Contextual Embedding
모델이 문맥에 맞게 Vetor 구하기
Word2vec의 경우에는 의미를 vector 시킬 수 있으나, 여러 의미를 vector로 표현하기 힘듦
예) 눈--> 신체 눈, 흰 눈이 있지만 fixed word 임베딩으로 아웃풋이 나옴
Contextual Embedding의 경우에는 하나의 단어를 문맥에 맞게 여러가지 vector로 표현가능
Contextual Embedding 종류
ELMO (Embedding from Language Models)
- biLSTM
: 원래는 forward으로만 진행했지만 Backward(역방향)도 같이함
한 방향으로만 This 다음에 무엇이 올지 예측할때 forward weight와 backward weight를 concat - Deep representation(liner combination of 2 layers)
원래는 LSTM을 쌓고 마지막 가중치를 가지고 어떤 임베딩이 냈는 방식이였는데, 여기서는 두개를 가지고 한다
why? 첫번째 layer 경우에는 syntax task에서 (개체명 인식)
두번째 layer 경우에는 semantic task에서 (문장 유사도 확인)
liner combination: 알파나 베타같은 가중치을 줘서 두개의 영향력을 분배시켜서 두개다 가져가겠다 - Pre-trained Language Model
다음 단어 예측 문제로 pre-trained 함
Transformer (몰랐던것 위주로 정리)
- LSTM의 경우 Long term dependency, 병렬 학습이 불가능하다는 단점이 있음
- sentence가 들어오면 sentence와 sentence를 곱하여서 어탠션을 만듦
-> 긴 문장이 오더라도 문장에 있는 모든 단어들과 같이 계산함 - attention: 레이어에서 해당 단어가 어떤 단어를 주목하고 있는지 연결점이 있는지에 대한 매트릭스
- 단어와 단어 사이의 매트릭스로 병렬적으로 연산
- 매트릭스 곱을 몇개하더라고 GPU에 넣어서 한번에 계산이 가능
- 시간 단축
- input 임베딩 + positional encoding
- input 임베딩:mecab이라는 룩업테이블 생성(ex. '나'--> token_id:0, demension embedding: vector)
- positional encoding: 사인함수로 표현
- Wq, Wk, Wv : weight에서 생성되는데 역적파할때 학습이 되고, 업데이트가 됨
- V: 어탠션을 만들기 위한 값으로 V매트릭스에 확률값(소프트 맥스 취한값)을 곱한다는건 weight를 주는것
-> 키 쿼리를 봤을때 중요한 것을 벡터를 살려두고 중요하지 않는것은 죽이는것 - 마지막에 attention들을 concat하고 weight매트릭스 곱하는 이유: 원하는 demension을 맞추기 위해
BERT
- transformer encoder로 구성(base:12, Large:24)
- input layer: Token Embedding +sentence Embedding + positional Embedding
- Token Embedding: : tokenize하면 룩업데이블이 생성-->token_id
- sentence Embedding: : 문장 a,b를 구분하기 위해서:0, 1
- positional Embedding(positional 인코딩과 다름): 0~10에 있는 벡터로 표현
- Attention으로 양방향
- pre_train의 경우
- 마스크된 랭귀지 모델: 토큰들에 15%를 mask함 --> 의미를 학습 O
- NSP: 50%는 그냥 냅두고 랜덤하게 바꿔주어 해당 문장과 다른 문장이 연결이 되는지 classfication 함(not next/ next)
Reference: The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
BERT
- default 배열 in transformer:6 encoder layers, 512 hidden units, 8 attention heads
- bert 배열: feedforward-networks (base -768, large-1024 hidden units), more attention heads (base -12 , large-16 respectively)
Model input & output
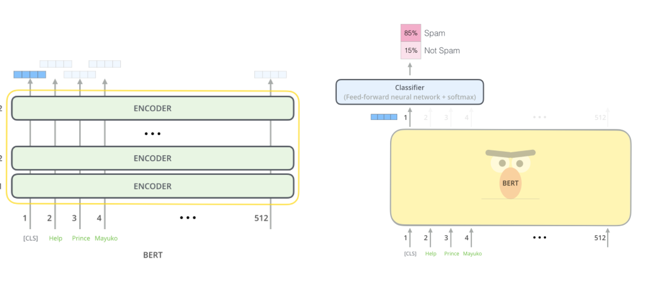
- bert는 시퀀스의 단어들을 스택에 계속 이동하는 input으로 여기며, 각 layer는 self-attention이 적용되고, feed-forward network을 통해 결과를 전달한 후에 다음 인코더로 넘긴다
- 각 위치에서 768크기(BERT Base)의 벡터를 출력함--> 벡터는 classifier의 input
- classifier이 single-layer neural network여도 좋은 성과를 냄
A New Age of Embedding
- Word2Vec는 semantic or syntactic하게 잘 표현하는 방식으로 단어를 벡터을 사용
- Word2Vec or GloVe는 pre_train
- but, 문맥에 상관없이 벡터로 표현이 됨 예)stick-->나뭇가지, 지팡이, 꼬챙이
==> contextualized word-embedding 탄생
ELMO
- ELMO는 각각 단어를 임베딩하기 전 전체 문장을 본다
- 특정 작업에 훈련된 양방향 LSTM(biLSTM) 을 사용하여 임베딩을 만든다
- 대용량 데이터셋으로 훈련된 ELMo LSTM은 언어를 다루는 다른 모델의 요소로 사용가능하다
- pre-trained:
- 다음 단어를 예측하는 train(Language Modeling)작업을 통해서 언어를 이해합니다
- 레이블이 필요없는 방대한 양의 텍스트 데이터로 수행
- 언어 패턴을 인식 예) hang --> out > camera
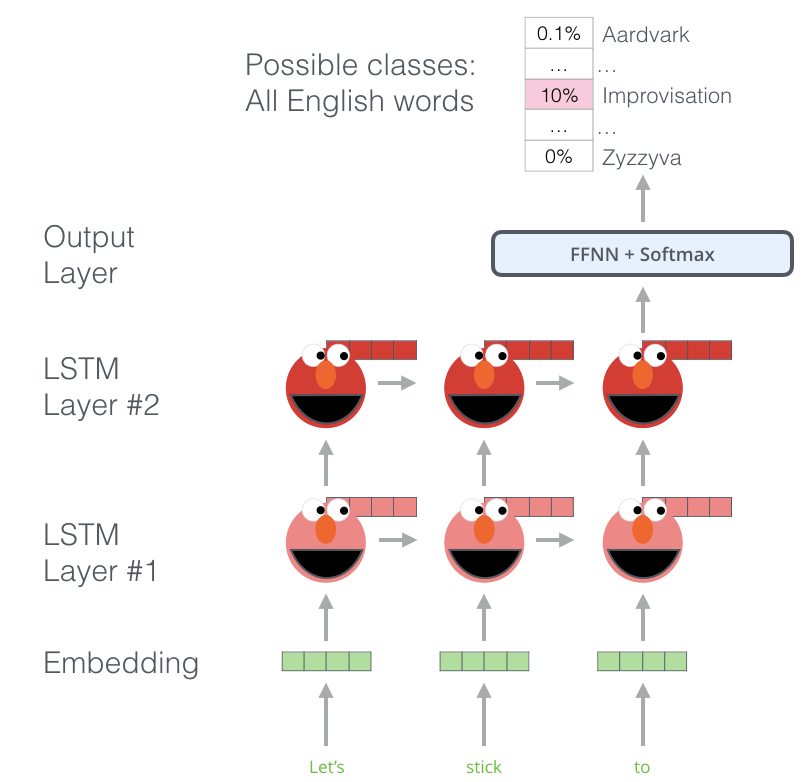
- pre-trained:
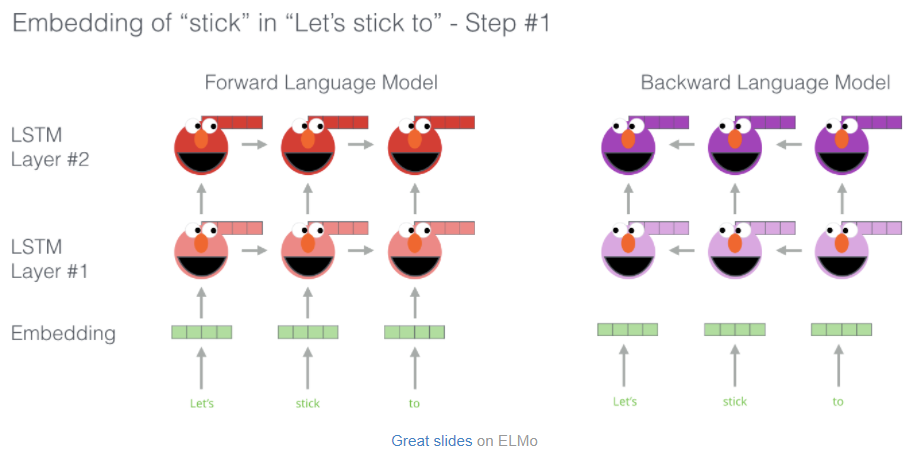
- bi-directional LSTM: 다음 단어뿐만 아니라 이전 단어의 의미도 가짐
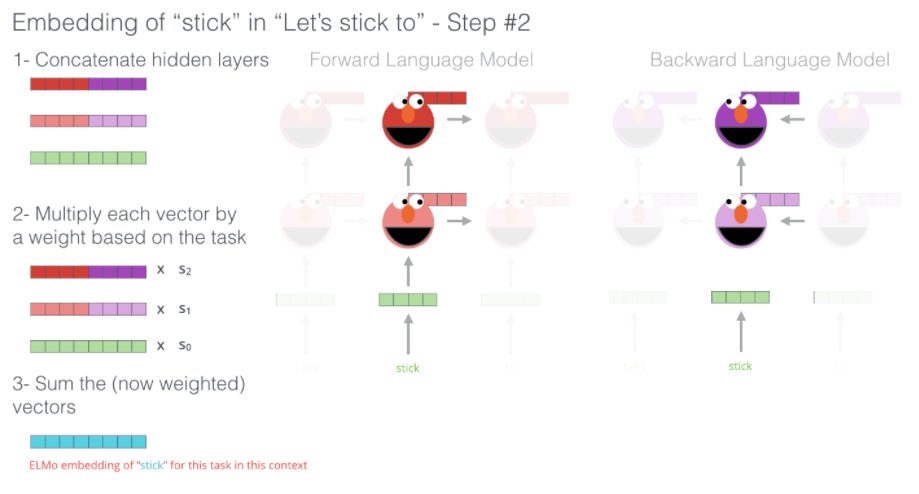
- hidden state를 그룹화하여 contextualized embedding 제공
BERT: From Decoders to Encoders
Masked Language Model
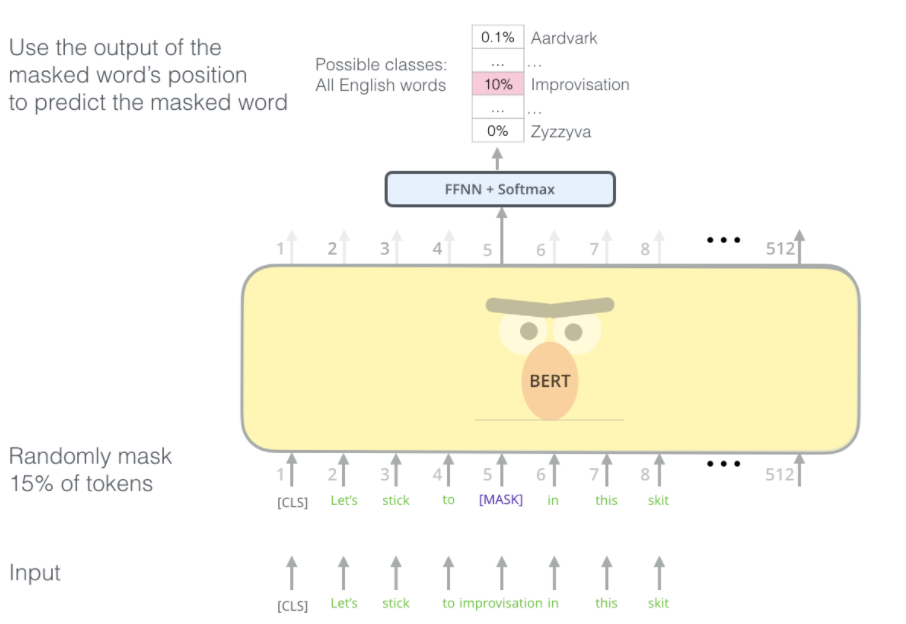
- input의 15%는 masking
- 이외에도 fine-tuning을 개선하기 위해 단어를 섞음
- 단어가 다른 단어로 대체하고 해당 위치의 정확한 단어를 예측하도록 하였다.
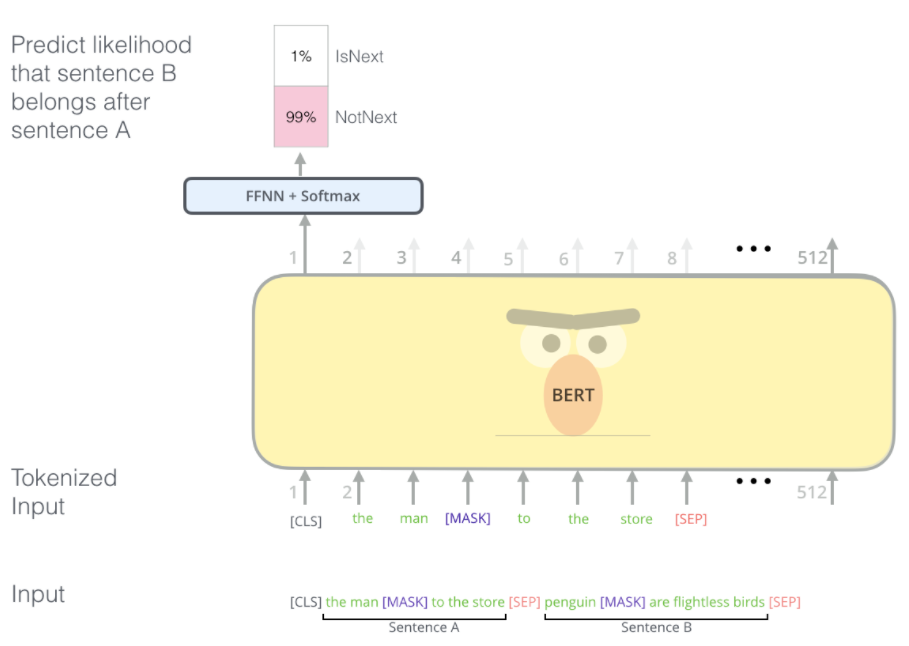
Two-sentence Tasks
- 단어가 다른 단어로 대체하고 해당 위치의 정확한 단어를 예측하도록 하였다.
- 여러 문장 간의 관계를 더 잘 처리하도록 하기 위해서 pre-training process 포함된 task
- A 문장 다음에 B문장이 나올 가능성이 있는가? IsNext/ NotNext
Task specific-Models
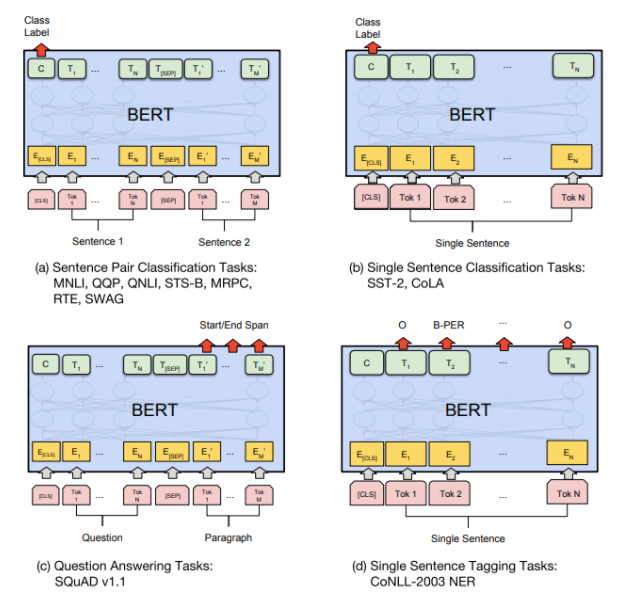
BERT for feature extraction
-
pre-trained BERT는 contextualized word embeddings를 만들 수 있음-> 기존모델에 제공
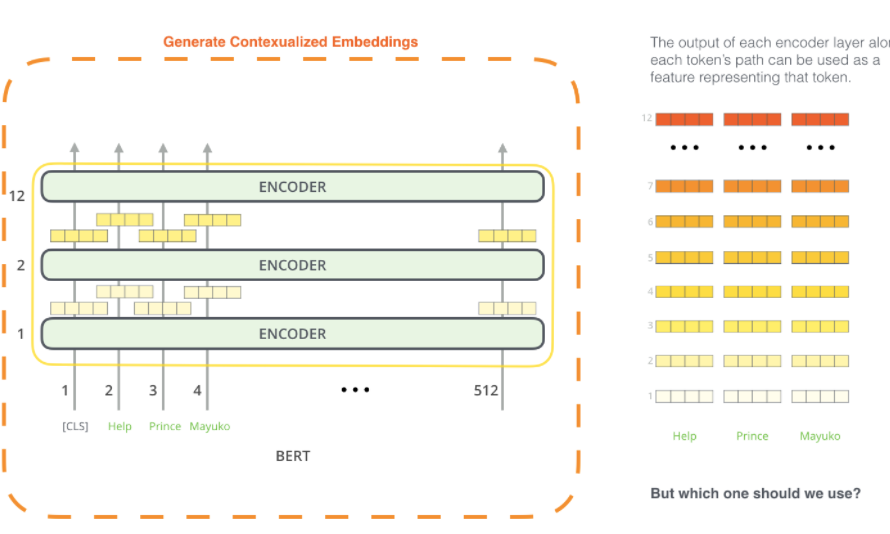
-
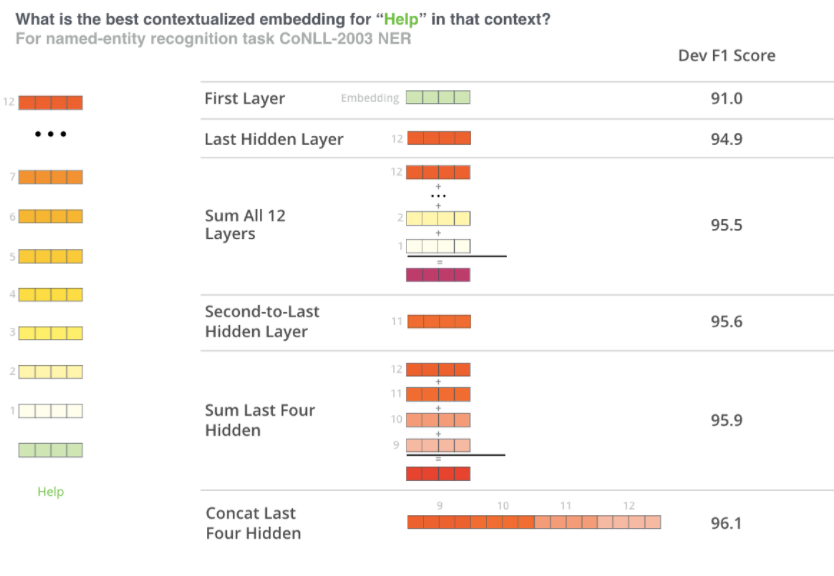
어떤 벡터가 best contextualized embedding인지는 업무에 따라 다르다.

마루에 미친자