NLG
:주어진 정보를 기반으로 정보 축약, 보강, 재구성하는것
Text Abbreviation: 핵심만 뽑자
| task | 정의 or 종류 | Application |
|---|---|---|
| Summarization | Abstractive, Extractive | 뉴스 요약 |
| Question generarion | 문서에서 답을 찾을 수 있는 질문 만들기 | Online 학습 도구 및 데이터 증강 |
| Distractor generation | 오지선다에서 오답생성 | 데이터 증강 |
- Abstractive: 없던 문장을 생성하여 요약하기
- Extractive: 문서에서 핵심이 되는 문장으로 요약하기(문장 간의 순의 정하기)
Text Expansion:정보를 추가하자
| task | 정의 or 종류 | Application |
|---|---|---|
| Short text expansion | 정보를 추가해 데이터 길이 늘리기 | 짧은 제목으로 내용생성 |
| Topic to eassay generation | topic를 넣고 에세이가 나옴 | "가족","크리스마스"--> 케빈은 크리스마스에 |
Text Rewriting: 기존 문서를 변형해자, 정답을 생성하자
| task | 정의 or 종류 | Application |
|---|---|---|
| Style Transfer | 긍정<->부정 | 데이터 증강, 말투 변화 |
| Dialougue Generation | 페르소나를 갖은 참여자 대화 생성 | 챗봇 |
Models: SOTA모델을 구성하는 주요 아키텍쳐
- Encoder decoder
- RNN Seq2seq : 알아보기
- Transformer : 밑에 정리
- Copy and pointing: abstractive summarization에서 널리 쓰이는 방법
- pointer를 통해 부정확하게 재현된 사실 세부사항 문제를 완화
- generator 및 coverage mechanism을 통해 OOV(out-of-vocabulary) 단어와 반복을 처리한다
- Gan: 밑에 정리
- Memory network
- recurrent neural networ으로 기반으로 함
- 기호를 ouput하기 전에 큰 외부 메모리에서 여러 번 반복해 읽는다
- 입력 문장들이 고정된 크기까지 메모리에 기록
- 각 메모리 문장과 쿼리(질문)의 연속표현이 계산
- 여러 hope을 통해 답변이 출력
- 메모리층이 반복적으로 쌓이고 각 층의 입력: ouput 메모리 vectior + 이전 층의 입력
- 하나의 hope의 경우, 각 쿼리와 메모리 사이의 일치 확률을 먼저 내부 생성에서 계산 되고 임베딩 공간에서 softmax로 계산된다
- GNN: 데이터를 그래프 형태로 처리하는 데 사용되며, 메시지 전달을 통해 그래프 노드 간의 의존성 정보를 캡처할 수 있음
- 각각 각 노드에 전파될 수 있으며 노드의 입력 순서를 무시할 수 있어 계산 효율성이 더 높다
- 인접노드와 엣시제어 정보를 집계해 반복적으로 업데이트함
더 알아보기
- External Knowledge(외부 지식)
- External Knowledge Based Dialogue System: 외부에서 사용자 발화와 관련된 정보(위키피디아, 뉴스)를 가져와 응답 생성
출처
- External Knowledge Based Dialogue System: 외부에서 사용자 발화와 관련된 정보(위키피디아, 뉴스)를 가져와 응답 생성
더 찾아보기:Model
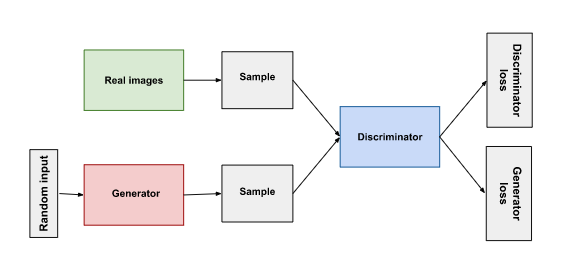
GAN 개요
- generator, discriminator 둘다 neural network
- generator : 그럴듯한 데이터 생성(fake data) => discriminator의 negative examlpe
- output은 discriminator input과 직접적으로 연결
- discriminator: 진짜 데이터와 fake data를 구분하고 그럴듯하지 않는(implausible) 데이터를 만든 generator에게 불이익을 준다
- backpropagation으로 discriminator's classification은 generator의 가중치를 업데이트 할 시그널을 제공함
- 훈련과정
- 초반:generator: 거의 fake data 생성, discriminator :빠르게 가짜라고 말하는것을 배움
- 중반: generator: 점점 discriminator 속이는 결과물 생성
- 후반:discriminator :fake data 와 real data의 차이점을 발견하지 못함
- fake data를 real data로 구분
추후에 할것: Loss functions 읽기
transformer
transformer의 전반적인 구조

-
encoder
- self-attention layer: 인코더가 특정 단어를 인코딩할 때 입력 문장의 다른 단어를 보도록 돕는 레이어
- feed-forward neural network(ffnn): self-attention의 아웃풋이 들어가고, 정확히 동일한 ffnn는 각 위치에 독립적으로 적용됨
-
decoder
- Encoder-Decoder Attention layer: 레이어는 디코더가 입력 문장의 관련 부분에 집중할 수 있도록 도움
세부과정
- 임베딩 알고리즘을 사용하여 각 입력어를 벡터로 변환(크기가 512인 벡터로 임베딩)
- 임베딩은 가장 하단 인코더에서만 일어남
- 512크기 벡터의 리스트로 받으며, 리스트의 사이즈는 하이퍼파라미터로 설정할 수 있음
- 훈련데이터의 가장 긴 문장의 길이
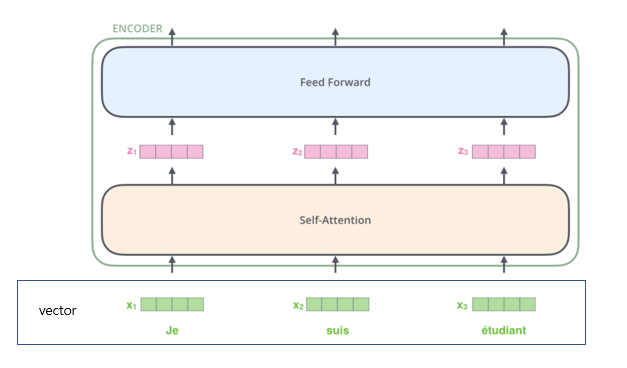
- 각 위치에 있는 단어들은 자신의 경로에 따라 흐른다
- self-attention layer에서는 이러한 경로들 사이로 의존적이다
- feed-forward layer는 의존적이지 않다.
- feed-forward layer에 통과하는 동안 다양한 결고가 병렬로 실행될 수 있다
self-attention
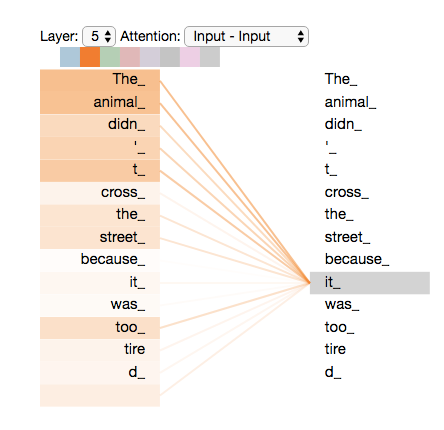
- "it"라는 단어를 인코딩할 때 attention mechanism는 "the animal"에 초점을 맞춤
"the animal"-->"it"으로 인코딩
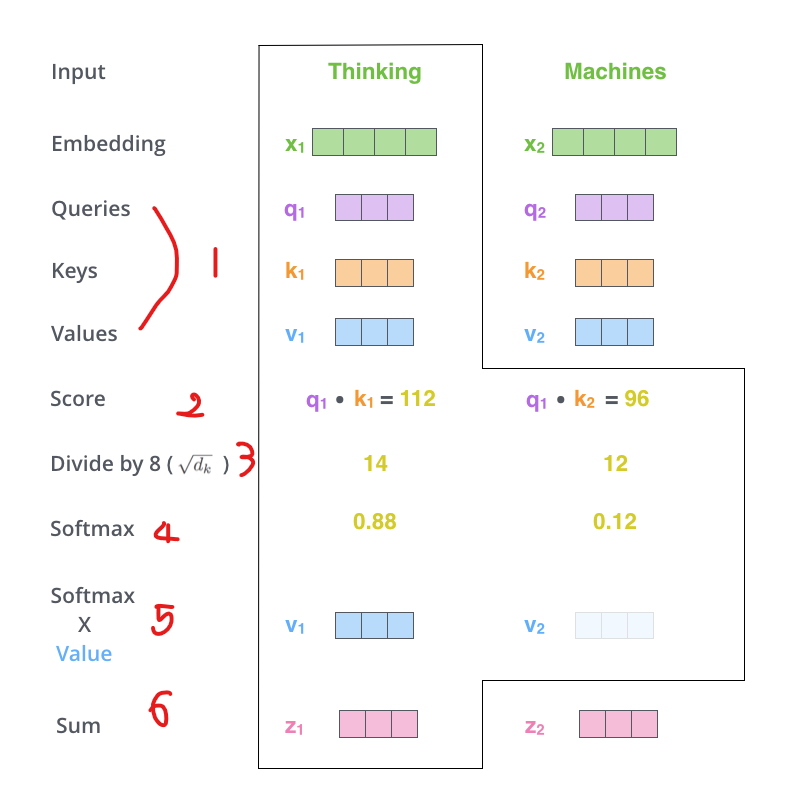
1) 인코더의 입력 벡터로부터 벡터들을 만듦
- 각 단어에서 쿼리 벡터, 키 벡터, 값 벡터를 만듬(size: 64)
- embeding vector/ 입력 출력 벡터 size: 512
- Q,K, V vector는 attention을 계산하고 생각하는데 유용함
2) 점수 계산하기
- 입력 문장의 각 단어에 대해 점수를 매김
- 점수는 특정 위치에서 단어를 인코딩할 때 입력 문장의 다른 부분에 얼마나 초점을 맞출지 결정
- query vector X 각 단어의 Key vector
- ex) 위치 1에 대한 단어를 self attention은 한다면,
q1 X k1 (next) q1X k2
- ex) 위치 1에 대한 단어를 self attention은 한다면,
3 & 4) 나누기 및 softmax
- 8로 나눠줌(64에 루트 쓰인 값 ==> 더 안정적인 기울기 제공)
- softmax 해줌 --> softmax로 점수롤 정규화해줌(positive, 합계 1)
- softmax 점수는 각 단어가 이 위치에서 얼마나 표현될지(express) 결정한다
5) value vector X softmax score
- 초점맞추고자하는 단어는 단어의 값을 그대로 유지
- 관련없는 단어는 값 내림 (ex * 0001)
6) 가중치 value vector들을 합산
- (첫번째 단어의) 그 위치에서 self-attention 층의 output
실제는 이 과정보다 더 빠르게 계산됨 --> Matrix 형태
Matrix Calculation of Self-Attention
1) Query, Key 및 Value 매트릭스를 계산
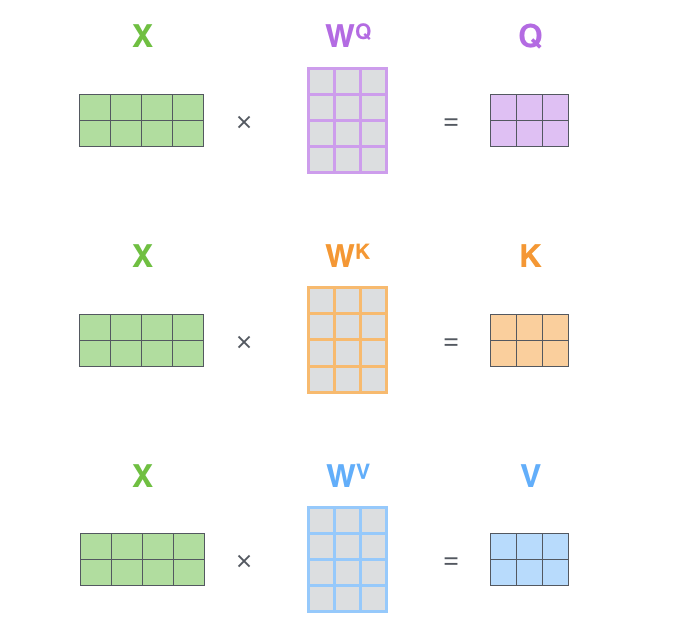 - embeding을 매트릭스X로 하고 가중치 매트릭스(WQ, WK,WV)를 곱한다.
- embeding을 매트릭스X로 하고 가중치 매트릭스(WQ, WK,WV)를 곱한다.
2) 나머지 단계를 한번에 계산한다
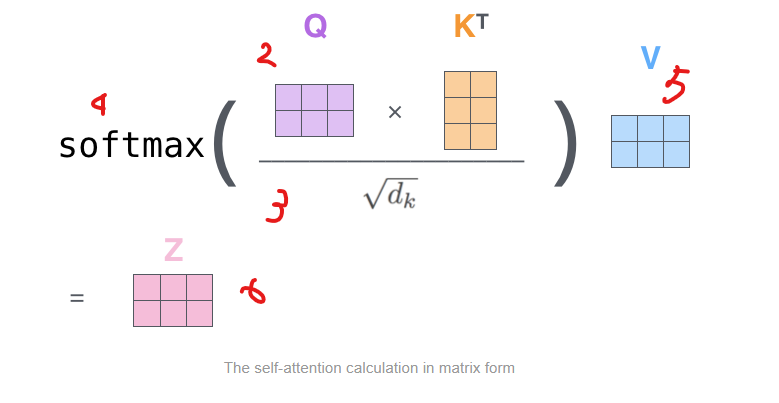
Many Head
- “multi-headed” attention 매커니즘을 추가 후 self- attention이 강화됨
1) 다른 위치에 집중할 수 있는 능력이 확대됨
- Z1은 모든 인코딩이 조금씩 있지만, 실제 단어 자체가 거의 차지하고 있다
- ex) The animal didn’t cross the street because it was too tired” 에서
it --> animal
- ex) The animal didn’t cross the street because it was too tired” 에서
2) attention 층에 “representation subspaces”을 제공
- Query/Key/Value weight matrices 는 한개가 아닌 여러개 제공(8개)
- 이러한 세트들은 무작위로 초기화한 후에 훈련 후 각 세트는 입력 embeding을 다른 표현 representation subspaces에 투영하는데 사용된다
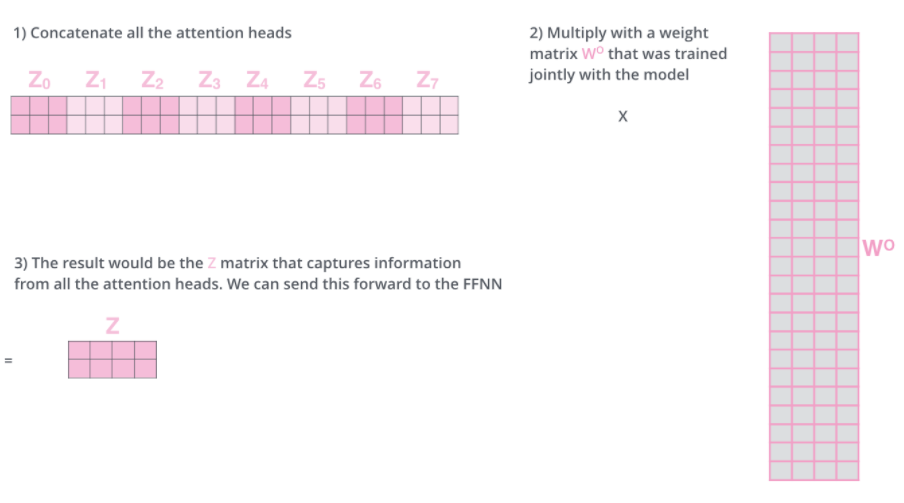
- 8번 같은 self-attention 계산한다면 Z matrix는 8개가 나옴
- 8개의 Z matrix를 계산 X 가중치 WO matrix
positional Encoding
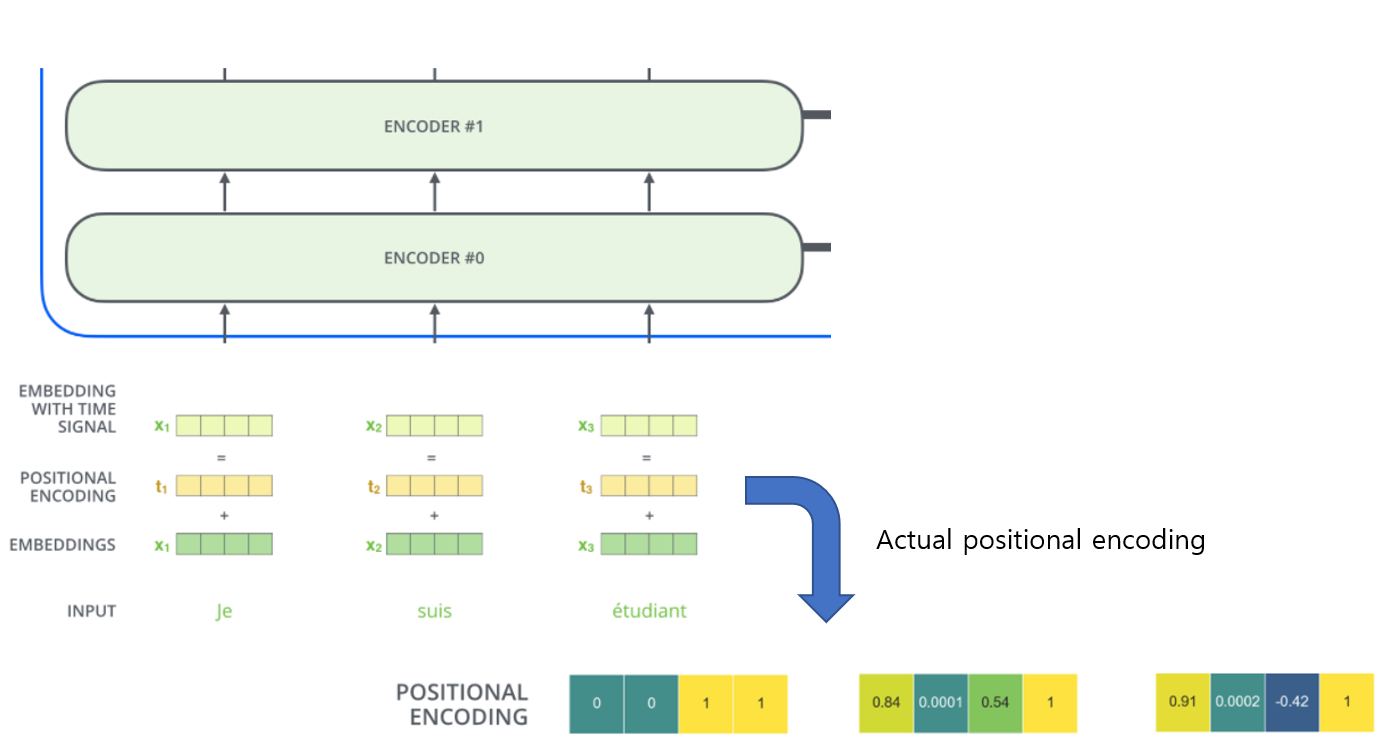
- 입력 embeding에 위치 벡터를 추가함
- 각 단어의 위치 or sequence에서 다른 단어 사이의 거리를 결정하는데 도움을 줌
- Q/K/V vector에 투영된 embeding 벡터
Residual
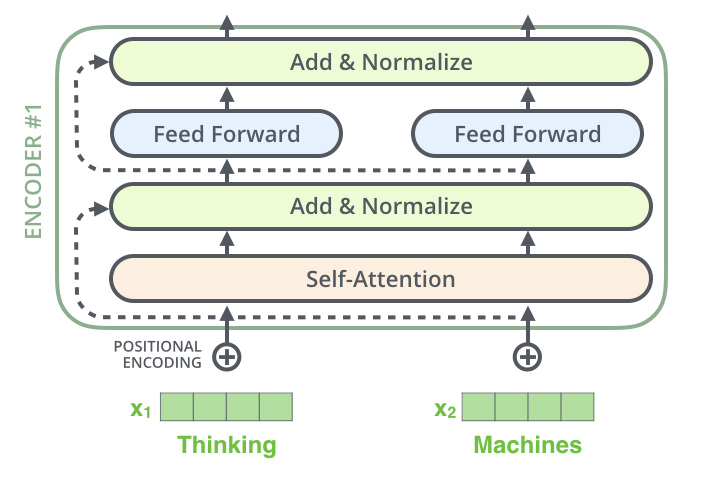
- self-attention, ffnn은 그 주위에 residual connection있으며, 이 후에 normalization layer에 들어간다
- decoder 또한 마찬가지임
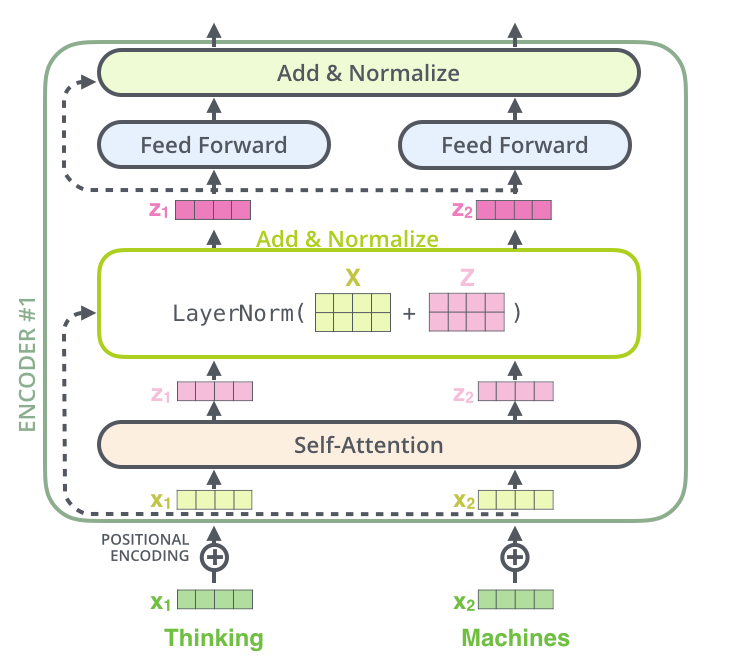
Decoder
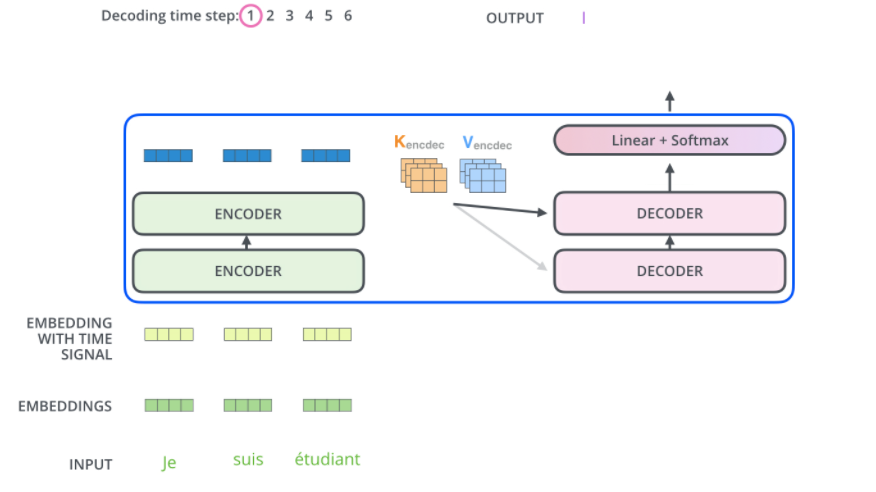
- top encoder의 output이 attention vectors K,V로 변환
- attention vectors K,V는 디코더의 “encoder-decoder attention”에서 사용
- 디코더의 입력 시쿼스의 적절한 위치에 집중할 수 있게 도와줌
- 디코더 출력이 완료했다는 특수 기호가 나올때까지 단계를 반복함
- 디코더에도 위치 인코딩을 디코더 입력에 추가한다.
Linear and Softmax Layer
- 단어로 바꾸는 것 수행
- Linear layer는 simple fully connected neural network이다
- decoder에서 만든 벡터를 logits vector라는 훨씬 큰 벡터에 투영한다
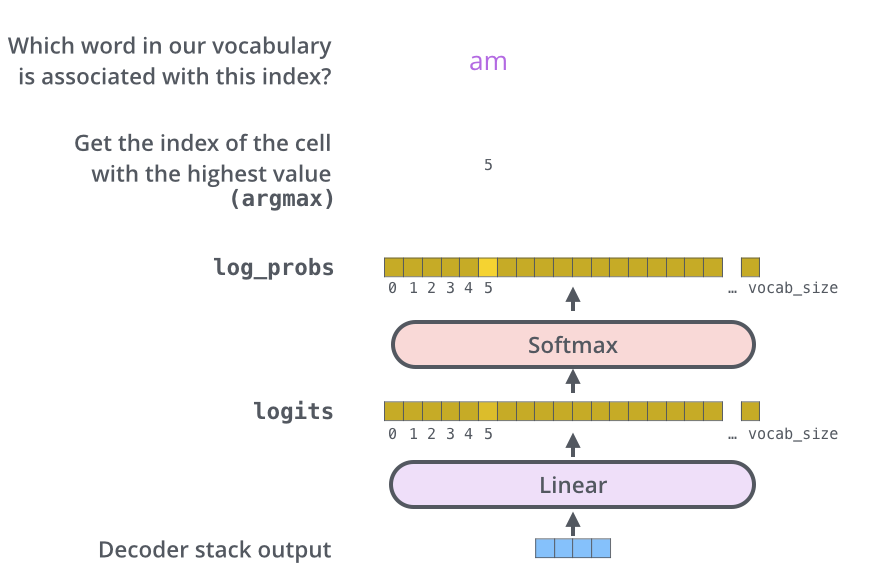
가정) 모델이 훈련 데이터셋에서 학습한 1000개의 영어단어 알고있다
- decoder에서 만든 벡터를 logits vector라는 훨씬 큰 벡터에 투영한다
- logits vector는 10000개 셀
- 각각의 셀은 각각 단어의 점수에 상응
- softmax 층은 점수를 확률로 바꿈
- 가장 높은 확률의 셀이 선택되고, 셀과 관련된 단어가 ouput으로 생성

마루에 미친자