본인 아이디 및 닉네임: ayi4067
게시글 URL: https://velog.io/@ayi4067/Week-3-3.-report
Attention Is All You Need
1. Introduction
Recurrent neural network는 기계 번역, 언어 모델링 같은 문장 모델링 및 번역에서 최첨단 기술(SOTA)을 확립됐으나 훈련할 때 병렬화가 되지 않아 이런 메모리 제약에 의해 샘플 간 배치화를 제한하여 긴 길이의 시퀀스를 처리할수록 문제가 된다.
- factorization tricks으로 상당한 개선 되었으나 근본적인 sequential computation 제약이 있다
Attention mechanism은 시퀀스 모델링과 번역 모델 필수적인 부분이 되었으나 몇몇 경우를 제외하곤 recurrent network와 결합하여 사용한다.
이 논문에서는 Attention mechanism에 전적으로 의존하는 Transformer를 제안하였다
- transformer는 더 많은 병렬화 및 번역의 품질에서 새로운 SOTA로 도달할 수 있었다
2. Model Architecture
encoder-decode 구조를 가진다
- 각각 self-attention과 point-wise fully connected layers을 스택된 구조
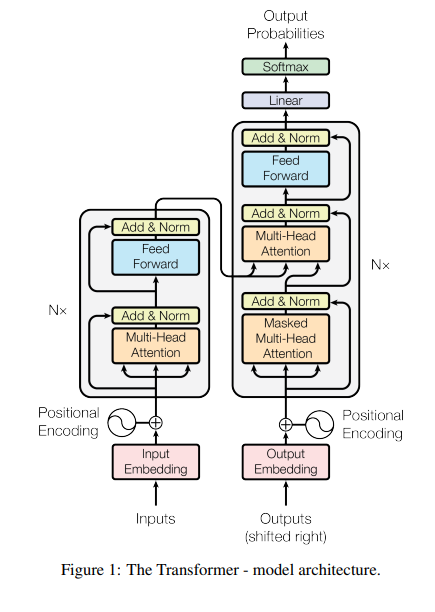
2.1) Encoder
- 스택된 동일한 6개 layer로 구성
- sub-layer
1) multi-head self-attention
2) position-wise fully connected feed-forward network- sub_layers에 residual connection 사용 -> normalization 층이 따르도록 구성
- output 차원: 512
2.2) Decoder
- 스택된 동일한 6개 layer로 구성
- sub-layer
1.2) Encoder의 sub-layers
3) 인코더의 output에 multi-head-attention 수행하는 layer - sub_layers에 residual connection 사용 -> normalization 층이 따르도록 구성
- self-attention layer 수정
- Masking: i 위치의 예측을 위해서 i보다 이전에 있는 단어들만 의존하도록
2.3) Attention
: query와 key-value pair을 output과 매핑하는 것
- query, key, value 모두 vector
- output은 value의 가중 합으로 계산되며, 각 value에 할당된 가중치는 쿼리와 해당 키의 compatibility function에 의해 계산
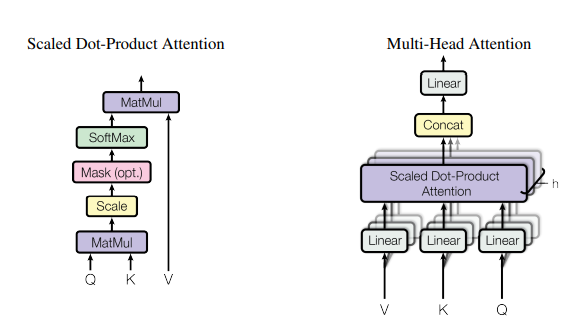
(1)Scaled Dot-Product Attention
- input: query와 key의 dimension, value의 dimension vector
- 계산
1) query * 모든 Key
2) key의 dimension의 루트를 나누기
3) softmax 적용- 실제로 query의 집합(matrix Q), matrices K,V 가 동시에 계산된다
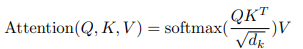
- 실제로 query의 집합(matrix Q), matrices K,V 가 동시에 계산된다
(2)Multi-Head Attention
1) 쿼리, 키, 벨류를 각각 dK, dk, dv 차원으로 변환하는 서로 다른 h개의 학습 가능한 linear projection
2) 각각의 다른 projected version에 대해 병렬적으로 수행
3) projected version에서 서로 다른 dv 차원 output를 얻고 그 결과들을 concat
4) linear projection 하여 최종 결과 벡터 얻음

2.4) Position-wise Feed-Forward Networks
- encoder, decoder 각각 위치에서 독립적으로, 동일하게 적용
- 2개의 linear transformation과 그 사이에 ReLU 함수로 구성
- linear transformation은 여러 위치에 동일하지만 layer 간들의 다른 파라미터 사용
2.5) Embeddings and Softmax
- 학습 가능한 임베딩을 사용함
- input token 과 output token을 dmodel 차원의 벡터로 변환하기 위해서
- 학습 가능한 inear transformation 과 softmax 함수를 사용
- 디코더 output을 예측 가능한 next-token 확률로 변환하기 위해
- 두 개의 임베딩 층과 pre-softmax linear transformation 사이에 같은 가중치 매트릭스를 공유
2.6) Positional Encoding
- recurrence, convolution 없기에 모델의 시퀀스의 순서를 사용하기 위해 토큰의 절대적인 도는 상대적인 정보를 더해야 한다.
- 인코더, 디코더 가장 하단에서 input 임베딩 + positional encodings
- 둘이 더할 수 있는 이유: positional encoding의 차원 = dmodel 차원
- sinusoidal version 선택
3) Why Self-Attention
self-attetion VS recurrent, convolution layer
- 가변 길이의 representation을 동일한 길이의 다른 시퀀스 representation 매핑하는 것을 비교
- desiderata.
1) 총 계산 복잡도
2) 병렬화할 수 있는 계산량 (Sequential Operations)
3) 네트워크에서 장거리 의존성 사이의 경로 길이 - 결과

- complexity per Layer : self-attention > recurrent, convolution layer
- Sequential Operations: self-attention > recurrent layer
- Maximum Path Length: self-attention > recurrent, convolution layer
- self-attention은 해석 가능한 모델을 산출함
4) Training
- Data :WMT 2014 English-German dataset, WMT 2014 English-French dataset
- Hardware and Schedule:h NVIDIA P100 GPUs
- base: 100,000 steps /12 hours
- big: 300,000 steps / 3.5 days
- Optimizer: Adam
- Regularization:
- Residual Dropout: 각 sub_layer의 ouput을 dropout적용 , 임베딩과 위치 인코딩의 합에도 적용
- Label Smoothing
5) Results
5-1) Machine Translation
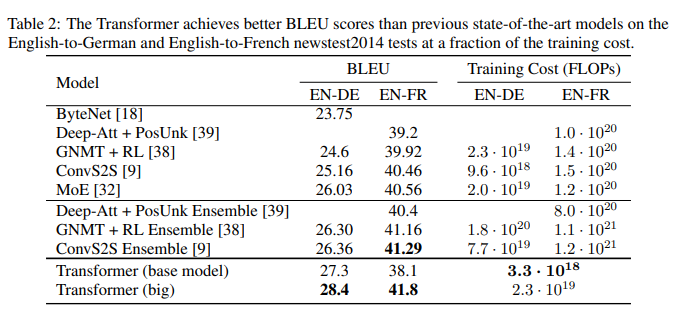
- WMT 2014 English-to-German translation task
- big transformer model이 이전에 best 모델을 능가함
- base model도 이전 model 및 ensemble을 능가함
- WMT 2014 English-to-French translation task
- big transformer model은 이전의 모델들을 능가함
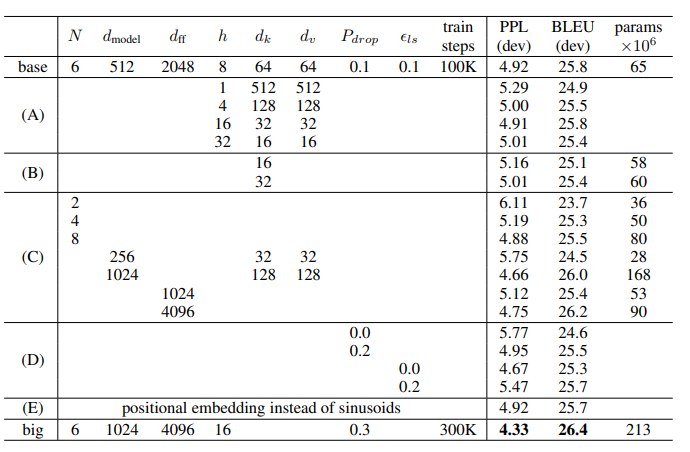
5-2) Model Variations
- base model을 파라미터를 다르게 함
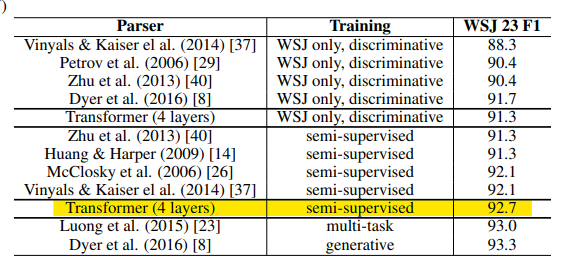
5-3) English Constituency Parsing
- Transformer가 다른 작업에서도 일반화할 수 있는지 평가하기 위해 영어 constituency parsing 실험하였다
6) Conclusion
- recurrent layers를 multi-headed self-attention로 대체하여 전적으로 attention 을 기반으로 한 Transformer을 제시하였다
- Transformer은 번역 작업에서 recurrent 또는 convolutional layer로 한 architecture보다 상당히 빠르게 훈련됨
- WMT 2014 English-to-German, WMT 2014 English-to-French translation tasks에서 새로운 SOTA로 성취
- 이미지, 오디오, 비디오 같은 다른 작업에도 적용할 계획임

마루에 미친자