
본 글은 Delta Lake 2.2.0 Table deletes, updates, and merges 을 번역 및 정리하였습니다.
Delta Lake는 Delta 테이블에서 데이터를 삭제하고 업데이트하는 데 도움이 되는 여러 문장을 지원합니다.
Delete from a table
Delta Lake를 사용하면 Delta 테이블에서 조건에 일치하는 데이터를 삭제할 수 있습니다. 예를 들어, people10m이라는 테이블이나 /tmp/delta/people-10m 경로에 있는 테이블에서 birthDate 열의 값이 1955년 이전인 사람에 해당하는 모든 행을 삭제하려면 다음과 같이 실행할 수 있습니다:
DELETE FROM people10m WHERE birthDate < '1955-01-01'
DELETE FROM delta.`/tmp/delta/people-10m` WHERE birthDate < '1955-01-01'from delta.tables import *
from pyspark.sql.functions import *
deltaTable = DeltaTable.forPath(spark, '/tmp/delta/people-10m')
# Declare the predicate by using a SQL-formatted string.
deltaTable.delete("birthDate < '1955-01-01'")
# Declare the predicate by using Spark SQL functions.
deltaTable.delete(col('birthDate') < '1960-01-01')자세한 내용은 Delta Lake API를 참조하십시오.
💡 중요:delete는 Delta 테이블의 최신 버전에서 데이터를 제거하지만 이전 버전이 명시적으로 vacuum되기 전까지 물리적 저장소에서 데이터를 제거하지 않습니다. 자세한 내용은 vacuum을 참조하십시오.
💡 팁:가능한 경우, 파티션화된 Delta 테이블의 파티션 열에 대한 predicate를 제공하면 작업을 크게 빠르게 할 수 있습니다.
Update a table
Delta Lake를 사용하면 Delta 테이블에서 조건에 일치하는 데이터를 업데이트할 수 있습니다. 예를 들어, people10m이라는 테이블이나 /tmp/delta/people-10m 경로에 있는 테이블에서 gender 열에서 M 또는 F에서 Male 또는 Female로 축약을 변경하려면 다음과 같이 실행할 수 있습니다:
UPDATE people10m SET gender = 'Female' WHERE gender = 'F';
UPDATE people10m SET gender = 'Male' WHERE gender = 'M';
UPDATE delta.`/tmp/delta/people-10m` SET gender = 'Female' WHERE gender = 'F';
UPDATE delta.`/tmp/delta/people-10m` SET gender = 'Male' WHERE gender = 'M';from delta.tables import *
from pyspark.sql.functions import *
deltaTable = DeltaTable.forPath(spark, '/tmp/delta/people-10m')
# Declare the predicate by using a SQL-formatted string.
deltaTable.update(
condition = "gender = 'F'",
set = { "gender": "'Female'" }
)
# Declare the predicate by using Spark SQL functions.
deltaTable.update(
condition = col('gender') == 'M',
set = { 'gender': lit('Male') }
)자세한 내용은 Delta Lake API를 참조하십시오.
💡 팁:delete와 유사하게, 파티션에 대한 predicate를 사용하면 업데이트 작업을 크게 빠르게 할 수 있습니다.
Upsert into a table using merge
Delta Lake를 사용하면 MERGE SQL 작업을 사용하여 소스 테이블, 뷰 또는 DataFrame의 데이터를 대상 Delta 테이블에 upsert할 수 있습니다. Delta Lake는 MERGE에서 삽입, 업데이트 및 삭제를 지원하며, 고급 사용 사례를 용이하게 하기 위해 SQL 표준을 넘어 확장 구문을 지원합니다.
예를 들어, people10mupdates이라는 소스 테이블이나 /tmp/delta/people-10m-updates 경로에 새 데이터가 있고, 해당 일부 레코드가 대상 데이터에 이미 존재할 수 있는 people10m이라는 대상 테이블이나 /tmp/delta/people-10m 경로가 있다고 가정해 봅시다. 새 데이터를 병합하려면, 해당 사람의 id가 이미 있는 경우 행을 업데이트하고 일치하는 id가 없는 경우 새 행을 삽입하려고 합니다. 다음과 같이 실행할 수 있습니다:
MERGE INTO people10m
USING people10mupdates
ON people10m.id = people10mupdates.id
WHEN MATCHED THEN
UPDATE SET
id = people10mupdates.id,
firstName = people10mupdates.firstName,
middleName = people10mupdates.middleName,
lastName = people10mupdates.lastName,
gender = people10mupdates.gender,
birthDate = people10mupdates.birthDate,
ssn = people10mupdates.ssn,
salary = people10mupdates.salary
WHEN NOT MATCHED
THEN INSERT (
id,
firstName,
middleName,
lastName,
gender,
birthDate,
ssn,
salary
)
VALUES (
people10mupdates.id,
people10mupdates.firstName,
people10mupdates.middleName,
people10mupdates.lastName,
people10mupdates.gender,
people10mupdates.birthDate,
people10mupdates.ssn,
people10mupdates.salary
)from delta.tables import *
deltaTablePeople = DeltaTable.forPath(spark, '/tmp/delta/people-10m')
deltaTablePeopleUpdates = DeltaTable.forPath(spark, '/tmp/delta/people-10m-updates')
dfUpdates = deltaTablePeopleUpdates.toDF()
deltaTablePeople.alias('people') \
.merge(
dfUpdates.alias('updates'),
'people.id = updates.id'
) \
.whenMatchedUpdate(set =
{
"id": "updates.id",
"firstName": "updates.firstName",
"middleName": "updates.middleName",
"lastName": "updates.lastName",
"gender": "updates.gender",
"birthDate": "updates.birthDate",
"ssn": "updates.ssn",
"salary": "updates.salary"
}
) \
.whenNotMatchedInsert(values =
{
"id": "updates.id",
"firstName": "updates.firstName",
"middleName": "updates.middleName",
"lastName": "updates.lastName",
"gender": "updates.gender",
"birthDate": "updates.birthDate",
"ssn": "updates.ssn",
"salary": "updates.salary"
}
) \
.execute()Scala, Java 및 Python 구문 세부 정보는 Delta Lake API를 참조하십시오.
Delta Lake 병합 작업은 일반적으로 소스 데이터를 두 번 통과해야 합니다. 소스 데이터에 비결정적 표현식이 포함되어 있는 경우, 소스 데이터에서 여러 번 통과하면 잘못된 결과를 초래할 수 있으므로 주의해야 합니다. 비결정적 함수의 일반적인 예로는 current_date 및 current_timestamp 함수가 있습니다. 비결정적 함수를 사용하지 않을 수 없는 경우, 예를 들어 임시 Delta 테이블로 소스 데이터를 저장하는 것을 고려해보십시오. 소스 데이터를 캐시하면 이 문제를 해결할 수 없을 수 있습니다. 캐시 무효화로 인해 클러스터에서 일부 executor가 손실되는 경우 소스 데이터가 일부 또는 완전히 재계산될 수 있기 때문입니다.
Operation semantics
다음은 병합 프로그래밍 작업에 대한 자세한 설명입니다.
- whenMatched 및 whenNotMatched 절의 수에 제한이 없습니다.
- whenMatched 절은 일치하는 조건에 따라 소스 행이 대상 테이블 행과 일치하는 경우 실행됩니다. 이러한 절은 다음과 같은 의미를 갖습니다.
- whenMatched 절에는 최대 하나의 업데이트 및 삭제 작업이 있을 수 있습니다. 병합의 업데이트 작업은 일치하는 대상 행의 지정된 열만 업데이트합니다 (update 작업과 유사합니다). 삭제 작업은 일치하는 행을 삭제합니다.
- 각 whenMatched 절에는 선택적 조건이 있을 수 있습니다. 이 절 조건이 있는 경우 절 조건이 true 인 경우에만 일치하는 소스-대상 행 쌍에 대해 업데이트 또는 삭제 작업이 실행됩니다.
- 여러 whenMatched 절이 있는 경우 지정된 순서대로 평가됩니다. 마지막 이외의 모든 whenMatched 절에는 조건이 있어야합니다.
- 병합 조건과 일치하는 소스 및 대상 행 쌍에 대해 whenMatched 조건 중 하나라도 true로 평가되지 않으면 대상 행이 변경되지 않습니다.
- 소스 데이터 집합의 해당 열을 사용하여 대상 Delta 테이블의 모든 열을 업데이트하려면 whenMatched(...).updateAll()을 사용하십시오. 이는 다음과 같습니다:
whenMatched(...).updateExpr(Map("col1" -> "source.col1", "col2" -> "source.col2", ...))대상 Delta 테이블의 모든 열에 대해 업데이트하려면이 작업을 사용하십시오. 따라서이 작업은 소스 테이블이 대상 테이블과 동일한 열을 가지고 있다고 가정합니다. 그렇지 않으면 쿼리에서 분석 오류가 발생합니다.
💡 참고:자동 스키마 마이그레이션을 활성화하면이 동작이 변경됩니다. 자세한 내용은 자동 스키마 진화(Automatic schema evolution)를 참조하십시오.
💡 중요:병합 작업은 소스 데이터 집합의 여러 행이 일치하고 병합이 대상 Delta 테이블의 동일한 행을 업데이트하려고 시도하면 실패할 수 있습니다. 병합의 SQL 세미틱에 따르면 이러한 업데이트 작업은 애매모호합니다. 일치하는 대상 행을 업데이트하는 데 사용할 소스 행이 명확하지 않기 때문입니다. 여러 일치 항목을 방지하기 위해 소스 테이블을 전처리 할 수 있습니다. 변경 데이터 캡처 예제를 참조하여 대상 Delta 테이블에 해당 변경 사항을 적용하기 전에 변경 데이터 집합 (즉, 소스 데이터 집합)을 전처리하여 각 키에 대한 최신 변경 사항만 유지하는 방법을 보여줍니다.
SQL VIEW에 대해 SQL MERGE 작업을 적용하려면 CREATE VIEW viewName AS SELECT * FROM deltaTable과 같이 뷰가 정의되었어야합니다.
Schema validation
merge는 insert 및 update 표현식에서 생성된 데이터의 스키마가 테이블의 스키마와 호환 가능한지 자동으로 확인합니다. 병합 작업이 호환 가능한지 확인하는 데 다음 규칙을 사용합니다.
업데이트 및 삽입 작업의 경우 지정된 대상 열이 대상 Delta 테이블에 있어야 합니다.
- updateAll 및 insertAll 작업의 경우 소스 데이터 집합에는 대상 Delta 테이블의 모든 열이 있어야합니다. 소스 데이터 집합에는 추가 열이 있을 수 있으며 무시됩니다.
- 추가 열이 무시되지 않고 대신 대상 테이블 스키마를 업데이트하여 새 열을 포함하려면 자동 스키마 진화를 참조하십시오.
- 모든 작업에 대해 대상 열을 생성하는 표현식의 데이터 유형이 대상 Delta 테이블의 해당 열과 다른 경우 merge는 이를 테이블의 유형으로 캐스팅하려고 시도합니다.
Automatic schema evolution
기본적으로 updateAll 및 insertAll은 대상 Delta 테이블의 모든 열에 대해 소스 데이터 집합에서 같은 이름의 열을 할당합니다. 대상 테이블의 열과 일치하지 않는 소스 데이터 집합의 열은 무시됩니다. 그러나 일부 사용 사례에서는 소스 열을 대상 Delta 테이블에 자동으로 추가하는 것이 바람직할 수 있습니다. updateAll 및 insertAll (최소 하나)로 병합 작업을 실행하기 전에 Spark 세션 구성 spark.databricks.delta.schema.autoMerge.enabled를 true로 설정하여 병합 작업 중 테이블 스키마를 자동으로 업데이트할 수 있습니다.
💡 참고: 스키마 진화는 updateAll (UPDATE SET *) 또는 insertAll (INSERT *) 작업 또는 둘 다가있을 때만 발생합니다.update 및 insert 작업은 대상 테이블에 이미 존재하지 않는 대상 열을 명시 적으로 참조 할 수 없습니다 (클로즈에서 updateAll 또는 insertAll이 하나의 절로 있는 경우도 마찬가지입니다). 아래 예제를 참조하십시오.
스키마 진화가 있는 및 없는 병합 작업의 효과에 대한 몇 가지 예제를 살펴 보겠습니다.
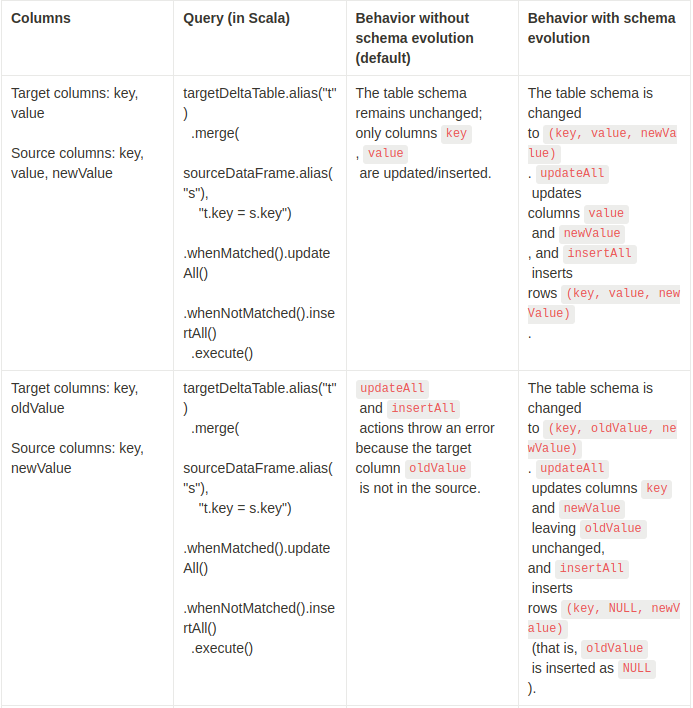

Special considerations for schemas that contain arrays of structs
Delta MERGE INTO는 이름별로 구조체 필드를 해결하고 구조체 배열에 대한 스키마 진화를 지원합니다. 스키마 진화가 활성화 된 경우 대상 테이블 스키마는 구조체 배열에 대해 진화 할 수 있으며 이는 배열 내부의 모든 중첩 구조체와도 호환됩니다.
다음은 스키마 진화가 있는 및 없는 구조체 배열의 병합 작업의 효과에 대한 몇 가지 예제입니다.
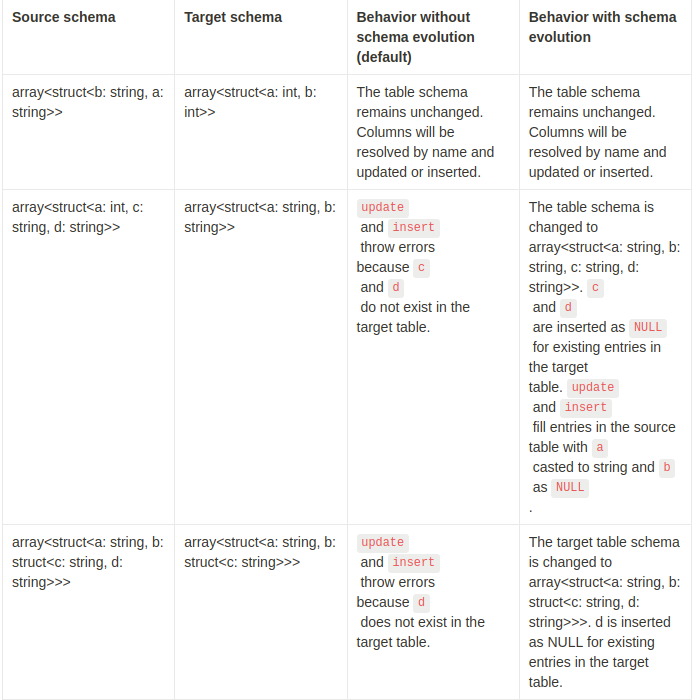
Performance tuning
다음 방법을 사용하여 병합에 소요되는 시간을 줄일 수 있습니다.
- 일치 항목의 검색 공간을 줄입니다. 기본적으로 병합 작업은 소스 테이블에서 일치 항목을 찾기 위해 전체 Delta 테이블을 검색합니다. 검색 공간을 줄이는 한 가지 방법은 매치 조건에 알려진 제약 조건을 추가하는 것입니다. 예를 들어 국가와 날짜로 파티셔닝된 테이블이 있고 마지막 날짜와 특정 국가의 정보를 업데이트하기 위해 병합을 사용하려는 경우 조건을 추가할 수 있습니다.
events.date = current_date() AND events.country = 'USA'올바른 파티션에서만 일치 항목을 찾기 때문에 해당 쿼리의 속도가 향상되어 더 빠르게 처리됩니다. 이러한 방식은 다른 동시 작업과의 충돌 가능성도 줄여줍니다. 자세한 내용은 Concurrency control를 참조하십시오.
- Compact files:(파일을 압축합니다): 데이터가 많은 작은 파일에 저장되어있는 경우 일치 항목을 찾기 위해 데이터를 읽는 것이 느려질 수 있습니다. 작은 파일을 큰 파일로 압축하여 읽기 처리량을 향상시킬 수 있습니다. 자세한 내용은 Compact files를 참조하십시오.
- Control the shuffle partitions for writes(쓰기에 대한 셔플 파티션을 제어합니다): 병합 작업은 업데이트 된 데이터를 계산하고 쓰기 위해 데이터를 여러 번 셔플합니다. 셔플에 사용되는 작업 수는 Spark 세션 구성 spark.sql.shuffle.partitions로 제어됩니다. 이 매개 변수를 설정하면 병렬성 뿐만 아니라 출력 파일 수도 결정됩니다. 값을 높이면 병렬성이 높아지지만 작은 데이터 파일이 더 많이 생성됩니다.
- Repartition output data before write(쓰기 전 출력 데이터를 재파티션합니다): 파티션 된 테이블의 경우, 병합 작업은 셔플 파티션 수보다 훨씬 더 많은 작은 파일을 생성할 수 있습니다. 이는 모든 셔플 작업이 여러 파티션에 여러 파일을 작성할 수 있기 때문입니다. 이는 성능 병목 현상이 될 수 있습니다. 많은 경우, 쓰기 전 테이블의 파티션 열에 따라 출력 데이터를 다시 파티션하는 것이 도움이 됩니다. 이것은 Delta Lake 1.1 이상에서 기본적으로 활성화됩니다. Delta Lake 1.0 이하에서 이를 활성화하려면 Spark 세션 구성 spark.databricks.delta.merge.repartitionBeforeWrite.enabled를 true로 설정하십시오.
Merge examples
여기 몇 가지 다른 시나리오에서 merge를 사용하는 방법에 대한 예시가 있습니다.
Data deduplication when writing into Delta tables
로그를 수집하여 테이블에 추가하는 것은 일반적인 ETL 사용 사례입니다. 그러나 종종 소스에서 중복 로그 레코드가 생성될 수 있으며 하향식 중복 제거 단계가 필요합니다. merge를 사용하면 중복 레코드를 삽입하는 것을 피할 수 있습니다.
MERGE INTO logs
USING newDedupedLogs
ON logs.uniqueId = newDedupedLogs.uniqueId
WHEN NOT MATCHED
THEN INSERT *deltaTable.alias("logs").merge(
newDedupedLogs.alias("newDedupedLogs"),
"logs.uniqueId = newDedupedLogs.uniqueId") \
.whenNotMatchedInsertAll() \
.execute()새 로그를 포함하는 데이터 집합은 자체 내에서 중복 제거되어야 합니다. merge의 SQL 세맨틱에 따라 테이블의 기존 데이터와 새 데이터를 일치시키고 중복을 제거하지만, 새 데이터 집합 내에 중복 데이터가 있는 경우 삽입됩니다. 따라서 테이블에 병합하기 전에 새 데이터의 중복을 제거해야 합니다.
몇 일 동안만 중복 레코드가 발생할 수 있다는 것을 알고 있다면, 테이블을 날짜별로 파티셔닝하고, 대상 테이블의 날짜 범위를 지정하여 일치시키는 것으로 쿼리를 더 최적화할 수 있습니다.
MERGE INTO logs
USING newDedupedLogs
ON logs.uniqueId = newDedupedLogs.uniqueId AND logs.date > current_date() - INTERVAL 7 DAYS
WHEN NOT MATCHED AND newDedupedLogs.date > current_date() - INTERVAL 7 DAYS
THEN INSERT *deltaTable.alias("logs").merge(
newDedupedLogs.alias("newDedupedLogs"),
"logs.uniqueId = newDedupedLogs.uniqueId AND logs.date > current_date() - INTERVAL 7 DAYS") \
.whenNotMatchedInsertAll("newDedupedLogs.date > current_date() - INTERVAL 7 DAYS") \
.execute()전에 언급한 명령보다 효율적입니다. 왜냐하면 전체 테이블이 아니라 마지막 7일 동안의 로그에서만 중복을 찾기 때문입니다. 또한 이 insert-only merge를 Structured Streaming과 함께 사용하여 로그의 연속적인 중복 제거를 수행할 수 있습니다.
- 스트리밍 쿼리에서는 foreachBatch에서 merge 작업을 사용하여 중복 제거로 스트리밍 데이터를 계속 Delta 테이블에 쓸 수 있습니다. foreachBatch에 대한 자세한 내용은 다음 스트리밍 예제를 참조하십시오.
- 또 다른 스트리밍 쿼리에서는 이 Delta 테이블에서 연속적으로 중복 제거 된 데이터를 계속 읽을 수 있습니다. 이는 insert-only merge가 새 데이터를 Delta 테이블에만 추가하기 때문에 가능합니다.
Slowly changing data (SCD) Type 2 operation into Delta tables
다른 일반적인 작업은 SCD Type 2로, 각 키에 대한 모든 변경 사항의 이력을 유지하는 차원 테이블 작업입니다. 이러한 작업은 기존 행을 업데이트하여 키의 이전 값을 이전 값으로 표시하고 새로운 행을 최신 값으로 추가해야 합니다. 업데이트가 필요한 소스 테이블과 차원 데이터가 있는 대상 테이블이 주어졌을 때, merge를 사용하여 SCD Type 2를 표현할 수 있습니다.
다음은 각 주소의 활성 날짜 범위와 함께 고객의 주소 이력을 유지하는 구체적인 예입니다. 고객의 주소를 업데이트해야 하는 경우, 이전 주소를 현재 주소가 아니라고 표시하고 활성 날짜 범위를 업데이트하고 새로운 주소를 현재 주소로 추가해야 합니다.
customersTable = ... # DeltaTable with schema (customerId, address, current, effectiveDate, endDate)
updatesDF = ... # DataFrame with schema (customerId, address, effectiveDate)
# Rows to INSERT new addresses of existing customers
newAddressesToInsert = updatesDF \
.alias("updates") \
.join(customersTable.toDF().alias("customers"), "customerid") \
.where("customers.current = true AND updates.address <> customers.address")
# Stage the update by unioning two sets of rows
# 1. Rows that will be inserted in the whenNotMatched clause
# 2. Rows that will either update the current addresses of existing customers or insert the new addresses of new customers
stagedUpdates = (
newAddressesToInsert
.selectExpr("NULL as mergeKey", "updates.*") # Rows for 1
.union(updatesDF.selectExpr("updates.customerId as mergeKey", "*")) # Rows for 2.
)
# Apply SCD Type 2 operation using merge
customersTable.alias("customers").merge(
stagedUpdates.alias("staged_updates"),
"customers.customerId = mergeKey") \
.whenMatchedUpdate(
condition = "customers.current = true AND customers.address <> staged_updates.address",
set = { # Set current to false and endDate to source's effective date.
"current": "false",
"endDate": "staged_updates.effectiveDate"
}
).whenNotMatchedInsert(
values = {
"customerid": "staged_updates.customerId",
"address": "staged_updates.address",
"current": "true",
"effectiveDate": "staged_updates.effectiveDate", # Set current to true along with the new address and its effective date.
"endDate": "null"
}
).execute()Write change data into a Delta table
CDC를 위한 또 다른 일반적인 사용 사례인 SCD와 유사하게, 외부 데이터베이스에서 생성된 모든 데이터 변경 사항을 Delta 테이블에 적용하는 것이 필요할 수 있습니다. 즉, 외부 테이블에 적용된 업데이트, 삭제 및 삽입의 집합을 Delta 테이블에 적용해야 합니다. 다음과 같이 merge를 사용하여 이 작업을 수행할 수 있습니다.
deltaTable = ... # DeltaTable with schema (key, value)
# DataFrame with changes having following columns
# - key: key of the change
# - time: time of change for ordering between changes (can replaced by other ordering id)
# - newValue: updated or inserted value if key was not deleted
# - deleted: true if the key was deleted, false if the key was inserted or updated
changesDF = spark.table("changes")
# Find the latest change for each key based on the timestamp
# Note: For nested structs, max on struct is computed as
# max on first struct field, if equal fall back to second fields, and so on.
latestChangeForEachKey = changesDF \
.selectExpr("key", "struct(time, newValue, deleted) as otherCols") \
.groupBy("key") \
.agg(max("otherCols").alias("latest")) \
.select("key", "latest.*") \
deltaTable.alias("t").merge(
latestChangeForEachKey.alias("s"),
"s.key = t.key") \
.whenMatchedDelete(condition = "s.deleted = true") \
.whenMatchedUpdate(set = {
"key": "s.key",
"value": "s.newValue"
}) \
.whenNotMatchedInsert(
condition = "s.deleted = false",
values = {
"key": "s.key",
"value": "s.newValue"
}
).execute()Upsert from streaming queries using foreachBatch
스트리밍 쿼리에서 Delta 테이블에 복잡한 upserts를 쓰기 위해서는 merge와 foreachBatch의 조합을 사용할 수 있습니다. 예를 들어 다음과 같습니다.
- 업데이트 모드에서 스트리밍 집계를 작성합니다. 이것은 완전 모드보다 훨씬 효율적입니다.
from delta.tables import *
deltaTable = DeltaTable.forPath(spark, "/data/aggregates")
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
deltaTable.alias("t").merge(
microBatchOutputDF.alias("s"),
"s.key = t.key") \
.whenMatchedUpdateAll() \
.whenNotMatchedInsertAll() \
.execute()
}
# Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream \
.format("delta") \
.foreachBatch(upsertToDelta) \
.outputMode("update") \
.start()- Write a stream of database changes into a Delta table(데이터베이스 변경 사항의 스트림을 Delta 테이블에 쓰기): 변경 데이터를 쓰기 위한 merge 쿼리는 foreachBatch에서 사용할 수 있으며, 변경 사항 스트림을 Delta 테이블에 지속적으로 적용할 수 있습니다.
- Write a stream data into Delta table with deduplication(중복 제거가 있는 Delta 테이블에 데이터 스트림 쓰기): 중복을 포함하는 데이터(중복 데이터)를 자동 중복 제거가 있는 Delta 테이블에 지속적으로 쓰기 위해 insert-only merge 쿼리를 foreachBatch에서 사용할 수 있습니다.
- foreachBatch 내부의 merge 문이 idempotent 하도록 확인하십시오. 스트리밍 쿼리의 재시작으로 인해 동일한 데이터 일괄 처리에 여러 번 적용될 수 있습니다.
- foreachBatch에서 merge를 사용할 때, 스트리밍 쿼리의 입력 데이터 속도 (StreamingQueryProgress를 통해 보고되며 노트북 속도 그래프에서 볼 수 있음)는 소스에서 생성되는 실제 데이터 속도의 배수로 보고될 수 있습니다. merge가 입력 데이터를 여러 번 읽어들여 입력 지표가 곱해지기 때문입니다. 이것이 병목구간이면 merge 이전에 batch DataFrame을 캐시하고, merge 이후에 uncache 할 수 있습니다.
