NLG :summarization
1. extractive summarization task
(1) 해결하고자 하는 문제는 무엇인가?
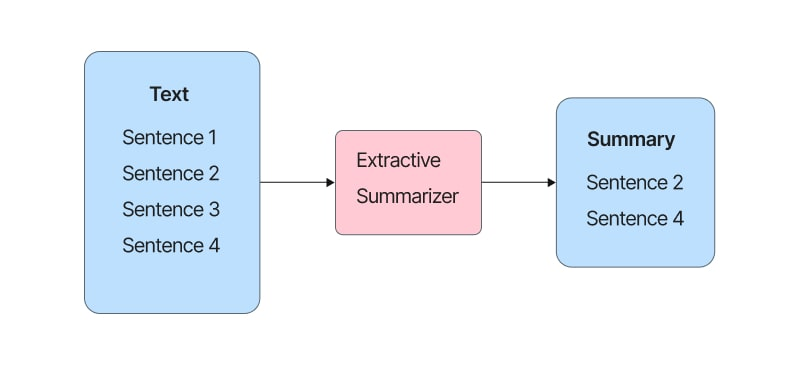
- 정보가 방대하지면 요약의 중요성이 대두되고 있다.
- 요약 중에서 extractive summarization는 문장 간의 순위를 정하여 주어진 문서에서 요약을 잘 나타내는 단어나 문장으로 요약하는 작업을 한다.
그림 출처
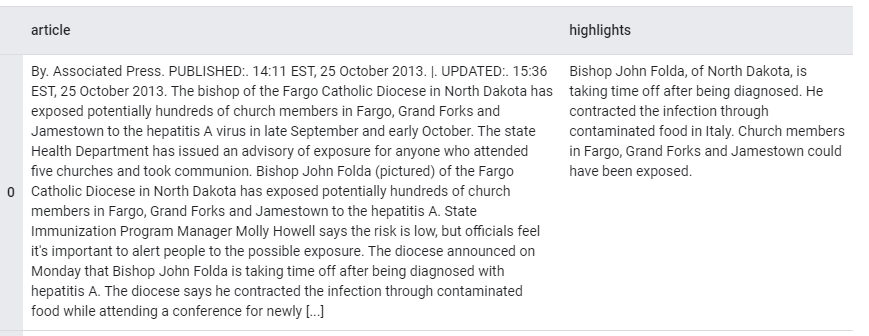
(2) 데이터셋: CNN/Daily Mail
- text summarization을 위한 익명화되지 않은 데이터셋
- article: 요약할 문서로 사용되는 뉴스 기사의 텍스트
- highlights: 텍스트의 요약문
- train : 286,817 , validation : 13,368 , test : 11,487
- 다운로드 크기: 558.32MiB 데이터 집합의 크기:1,27GiB
FeaturesDict({
'article': Text(shape=(), dtype=tf.string),
'highlights': Text(shape=(), dtype=tf.string),
})
(3-1) SOTA 모델: HAHSum
주요 키워드: constituency parse, oracle summary

- 1) 문서에서 문장을 선택
2) constituency parses 기반으로 한 가능한 요약 문장들을 식별
3) 신경망 모델로 그들의 요약 점수를 매겨 최종 요약 문장을 선택- 원본 문서와 해당 문장을 인코딩 다음 요약할 문장 세트를 순차적으로 선택
- 의미와 문법을 유지하기 위해 요약 option이 각 문장마다 있다
- 신경 모델은 문서와 문장 디코더의 문맥을 고려한 요약문장을 점수를 매기고 선택
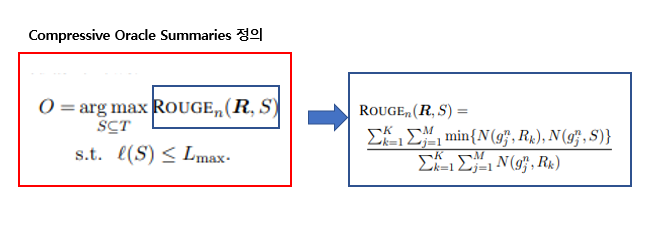
- for learning
: oracle extractive-compressive summary를 구성
constituency parsing
: 구성 요소라고도 알려진 하위 구문으로 분류하여 분석하는 과정
- 하위 구문들은 NP (명구)와 VP (동사구)와 같은 문법의 특정 범주에 속합니다.
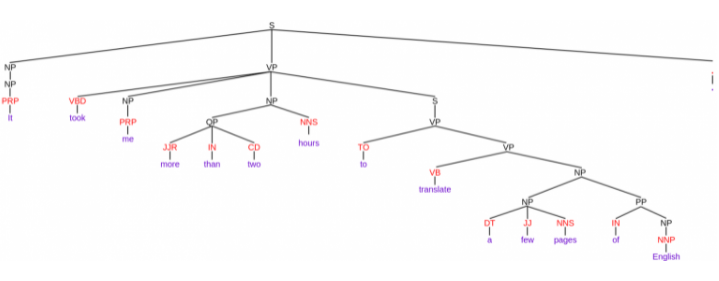
보라색: 문장에 쓰여진 단어, 빨간색: POS tag, 검은색: constituent(구성 성분) - 문장이 어떻게 sub-phrases로 나누어졌는지 확인 가능합니다.
- constituent 마다 다르게 태그되어있음 ex) VP -verb phrase
출처
oracle summary
(3-2) SOTA 모델: Longformer
주요 키워드: Sliding window, Dilated Sliding Window, Global Attention
- Transformer에서 인풋 시퀀스 길이의 제곱에 비례하여 메모리와 계산량이 늘어납니다. BERT 또한 512로 시퀀스를 제한하는 등 긴 문서에 대해 처리하기 힘들다는 문제가 있습니다.
- 이런 문제를 개선하고자 인풋 시퀀스의 길이에 선형적으로 비례하는 계산량을 가진 attention 매커니즘을 제안하였습니다.
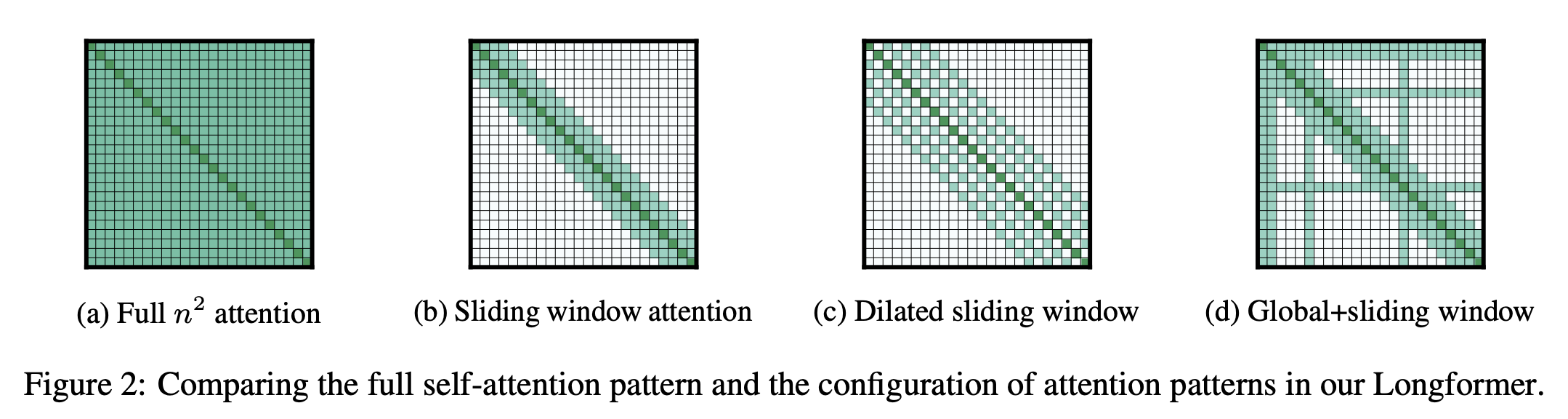
Sliding window
: window(w) 만큼의 토큰에만 attention 기법을 사용하여 계산량을 줄입니다.
- 멀리 떨어진 토큰은 attention을 계산하지 않습니다.
- layer를 여러 개 쌓으면 receptive field가 넓어짐
- L개의 층을 쌓았을 때: receptive field = L* w
Dilated Sliding Window
- d만큼 건너 뛰면서 w에 해당하는만큼 attention을 적용합니다
- Sliding window와 Dilated Sliding Window를 적절히 섞어가며 사용합니다
- receptive field = L w d
Global Attention
- BERT의 [CLS] 같은 special token을 사용합니다
- special token는 전체 token에 대한 attention을 구할 필요가 있습니다.
- special token에 한해 glbal 하게 attention을 구하는 방식을 취합니다
- 별로 많지 않기에 global attention이 별로 크지 않음

마루에 미친자
4개의 댓글

2022년 2월 23일
HAHsum 모델의 constituency parsing을 보니 한글도 저런식으로 적용이 될 수 있을까 궁금함이 생기네요. 한글 nlp도 좀 공부를 해봐야겠다는 생각이 듭니다. longformer는 트랜스포머의 시퀀스 길이 제한 때문에 선형비례식을 이용하자는 아이디어를 가진 모델이군요. 저번에 다른블로그에서 본 푸리에 변환 말고도 트랜스포머의 계산량을 보완하는 다양한 아이디어가 있는 것 같습니다.
답글 달기

2022년 2월 23일
Longformer에 대해서 잘 읽었습니다 BERT 긴문서에 처리하기 힘들다고하는게 궁금해서 찾아보니 512 토큰 이상의 긴 문서를 처리하기 위해서는 512 토큰 이하로 문서를 분할하여 처리하기 때문에 길이가 긴 문서에 대해서는 낮아진다고 하는군요 아직 왜 512 시퀀스로 제한하는지도 모르겠어서 한참 공부해야 할것 같네요
답글 달기

2022년 2월 23일
생각보다 과제하면서 트랜스포머를 접하는 부분이 많은 것 같습니다. 하지만 길이 제한(?)이란 명확한 단점이 있는 모델이기 때문에 보완 방법을 적용한 여러 버전이 생겨났는데 또 어떤 게 있는지 찾아봐야겠습니다. Oracle Summary에 대해서는 저 또한 검색 했을 때 명확한 설명을 찾지 못하였기 때문에 주말에 좀 더 찾아보고 공유하도록 하겠습니다.
답글 달기
저도 HAHSum 모델을 SOTA 모델로 선정하였는데 논문을 읽어도 자세하게 이해가 안되던 부분을 기록하셔서 이해하는데 도움이 되었습니다.