기계 학습은 크게 3가지 학습 방식으로 나누어 볼 수 있다.
지도 학습은 주어진 답을 정확하게 맞추기 위해 진행되는 학습 방식을 의미한다.
비지도 학습은 정리를 통해서 어떤 데이터를 이해하게 되는 학습 방식이다.
강화학습은 숙련하는 것과 유사하다.
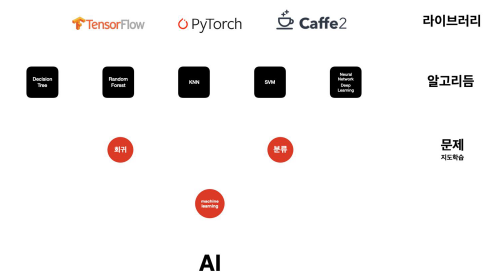
기계 학습 중 지도 학습은 회귀와 분류로 나누어 볼 수 있다.
회귀는 label이 숫자형(연속형) 변수인 경우, 정확한 값을 예측하기 위한 학습방법이고,
분류는 label이 범주형 변수인 경우, 데이터가 속하는 범주를 정확하게 맞추기 위한 학습방법이다.
DecisionTree, RandomForest, KNN, SVM, Neural Network 등과 같은 알고리즘을 이용해 회귀와 분류 예측을 진행할 수 있다.
AI를 구현하기 위한 세부 라이브러리는 TensorFlow, PyTorch 등이 있다.
TensorFlow와 PyTorch의 차이점이라고 한다면, 파이토치는 연구 종사자분들이 주로 사용하는 라이브러리라고 한다. 실무 현업에서는 텐서플로우를 사용하는 경우가 많지만, 현재에는 이 둘 간의 우열을 가릴 수는 없기 때문에, 결국에는 두 가지를 모두 사용할 줄 알아야한다는 점이다.
데이터 엔지니어, 데이터 분석가 그리고 AI개발자의 차이점은 무엇일까?
만약 사용자가 하나의 웹 사이트를 이용한다면, 데이터 엔지니어는 사용자의 로그 데이터를 모아서 리포트를 만들어 서비스가 어떻게 활용되었는지, 데이터가 흘러가는 길을 만드는 일을 한다. 데이터 분석가는 데이터 파이프라인을 통해 처리되는 데이터들을 활용하여 분석 리포트를 기획 및 작성하는 업무를 담당할 수 있다.
AI 개발자는 머신러닝 엔지니어, 데이터 엔지니어 라고 많이 불리며 데이터 분석과 개발을 총괄하는 직무가 데이터 사이언티스트라고 할 수 있다. 데이터 사이언티스트는 미션을 해결하기 위해 없는 데이터를 수집하고, 처리, 프로세스 전반에 대한 이해가 필요한 직무이다.
빅 데이터 관련 엔진, 아키텍쳐를 학습하기 위해서는 관련 기술의 공식 문서를 참고하는 것이 유용하다. 아래에 학습에 도움이 될만한 사이트를 링크를 통해 확인할 수 있다. 최신 머신러닝 모델인 SOTA 모델에 대해서도 접하기 좋은 사이트 링크도 있다.
Apache Spark™ - Unified Engine for large-scale data analytics
Data Lakehouse Architecture and AI Company - Databricks
