MNLI,RTE) | 자동 내부 및 회계 검사 | T5, Bert(ALBERT, DeBERTa) |
| 언급 대상 추론(WNLI) | QA, 요약, 번역 등 성능 향상을 위한 필수 요소 | Bert(SpanBERT, RoBERTa) |
| QA(SQuAD) | 검색 시스템 스닛펫 | T5, Bert(Bigbird), XLNet |
- 스닛펫(snippet): "특정 검색어에 대해 답이 되는 요약 정보 조각"
-> 검색어에 가장 정확하고 정리된 정보를 가진 글을 성정하여 최상단을 띄어주는 - 이외에도 다른 task
- 분류: 이탈 고객 예측, 상품 카테고리 분류 등
- 군집화: 유사 제품군 군집화, 유사 키워드 생성
- GLUe, SQuAD 같이 공신력 있는 NLU 대회 있음(한국어버전의 대회도 있음)
더 찾아보기: 벤치마크 데이터셋
"벤치마크 데이터셋은 공통된 기준으로 인공지능 정확도를 평가하고 경쟁할 수 있는 기반"

벤치마크 종류
GLUE
- "GLUE 벤치마크 자연어 이해 성능을 평가하기 위한 데이터셋"
- 뉴욕대, 워싱턴대, 딥마인드등을 협업하여 벤치마크 구축
- baseline : BiLSTM
- dataset
- single-sentence tasks
- CoLA (Corpus of Linguistic Acceptability)
- SST-2 (Stanford Sentiment Treebank)
- similarity and paraphrase tasks
- MRPC (Microsoft Research Paraphrase Corpus)
- QQP (Quora Question Pairs)
- STS-B (Semantic Textual Similarity Benchmark)
- inference tasks
- MNLI (Multi-Genre Natural Language Inference)
- MNLI_m, MNLI_mm
- QNLI (Question Natural Language Inference)
- RTE (Recognizing Textual Entailment)
- WNLI (Winograd Natural Language Inference)
- MNLI (Multi-Genre Natural Language Inference)
- single-sentence tasks
SuperGLUE
- GLUE 벤치마크 공개 후 1년 후 난이도가 향상된 SuperGLUE 벤치마크를 다시
구축 - baseline : BERT
- dataset (8)
- BoolQ (Boolean Questions)
- CB (CommitmentBank)
- COPA (Choice of Plausible Alternatives)
- MultiRC (Multi-Sentence Reading Comprehension)
- ReCoRD (Reading Comprehension with Commonsense Reasoning Dataset)
- RTE (Recognizing Textual Entailment)
- WiC (Word-in-Context)
- WSC (Winograd Schema Challenge)
SQuAD
- SQuAD is "a reading comprehension dataset"
- 질문: Wikipedia의 기사에 대한 crowdworker들이 제시
- unanswerable question은 온라인의 crowd worker(기계 아닌 진짜 사람)가 직접 생성
- 사림이 직접했기에 기계적으로 판별이 어려움
- 답변: 독해 지문의 텍스트 또는 span 부분 또는 답이 없을 수도 있음
KLUE & KorQuAD
- "KLUE는 한국어 언어모델을 평가하기 위한 벤치마크"
- 8개의 테스크로 구성
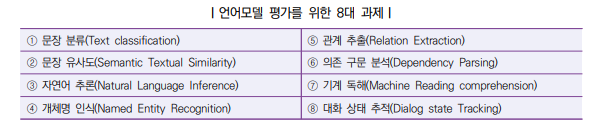
- "KorQuAD 데이터셋은 LG CNS에서 구축 후 공개한 데이터"
- 한국어 언어모델 질의응답 성능을 평가할 수 있는 벤치마크

마루에 미친자