
들어가기
주말 만큼은 절대 포기할 수 없는 에이블러 "에이 블루 저스트"는 검색 시스템의 검색 결과로 나온 맛집을 탐방하고 왔습니다.😊
꺼억~ 맛있게 먹었으니 이제 리뷰를 써볼까나?
그런데? 리뷰에 긍정적인 내용도 있고, 부정적인 내용도 있잖아? 내용만 보고 긍정인지 부정인지 어떻게 분류할 수 있을까?
궁금한 건 그냥 지나칠 수 없는 "에이 블루 저스트"는 이번 시간에 기본적인 자연어 전처리 기술과 감정분류에 대해 배우러 에이블스쿨을 방문해봅니다.
NLP
자연어 처리는 언어학, 컴퓨터 과학, 인공지능의 하위 분야입니다.
컴퓨터와 인간의 언어 사이의 상호작용에 관여하고, 특히 많은 양의 자연어 데이터를 처리하고 분석하기 위해 컴퓨터를 프로그래밍하는 방법을 NLP 이라고 합니다.
이 기술을 통해 문서에 포함된 정보와 통찰력을 정확하게 추출 할 수 있을 뿐만 아니라 문서, 문장 자체를 분류하고 구성할 수 있습니다.
텍스트 데이터의 특성
텍스트 데이터는 시계열 데이터의 기본 성질을 같습니다. 텍스트 정보가 시간 정보를 갖는다는 의미가 쉽게 와닿지 않을 수도 있는데요? 이는 단어가 나타나고 있는 위치가 중요함을 의미하며, 텍스트 데이터는 샘플마다 길이가 다르다는 시계열적 특성을 가지고 있습니다.
텍스트 데이터는 형태소 분석이 필요하고, 구문론과 의미론과 같은 언어학적 이론개념을 바탕으로 접근이 필요합니다. 언어마다 가지고 있는 다른 특성을 이해하고, 딥러닝 모델을 활용하여 예측, 분류하기 위해서는 기호를 수치로 변환하는 작업도 필요합니다.
Linear Regression
감정을 긍부정으로 분류하기 위해서는 분류 기준을 확립하는 일, 그리고 데이터와 레이블(클래스) 별 경향성을 이해할 필요가 있습니다.
그래서 먼저 기본적인 선형 회귀를 이해해보도록 하겠습니다.
선형 회귀는 말 그대로, 선형적인 경향성을 알아보기 위해 사용할 수 있는 가장 기본적인 회귀모델입니다.
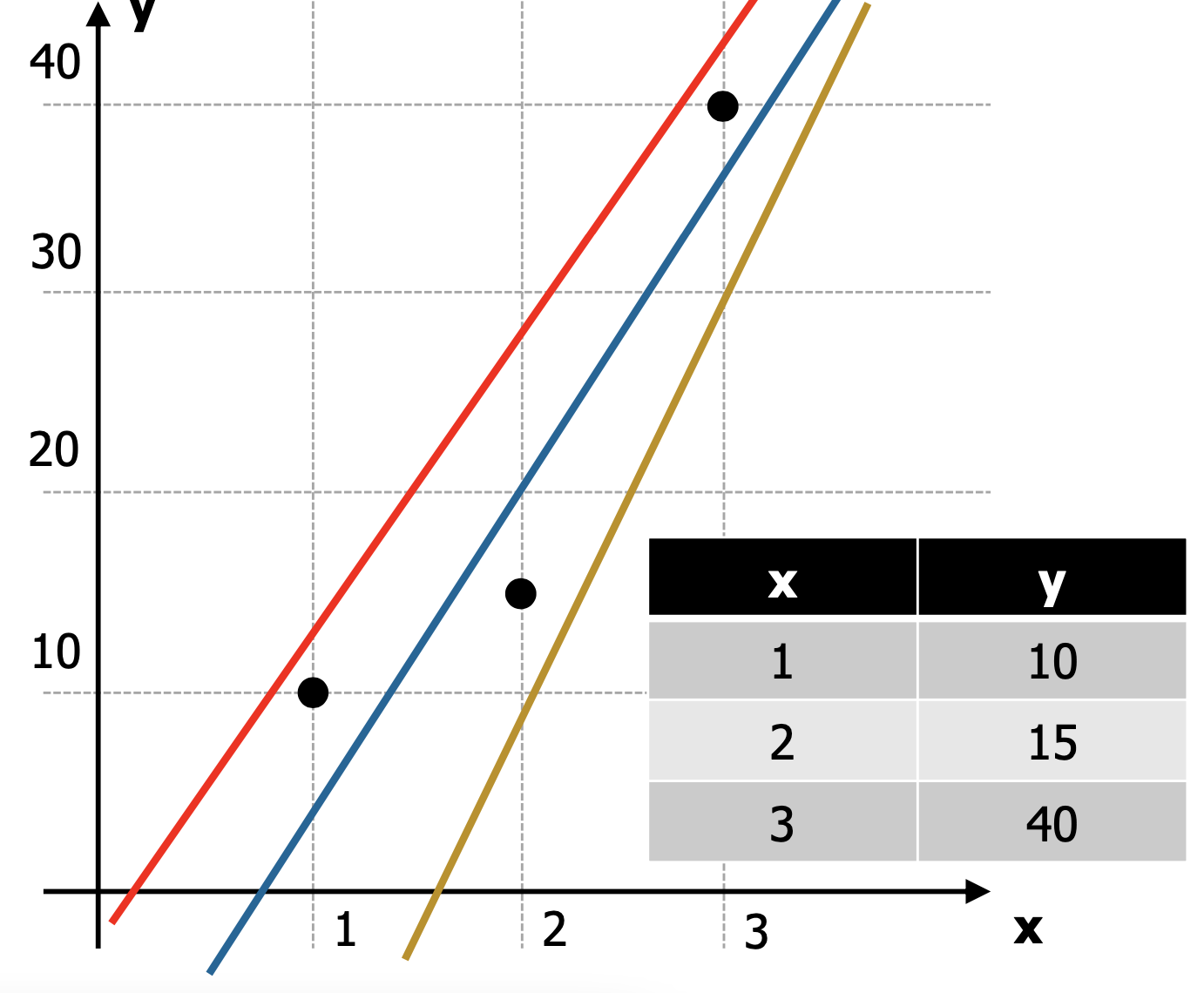
실제 세계에서 발생하는 모든 데이터를 통과하는 하나의 직선을 표현해보세요~ 라고 문제가 주어진다면 여러분은 표현하실 수 있으실까요? 아마 이는 불가능에 가까울 것입니다. 이렇게 때문에, 비교적 오차정도를 적게 하는 직선을 회귀선으로 표현하기에 이르렀고, 이 과정에서 등장하게 된 것이 Cost Function (손실함수) 입니다.
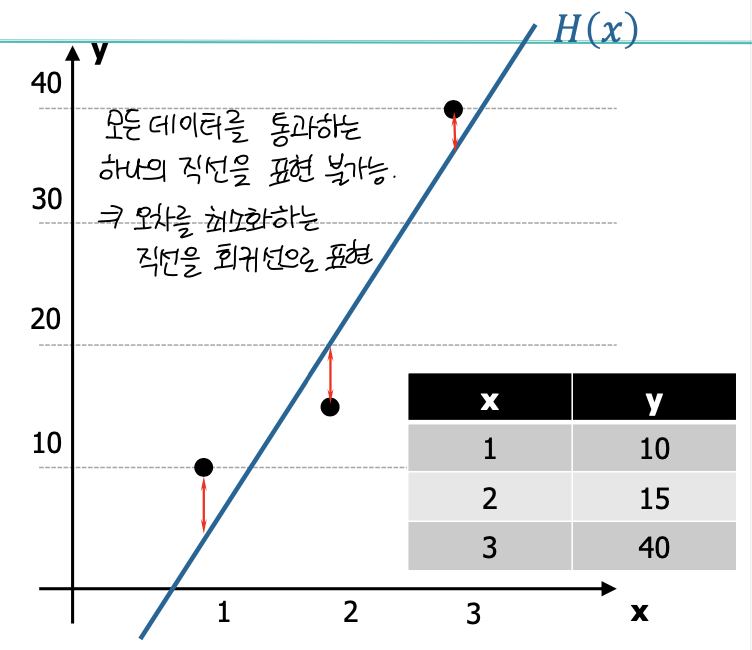
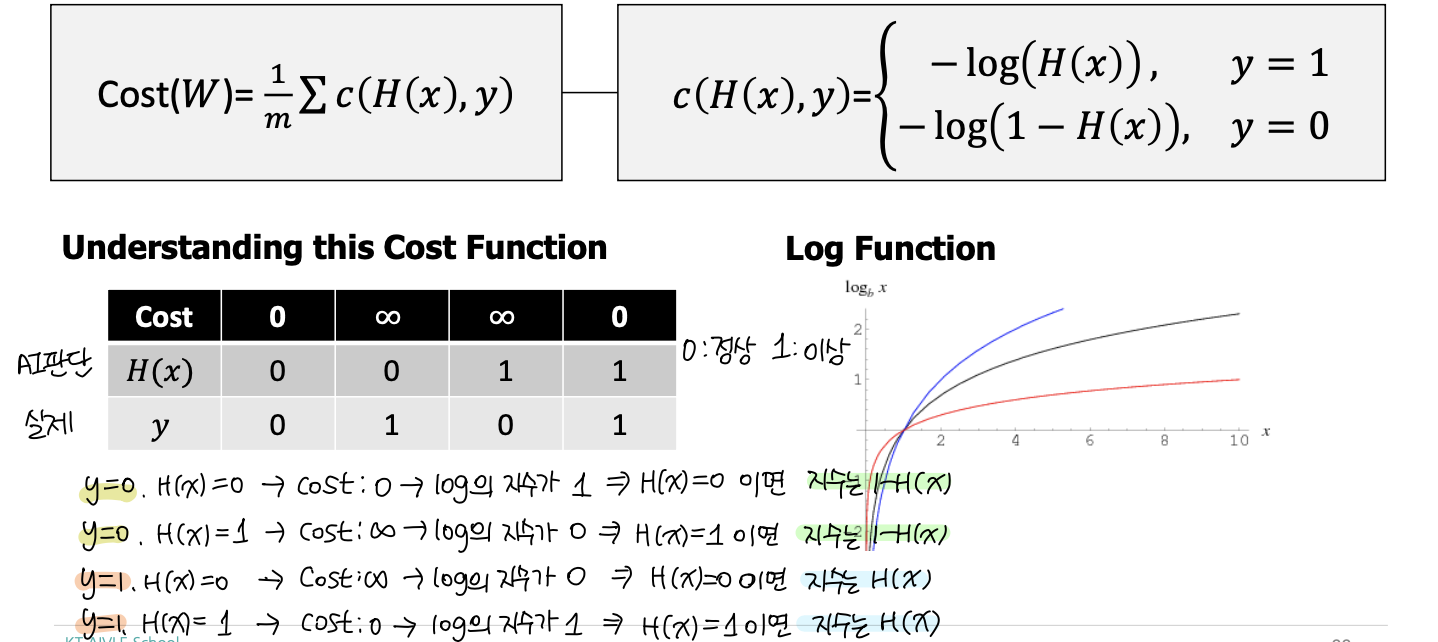
오차(Error) 라고 하는 것은 예측값과 실제값의 대소비교에 따라, 음수가 될수도 양수가 될수도 있습니다. 양수 오차와 음수 오차 값이 누적되어 0의 가까운 값에 수렴했다고 한다면, 과연 이 모델은 오차가 적은 좋은 모델일까요?
이러한 의문점을 해결하기 위해, 자승법을 활용한 MSE(Mean Squared Error)가 등장하게 됩니다.
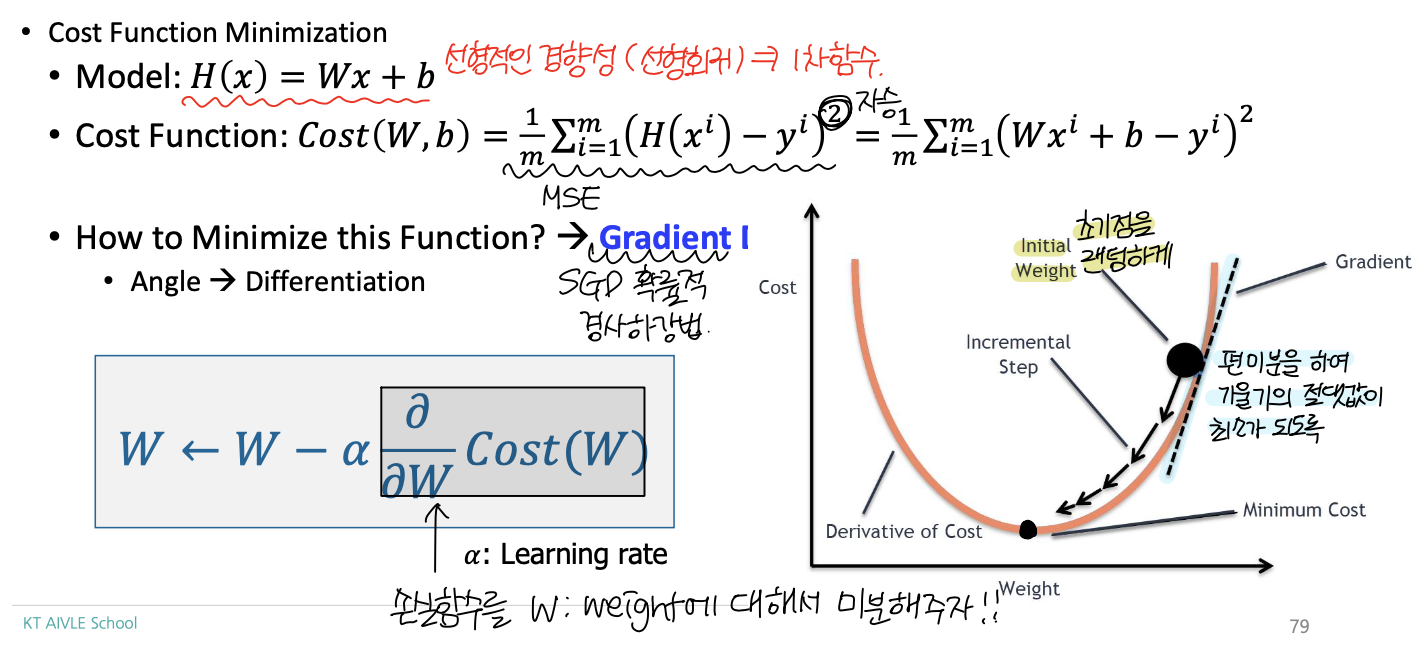
선형 회귀 함수는 1차함수이기 때문에, 이를 제곱하게 되면 convex한 2차 함수가 됩니다. 2차 함수에서의 최소값은 미분을 활용하여 기울기 값으로 최소지점을 찾을 수 있습니다.
Binary Classification
단순한듯 보이는 이진분류는 딥러닝 문제 해결에 다수 사용되고 있습니다.
실생활에서 메일의 스팸여부를 탐지하거나, 신용카드 사기 거래 탐지, 그리고 방사선 이미지에서 종양의 인식하여 양성인지 음성인지 분류하는 질병여부 예측에도 활용되고 있습니다.
앞서, Linear Regression을 통해 선형적인 경향성을 알아보는 시도를 해보았습니다. 이제 이 결과를 활성화함수를 이용하여 0인지 1인지, 또는 음성인지 양성인지, 긍정인지 부정인지 분류하는 원리를 이해해보겠습니다.
선형 회귀모델은 1차식 형태이기 때문에 제곱할 경우 2차 함수 형태가 되어, 미분해서 최소점 찾기가 가능합니다. 그러나, 이진 분류에서 사용되는 활성함수인 시그모이드 계열의 함수는 그렇지 않습니다.

시그모이들 계열 함수에서 최소점을 찾을 수 있는 새로운 Cost Function이 필요합니다.

Word Embedding
문장을 보고 이진분류를 하기 위해서는, 문장에 나타나고 있는 단어의 의미를 수치화하는 작업을 수행해야 합니다. 이미 이와 관련하여 One-hot Encoding을 배운 적이 있습니다. 이에 대한 내용을 정리하고 넘어가도록 하겠습니다.
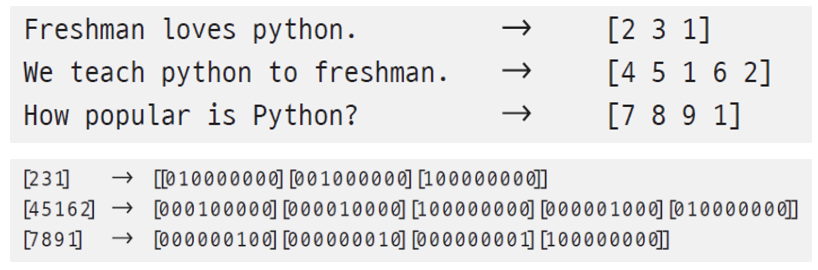
워드 임베딩 방식은 사전 크기가 크면, 희소 벡터가 되어 메모리 낭비가 심하게 됩니다. 그리고 단어 사이의 연관 관계를 반영하지 못하기 때문에, 단어의 의미를 저차원 공간 벡터로 표현하고 신경망 학습을 통해 의미를 알아내는 방식을 사용합니다.
