해석가능한 알고리즘의 종류를 알아보고, 각 알고리즘의 차이점을 분석해보고자 한다.
LIME 알고리즘
Lime 알고리즘은 작은 선형모델을 이용하여, 복잡한 모델의 판단을 대신 해석하는 대리 분석 알고리즘이다.
대리 분석이란 설명하고자 하는 원래의 모델이 지나치게 복잡해서 해석하기 어려운 경우, 해석 가능한 쉬운 모델을 사용하여 기존의 모델을 해석하는 기법을 의미한다.
한 예시로, SVM(Support Vector Machine)은 성능은 좋지만, 설명능력이 좋지 않다. 이 때, logistic regression 모델처럼 성능은 낮지만 설명능력이 좋은 모델을 사용하여 모델의 계수를 기반으로 하여 모델의 판단 매커니즘을 어림짐작할 수 있다,
이러한 경우, 전체 모델의 중요 변수를 파악한다는 점에서 Global 대리 분석이라고 할 수 있다.
엄밀히 말하면, SVM과 Logistic regression 간에는 학습방식의 차이가 분명 존재하지만, 많은 경우에서 유용한 해석을 제공해주고 있기 때문에 model-agnostic(모델에 관계없이 적용 가능한) 이라는 장점이 있다.
전체 모델의 중요 변수를 새로운 모델로 대체해서 파악하는 방법을 Global(전역적) 대리분석이라고 부른다.
반대로 개별 샘플에 대한 모델의 판단을 분석하는 방법을 Local(지역적) 대리분석이라고 한다.
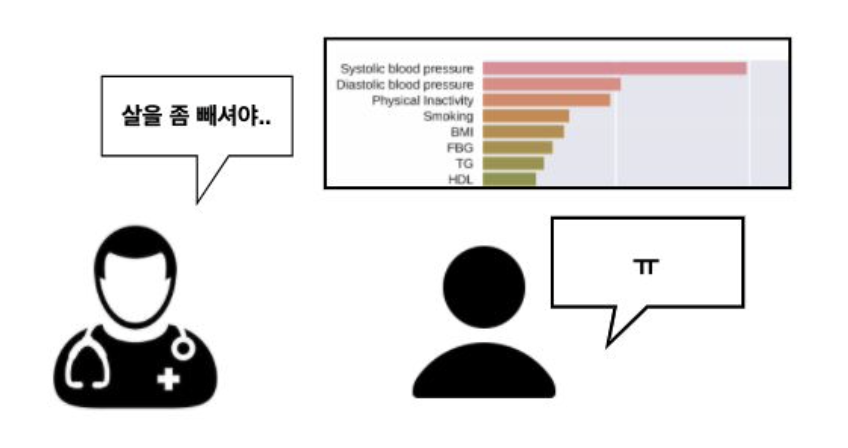
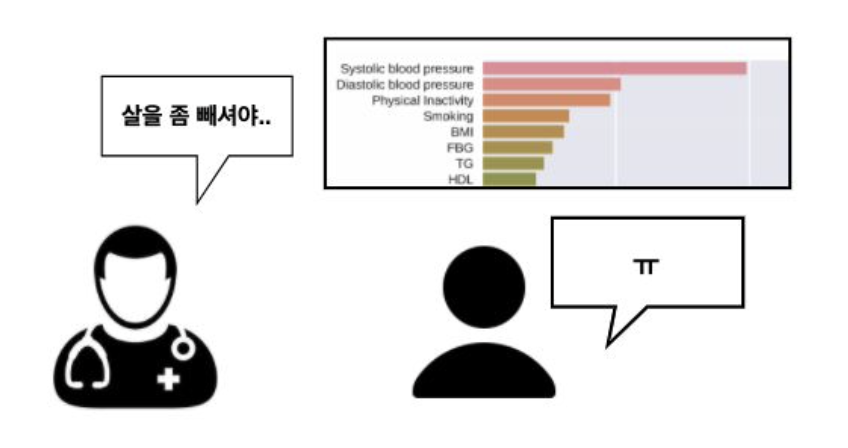
지역적인 설명은 비즈니스 상황에서 더욱 중요한 경우가 많다. 예를 들어, 개인의 채무 불이행 여부를 예측하거나, 1년 내 뇌졸중의 발병 여부를 예측하는 모델을 판단을 설명하고자 할 때, 지역적 대리분석 기법을 적용할 수 있다.

LIME은 Local Interpretable Model-agnostic Explanations 를 의미한다. 모델에 관계없이 지역적으로 설명가능한 알고리즘이라는 의미를 담고 있다.
예측을 내림에 있어 어떤 feature가 사용되었는지, 한 샘플에 내려진 판단이 어떻게 내려진 것인지를 분석해준다. 이 때, 사용된 모델과 무관하에 사용할 수 있는 알고리즘을 의미한다.
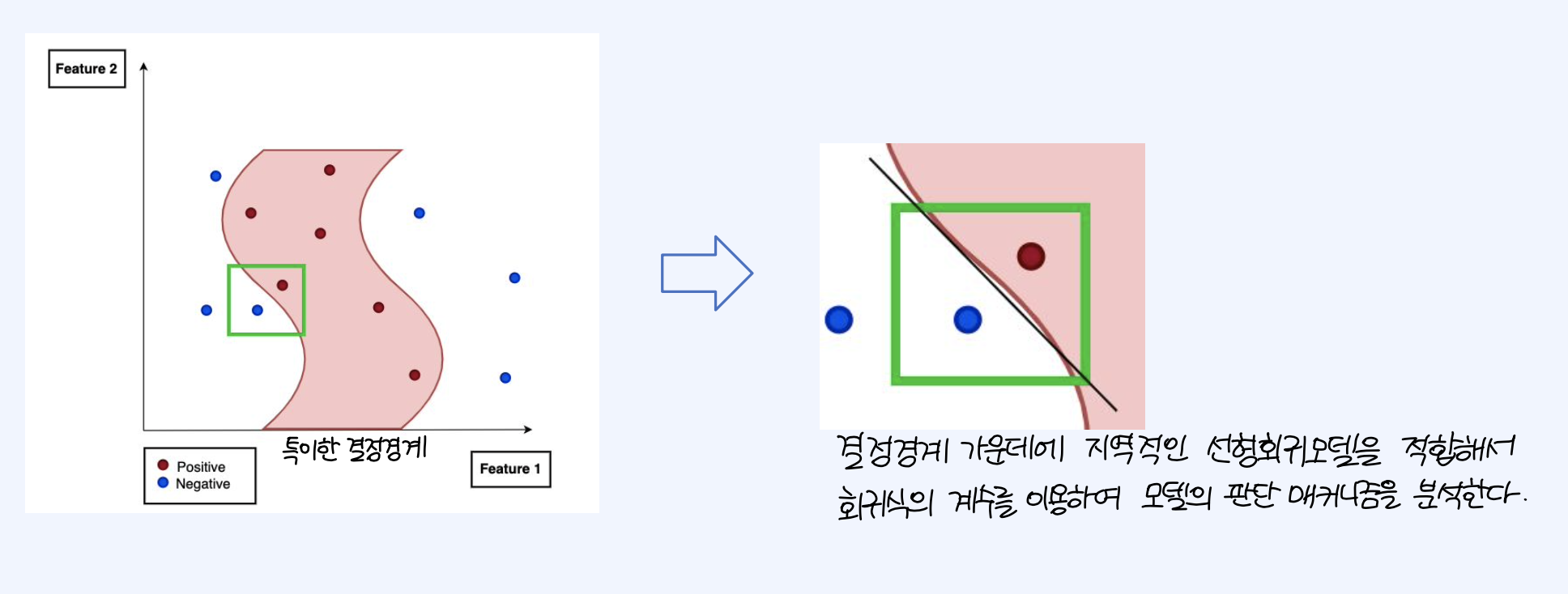
Lime은 특정 sample point에 대하여, 결정경계 가운데에 지역적인 선형회귀모델을 적합해서 회귀식의 계수를 이용하여 모델의 판단 매커니즘을 분석하고자 하는 방식이다.

1. 원래 (Blue) Label 이었던 sample의 라벨링을 변경하고, 데이터를 뒤섞어 새로운 samples을 생성한다. 이 과정은 데이터 뒤섞기(permutation)라고 한다.
2. 뒤섞은 데이터와 기존 관측치 사이의 거리를 측정하여 향후 가중치로 활용한다. 가중치는 가까울수록 높은 가중치를 적용하게 된다.
3. black box 모델을 사용하여 새로운 데이터를 대상으로 예측을 수행
4. 뒤 섞은 데이터로부터 복잡한 모델의 출력을 가장 잘 설명하는 m개의 feature를 선택한다. 특정 feature 값을 변경하였더니, score 또는 likelihood가 크게 변동되었다고 하면 해당 feature는 중요한 feature라고 간주할 수 있다.
5. 뽑힌 m개의 feature로 단순한 모델을 적합시키고, 앞서 계산한 거리차이측정값을 가중치로 사용한다.
6. 단순한 모델의 가중치는 곧 복잡한 모델의 local한 행동을 설명하는데 사용된다.
Lime 알고리즘의 손실함수에서 regularization term(정규화 텀)의 존재를 확인할 수 있다. 이는 너무 많은 feature를 이용하면, 아무리 단순한 모델일지라도 해석하기 어렵기 때문에, Lasso(L1규제)로 coefficient를 0으로 만드는 정규화 term을 가지게 된 것이다.
SHAP 알고리즘
SHAP 알고리즘은 피처의 기여도를 기반으로 하여 전체 모델 또는 개별 대한 변수의 중요도를 설명해주는 알고리즘이다.
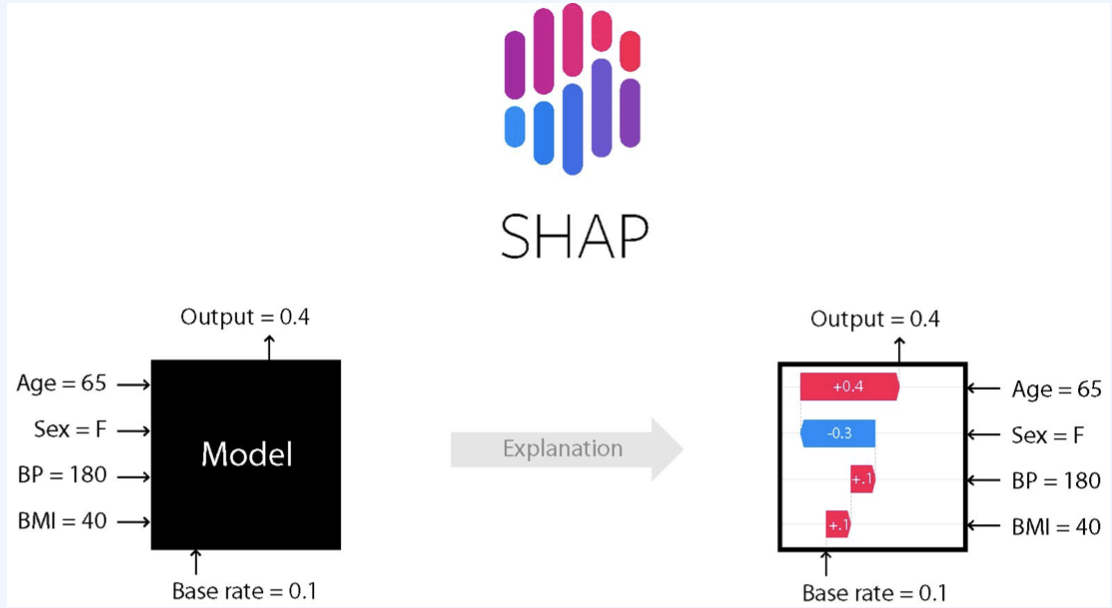
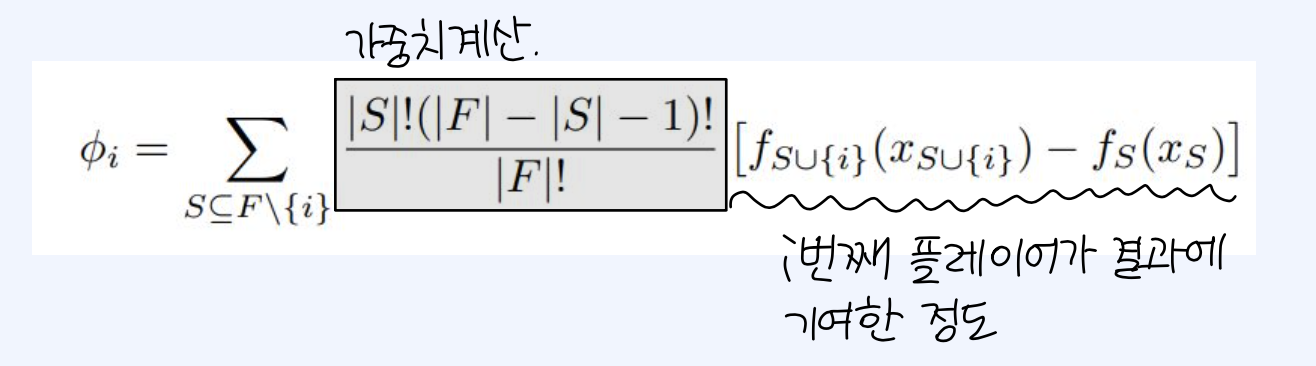
sharpley value는 게임이론에서 도입된 개념으로, 전체 결과에 대한 기여도에 따라 게임 내 각 플레이어에게 공을 공평하게 나눌 수 있도록 계산한 값을 의미한다. 이 개념을 차용하여 SHAP 알고리즘에서는 feature가 추가 될 때, feature가 존재하다가 존재하지 않았을 때 예측값이 얼마나 변화하는지, 가능한 모든 feature combination에 대한 평균을 구하는 방식이다.
EBM 알고리즘
EBM(Explainable Boosting Model)
복잡한 알고리즘일수록 성능은 높으나 해석이 어려워진다는 Performance - Explainability Trade-off 이 있다.
비즈니스적인 목적을 위해 설명 가능성이 필요할지라도, 앞서 배운 SHAP이나 LIME과 같은 대체적인 알고리즘에 의존할 수 밖에 없다.
EBM 알고리즘은 MS에서 공개한 InterpretML에 탑재된 알고리즘의 하나로, Glassbox 모델이라는 특성을 가진다. 자기 자신을 쪼갠 함수를 더해서 모델의 예측값이 어떻게 나왔는지 직관적으로 설명할 수 있게 해준다.
더불어 Boosting과 Bagging과 같은 학습 기반의 기법을 통해 성능을 확보하고 있다. pairwise interaction을 모델링함으로써 설명가능성을 동시에 보장한다.
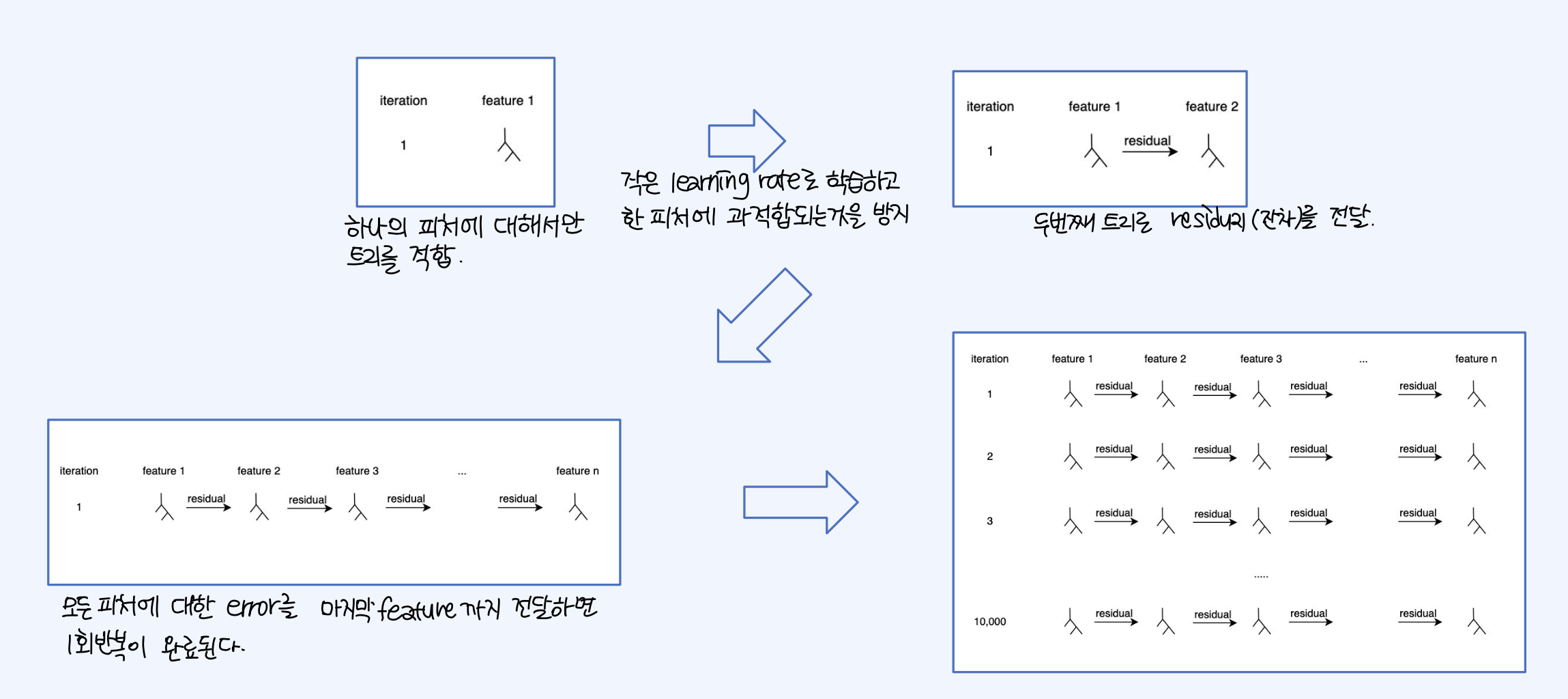
EBM 학습 방식은, 처음에 하나의 피처에 대해서만 트리를 적합시킨다. 작은 learning rate로 학습하여 한 피처에 대해서 과적합되는 것을 방지한다. 이 결과로 발생된 residual을 다음 트리에 전달한다. 그리고 모든 피처에 대한 residual 계산이 이루어지고 마지막 모델에 전달되어, 마지막 feature 학습이 종료되면 iteration 1회가 수행완료된다.
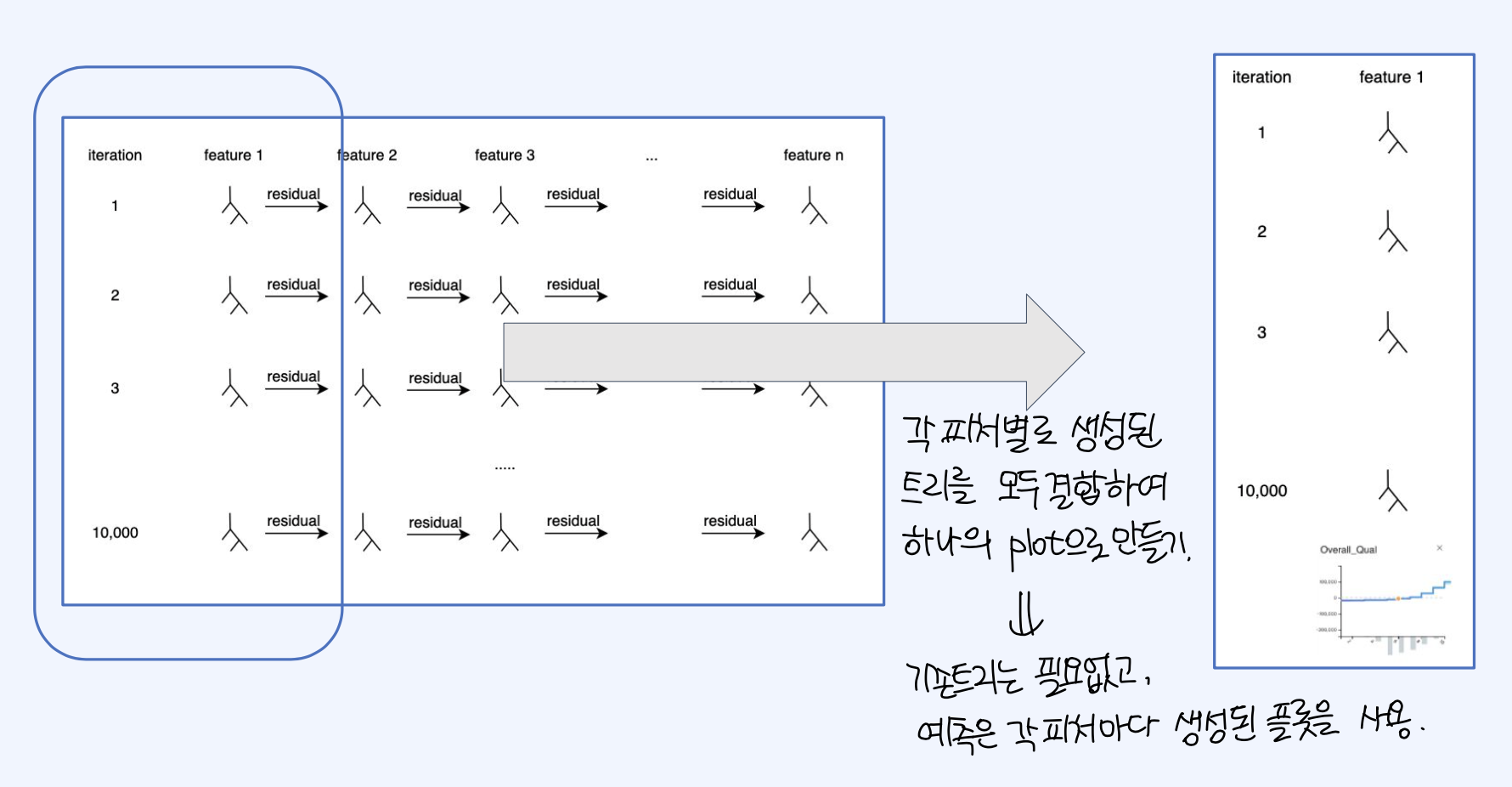
반복수행을 n번 한 이후에, 각 feature 별로 생성된 트리를 모두 결합하여 하나의 plot으로 만들 수 있다. 이 경우, 예측은 생성된 plot을 기반으로 이루어지기 때문에, 기존의 tree는 필요하지 않게 된다.
