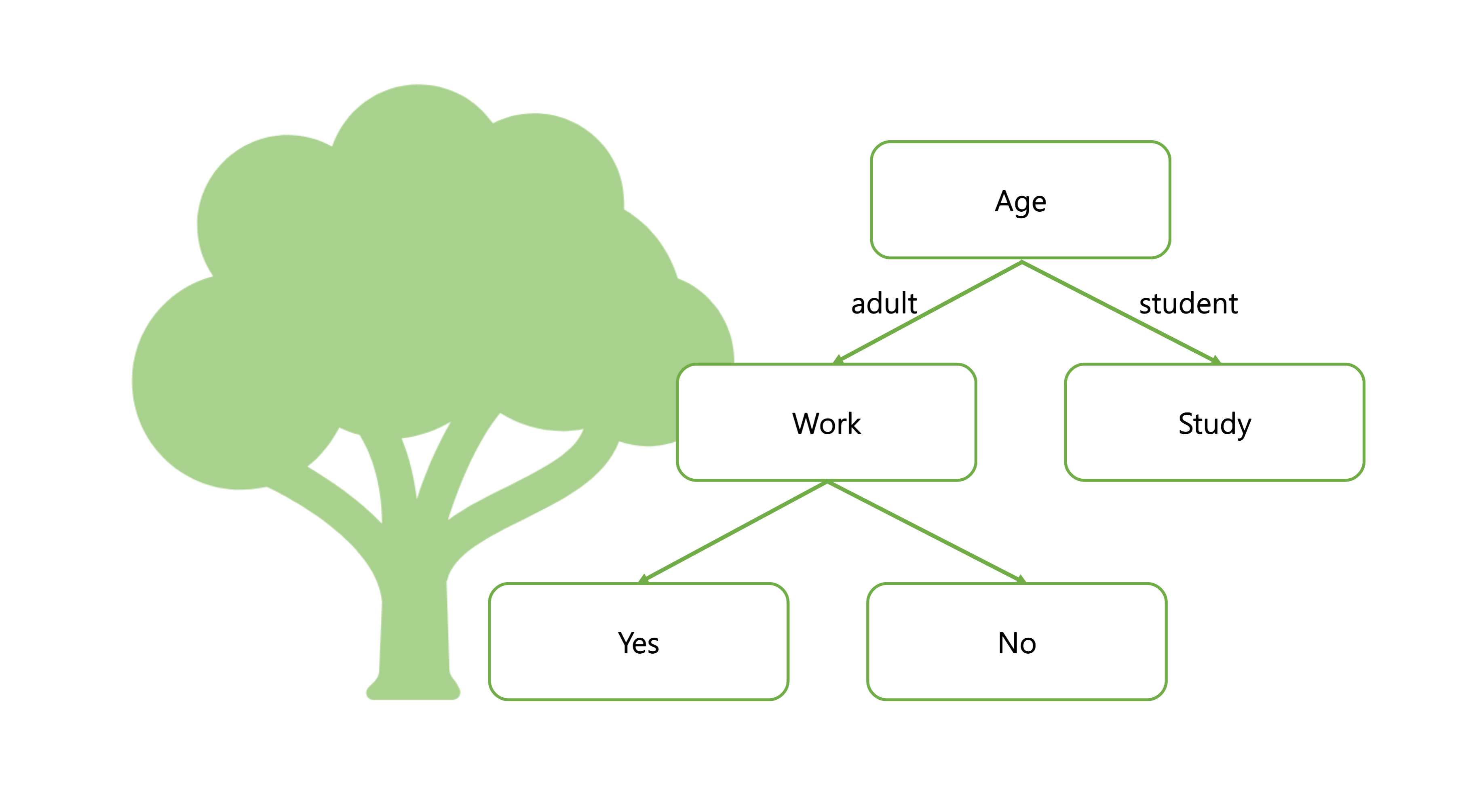
Decision Tree
- 스무고개하듯이 예/아니오 질문을 반복하며 학습한다.
- 특정 기준(질문)에 따라 데이터를 구분하는 모델이다.
- 분류와 회귀에 모두 사용가능하다.
- 직관적이다.
- 과대적합이 발생하기 쉽다.(튜닝이 필요함. 사전가지치기)
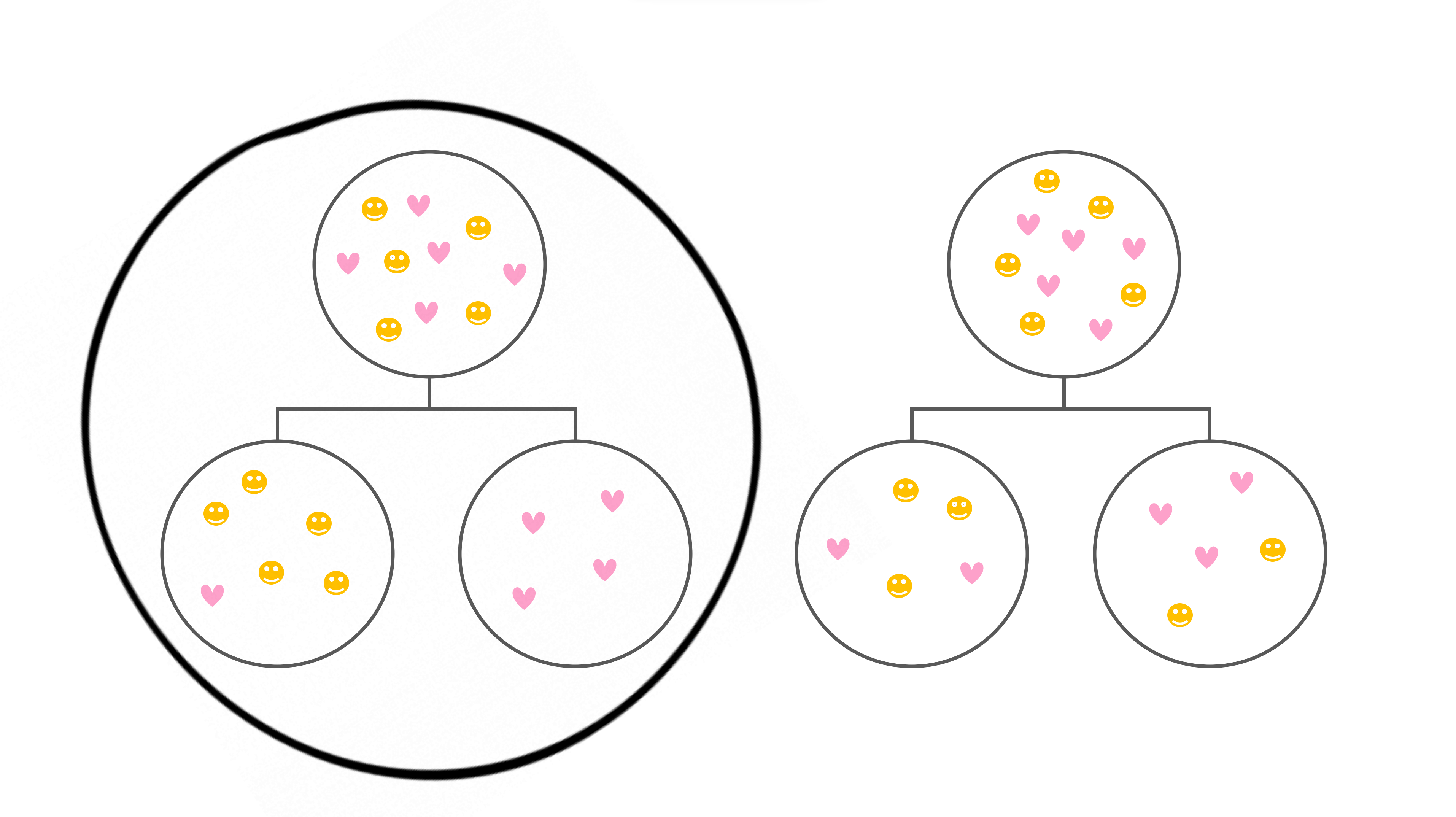
Decision Tree의 의사결정 방향
→ 불순도가 낮아지는 방향
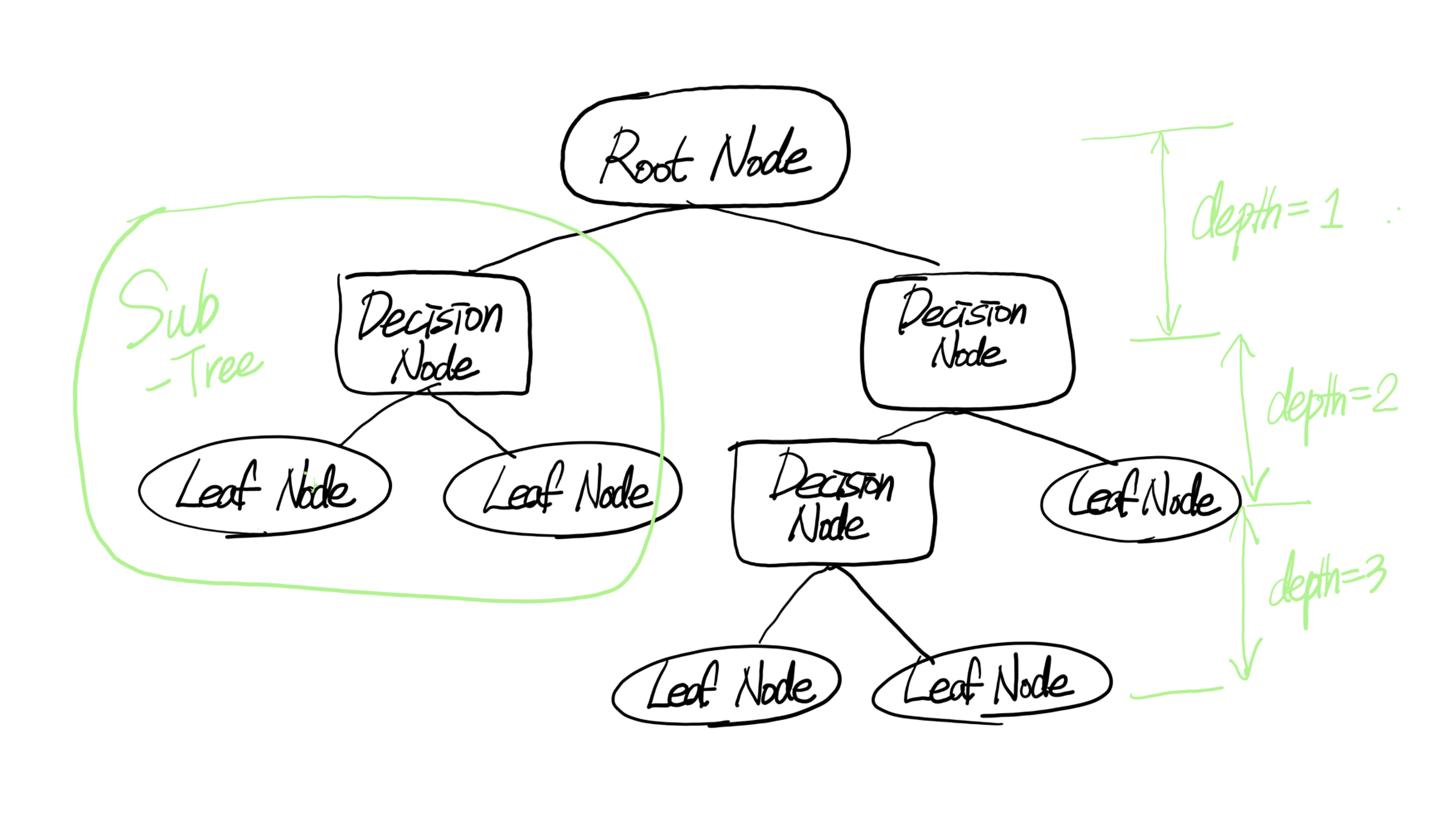
Root Node / Decision Node / Leaf Node / depth / Sub Tree
Decision Tree 사용법
필요한 라이브러리 import
from sklearn.tree import DecisionTreeClassifier결정트리 분류 모델 객체 생성
clf = DecisionTreeClassifier(하이퍼파라미터, random_state)하이퍼파라미터(HyperParameter)
- criterion : 불순도 측정 방법(gini, entropy)
- max_depth : 트리의 최대 깊이, 값이 클수록 모델의 복잡도 증가.
- min_samples_split : 노드를 분할하기 위한 최소 샘플 수. 크게 설정될수록 분할되는 노드가 많아짐. 과대적합 가능성 증가.
- min_samples_leaf : 리프노드가 가져야할 최소 샘플 수. 작게 설정될수록 분할되는 노드가 많아짐. 과대적합 가능성 증가.
- max_leaf_nodes : 리프노드의 최대 개수. 작게 설정될수록 분할되는 노드가 많아짐. 과대적합 가능성 증가.

asdf