
들어가기
주말 만큼은 절대 포기할 수 없는 에이블러 "에이 블루 저스트"는 핫플레이스와 맛집을 찾아가기 위해 오늘도 N✌️버, 인⭐gram 에 키워드 검색을 시작합니다😊
어라? 근데 이런 검색 시스템은 어떻게 자연어를 처리하는거야?
궁금한 건 그냥 지나칠 수 없는 "에이 블루 저스트"는, 검색 시스템의 원리를 알아보기 위해 에이블 스쿨을 방문하기로 결심합니다.
TF-IDF
tf-idf

키워드를 입력했을 때, 관련 문서들이 검색 결과로 나타나는데 이 순위는 과연 어떻게 결정되는 것인지 궁금했던 적이 있었습니다.
입력한 키워드와 문서 내 단어들의 중요도를 고려하여 결과가 나온다니 무척 놀라울 따름입니다.
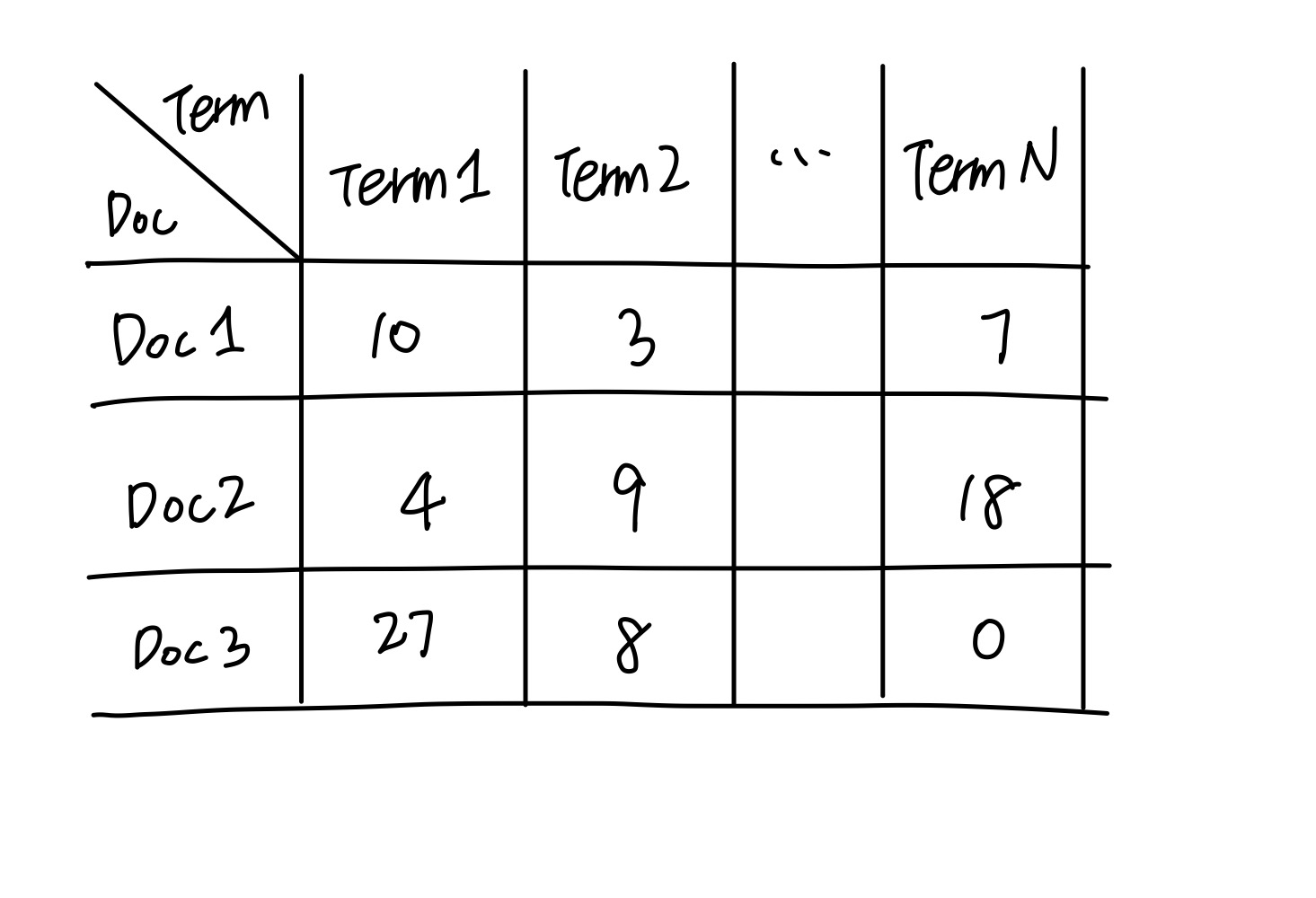
TF-IDF 계산을 위해서는 문서 내의 Term Matrix를 만들게 됩니다.
각 문서마다, Term의 출현빈도(Term Frequency)와 역 문서 빈도(Inverse Document Frequency, IDF)를 곱하여 단어마다 TF-IDF 가중치를 부여할수 있습니다. 이를 수식으로 표현하면 아래와 같이 표현할 수 있습니다.
여기서, IDF가 와닿지 않는다구요?
우리가 sns에 맛집 검색을 할 때, 정말 맛집으로 소문난 핫플레이스 식당만 결과로 나오기 원하는데, 모든 식당이 "맛집"이라고 소개해주면 과연 효과적인 검색 결과라고 할 수 있을까요?
해당 키워드로 반환되는 문서 수가 많을 수록, 해당 키워드는 중요도가 떨어지는 키워드라고 할 수 있습니다.
단어 표현 - Word Representation
사람은 자연어를 입력하게 되지만, 컴퓨터는 자연어를 이해하기 위해 어떤 과정을 거치나요?
자연어 처리 모델에 적용하기 위해서는 자연어 텍스트를 수치화하여 표현해야 합니다.
머신러닝, 딥러닝에서 자연어로 표현된 Categorical Data를 수치화 하는 방법으로 One-hot encoding 방식을 배운적이 있습니다.
아하~One-hot Encoding을 적용하면 되겠군요? Umm~ 안! 됩니다.
One-hot Encoding은 모든 단어의 개수를 알아야 단어의 차원을 결정할 수 있습니다. 운 좋게 모든 단어의 개수를 알았다고 생각했는데... 새로운 단어가 추가되었습니다🙄
모든 단어 벡터의 차원을 증가시켜야 하는 문제점이 발생합니다. 또, 특정 단어에만 1로 mapping되는 one-hot encoding 특성상 단어의 의미나 특성을 자세히 표현할 수가 없습니다.
이처럼 One-hot Encoding은 단어의 수가 매우 많은 경우, 벡터 수정이 어렵고 고차원 저밀도 벡터로 표현하게 된다는 문제점을 가지게 됩니다.
이를 해결하기 위해, 저차원에서 고밀도로 표현할 수 있는 word-embedding 방식을 앞으로 배워나가게 됩니다.
딥러닝 기반의 유사도 판단 - Jaccard, Cosine, Euclidean, Manhattan
단어 표현을 벡터화한 후, 문장 간의 유사도를 벡터 유사도를 측정하여 확인할 수 있습니다. 대표적인 유사도 측정 방식에는 Jaccard 유사도, 코사인 유사도, 유클리디언 유사도, 맨해튼 유사도 등이 있습니다.
먼저, 자카드 유사도 입니다.
자카드 유사도는 두 문장을 각각 단어의 집합으로 만들어서 전체 라벨(합집합) 중에서, 각 벡터에 요소가 같은지와 그리고 어떤 라벨인지 식별한 후 계산을 하게 됩니다.
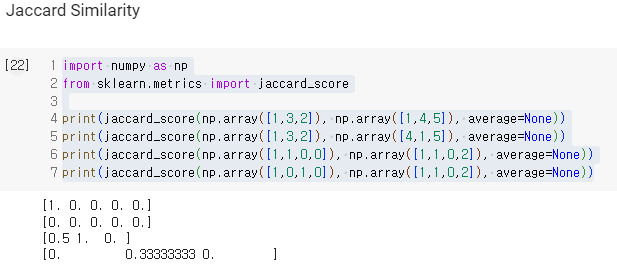
두 번째, 코사인 유사도는입니다.
코사인 유사도는 두 개의 벡터값에서 코사인 각도를 계산합니다. 삼각함수에서 코사인 함수의 결과값의 범위는 [-1, 1] 이기 때문에, 코사인 유사도 값도 [-1, 1] 값을 가지게 됩니다.

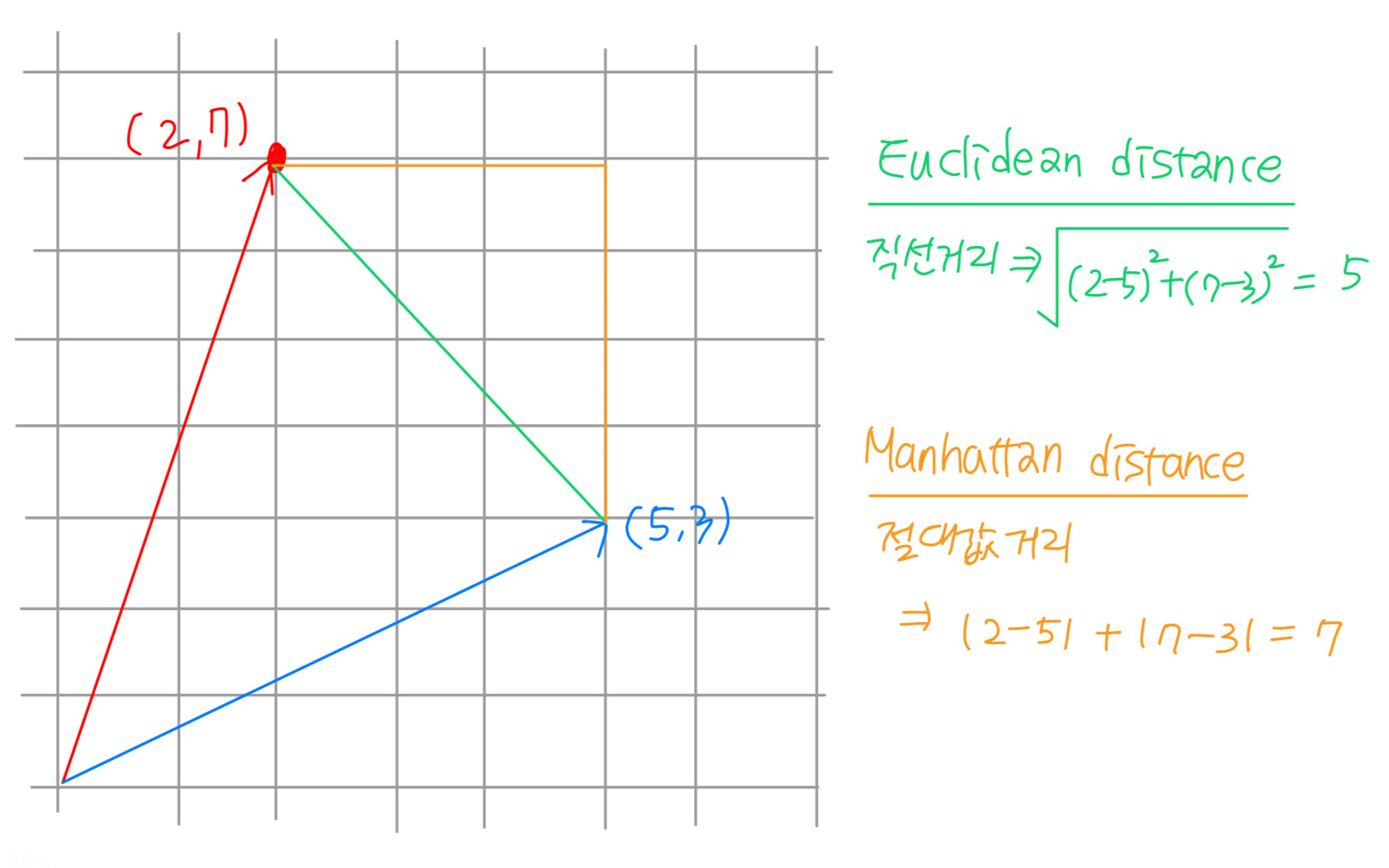
마지막으로, 유클리드 유사도와 맨해튼 유사도가 있습니다.
두 유사도 방식은 두 벡터 간의 거리로 유사도를 판단하게 됩니다.
그러나, 유클리디언 유사도는 두 벡터간의 직선 거리 차이를 구하는 방식이라면, 맨해튼 유사도는 두 벡터 요소별 절댓값 거리의 합을 의미하기 때문에 결과값에 차이가 있음에 유의하셔야 합니다.
비지도학습
분류 vs. 군집화
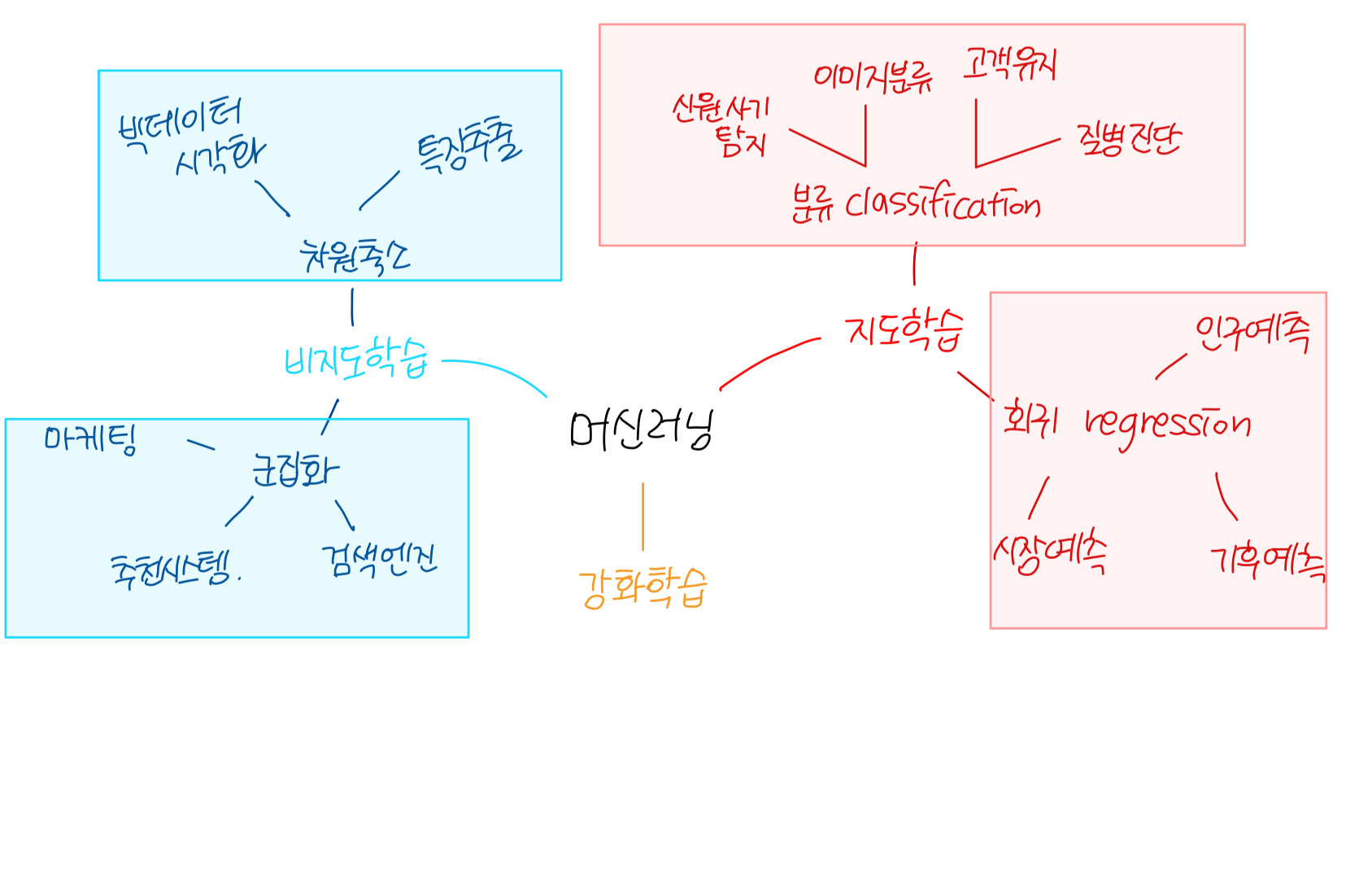
분류는 지도학습의 한 종류로, 사전 분류된 instances를 기반으로, 새로운 instance의 label을 예측하는 학습 방식을 의미합니다.
군집화는 라벨링 되지 않는 데이터 셋에서 자연스러운 군집을 찾는 비지도 학습 방식입니다.
라벨의 유무에 따라서 지도vs비지도 학습의 차이를 명확히 이해할 수 있습니다.
K-means 알고리즘
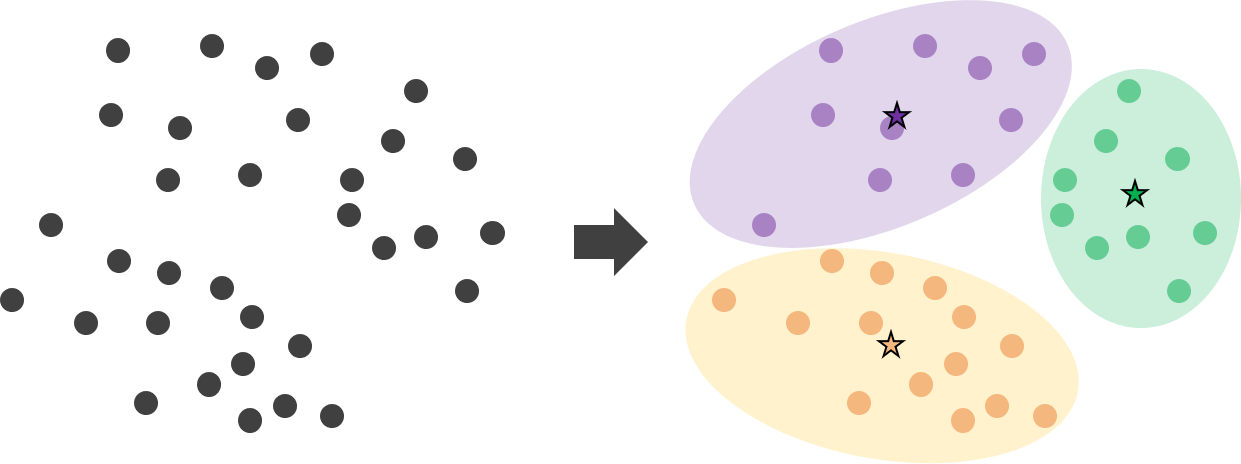
K-means 알고리즘의 작동 원리는 다음과 같습니다.
1. 데이터 중 랜덤하게 k(군집의 개수)개의 샘플을 추출하여, 각 군집의 centeroid 초기 평균값으로 지정합니다.
2. 각 데이터와 각 평균의 사이 거리를 계산하여, 가장 가까운 클러스터 군집에 할당시킵니다.
3. 모든 데이터의 할당이 완료되었다면, 각 군집별 평균(centeroid)를 다시 계산합니다.
4. 군집의 변화가 없을 때 까지 2-3번의 과정을 반복 시행합니다.
해당 알고리즘을 활용하면, 적절히 군집을 나눌 수 있을 것 같습니다. k-means는 완벽한 군집 알고리즘일까요?
그렇지 않습니다! 1번째 과정에서 각 군집의 평균값을 임의로 설정하였던 것 기억하시나요?
K-means 알고리즘은 처음에 지정하는 중심점의 위치를 무작위로 결정하기 때무에, 최적의 클러스터롤 묶어주는 데에 한계가 존재할 수 있습니다.
K-Nearest Neighbor algorithms
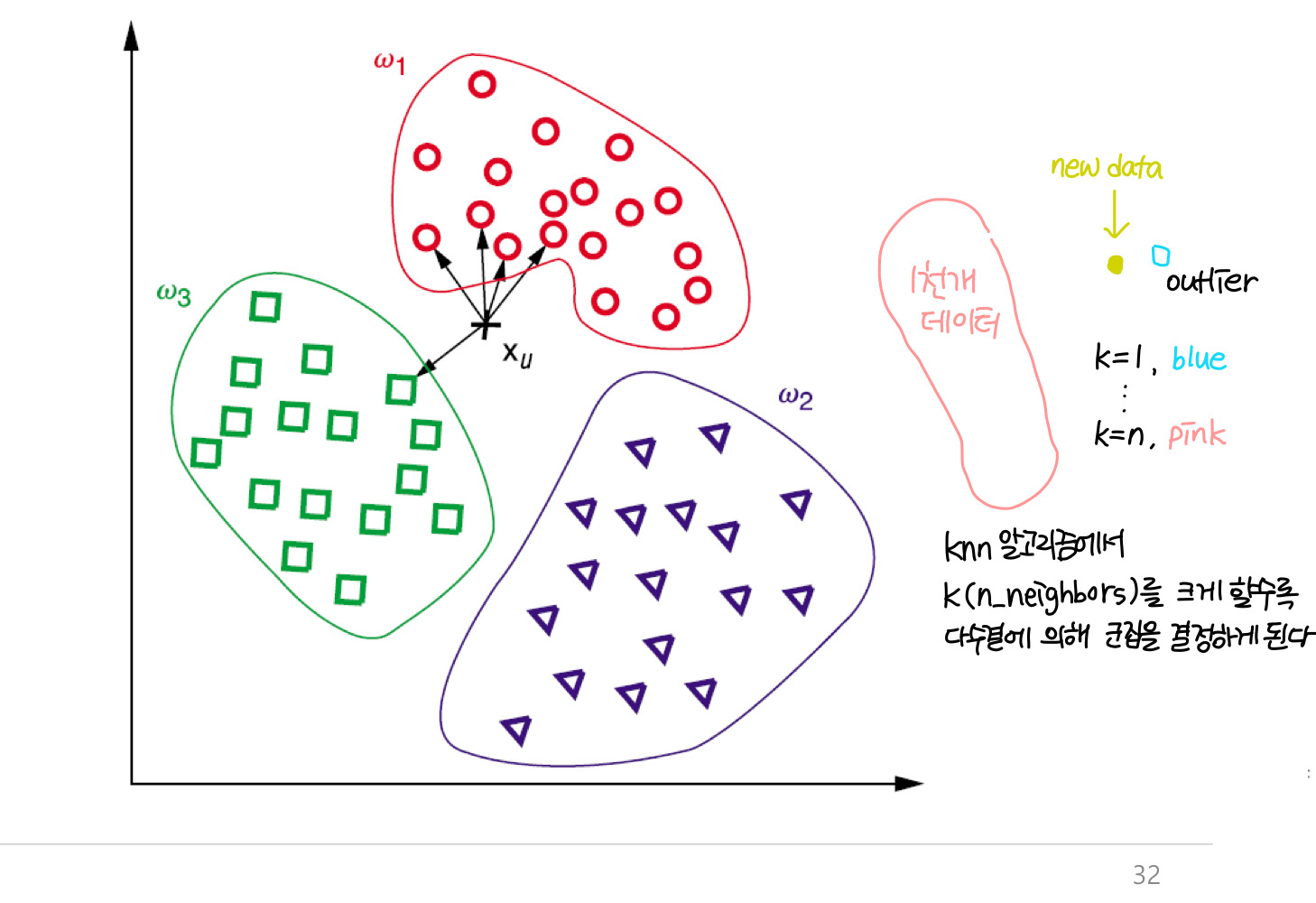
알고리즘 이름에서 알 수 있듯, 가장 가까운 이웃을 찾는 알고리즘입니다.
여기서 K는 개수, 제일 가까운 이웃을 몇 개나 뽑아낼 것인지를 나타내는 변수이며, 거리가 가장 가까운 k개의 데이터들을 뽑아 어떤 분류에 해당하는지 알아낼 수 있습니다. 최근접 k개의 데이터 중 어떤 class의 데이터가 가장 많은가에 따라 새로운 데이터의 군집, label이 결정되는 분류 및 군집 알고리즘입니다.
RSS 정보검색 시스템 구현하기
먼저, 학습에 필요한 라이브러리 및 패키지를 설치해야 합니다
import feedparser
from newspaper import Article
from konlpy.tag import Okt
from collections import Counter
from operator import eq method
from bs4 import BeautifulSoup urls = ["http://rss.etnews.com/Section901.xml",
"http://rss.etnews.com/Section902.xml",
"http://rss.etnews.com/Section903.xml",
"http://rss.etnews.com/Section904.xml"]모든 RSS파일에서 기사의 제목과 link를 추출하는 작업을 수행해 보려고 합니다.
제목과 link를 크롤링 함수를 작성해 보겠습니다.
def crawl_rss(urls):
array_rss = []
titles_rss = set()
for url in urls:
print("[Crawl RSS]", url)
parser_rss = feedparser.parse(url)
for p in parser_rss.entries:
array_rss.append({'title': p.title, 'link' : p.link})
return array_rss
list_articles = crawl_rss(urls)
print(list_articles)RSS 파일을 하나씩 탐색하여, url를 파싱한 결과를 parse_rss에 저장하도록 하였습니다. parse_rss에 있는 모든 entries/기사 선택해서 array_rss에 저장합니다:)
RSS파일에는 기사제목, 링크, 그리고 150자 분량의 기사내용만 있기 때문에, 상세한 기사내용을 자세히 볼 수가 없었어요ㅠㅠ
그래서 앞서 전처리한 link를 이용하여, 상세 기사내용을 뽑아보도록 하겠습니다.
def crawl_article(url, language='ko'):
print("[Crawl Article]", url)
a = Article(url, language=language)
a.download()
a.parse()
return a.title, a.text
for article in list_articles:
_, text = crawl_article(article['link'])
article['text'] = text
print(list_articles[0]) link를 타고 들어가, 그 안에 있는 title과 text를 추출하는 작업입니다.
특정 url에 있는 기사를 다운받아, parsing 작업을 수행합니다. list_articles 리스트에는 title과 link에 대한 정보 밖에 없었습니다. 그래서 마지막에 article['text'] = text 를 추가하여, 제목, 링크, 본문내용을 한 눈에 저장할 수 있도록 하였습니다.
