End-to-end ML Project
-
ML Project의 step
- 프로젝트에 대한 큰그림 이해 (frame the problem)
- 데이터 수집 또는 데이터 살펴보기 (EDA)
- 데이터 시각화 하기 ( to gain insights )
- 머신러닝 학습을 위한 데이터 준비하기 (데이터 전처리)
- 모델선택과 학습
- 적절한 test set 확보하였는지에 대한 것도 시각화를 통해서 검증할 것
- 편향된 test data set이 아닌지 확인
- 적절한 test set 확보하였는지에 대한 것도 시각화를 통해서 검증할 것
- 파라미터 미세조정
- 모델 평가
- 배포(launch, deployment)
- 배포가 끝이 아니다… 새로운 데이터에 대한 학습, 업데이트가 지속적으로 이루어져야 한다
-
Create a Test Set

- 특정 feature가 prediction value에 중요한 영향을 끼친다고 했을 때,
- test set에서도 특정 feature에 대한 다양한 categories가 고르게 나타나는지 확인하는 과정이 필요하다
- data imbalance 문제가 발생하지 않도록 주의한다
- 특정 feature가 prediction value에 중요한 영향을 끼친다고 했을 때,
-
Looking for Correlations
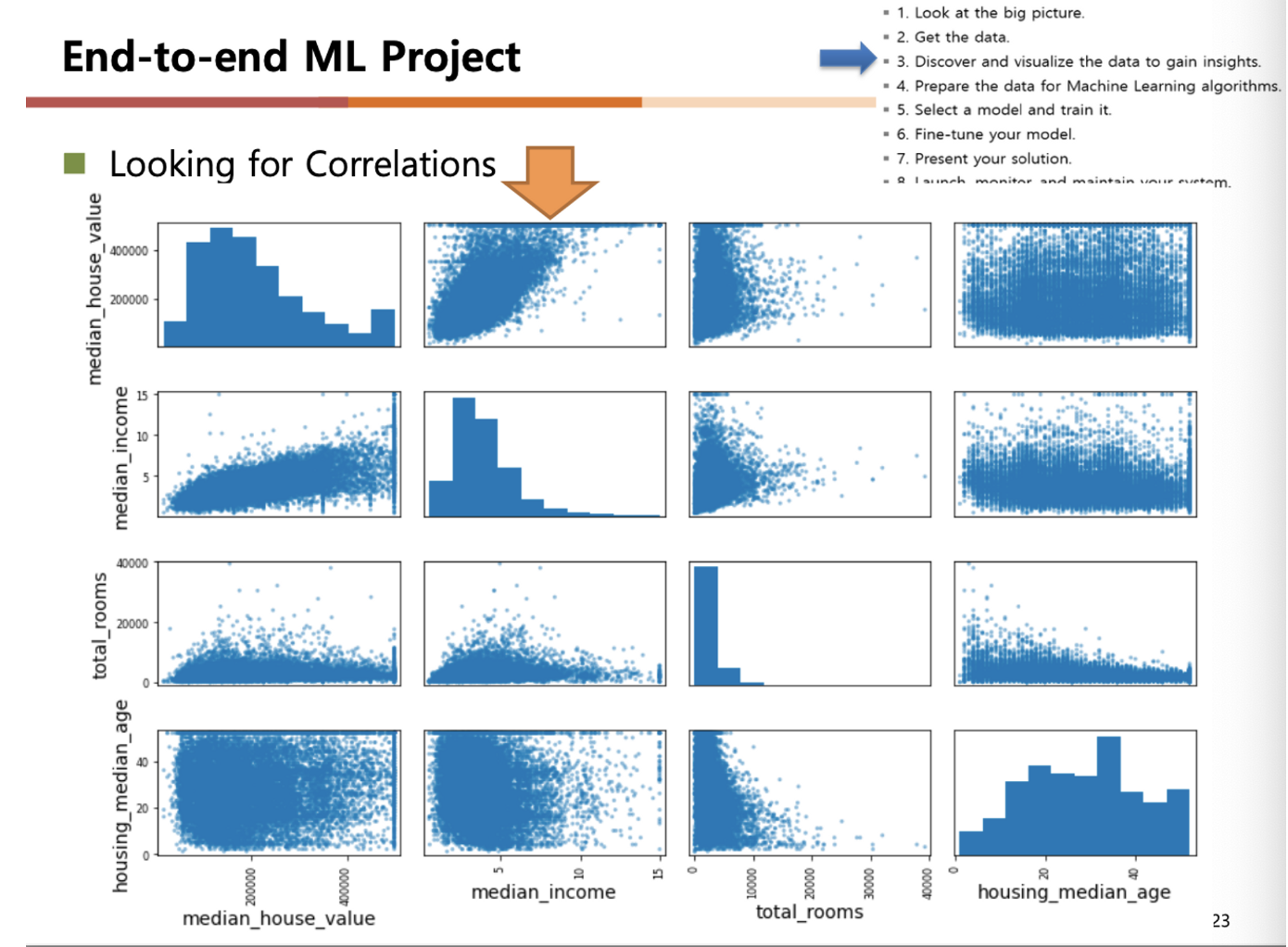
- 특징에 관계없이 특정치에 편향된 데이터들은 데이터 학습함에 있어 피해야 할 데이터-
Data Cleaning - 결측치 처리 (missing value)
-
missing value를 처리하는 3가지 방법
- missing value가 나타나는 tuple(row) 제거
- missing value가 나타나는 attribute(feature) 속성 자체를 제거
- missing value를 some value로 filling (zero, mean, median etc)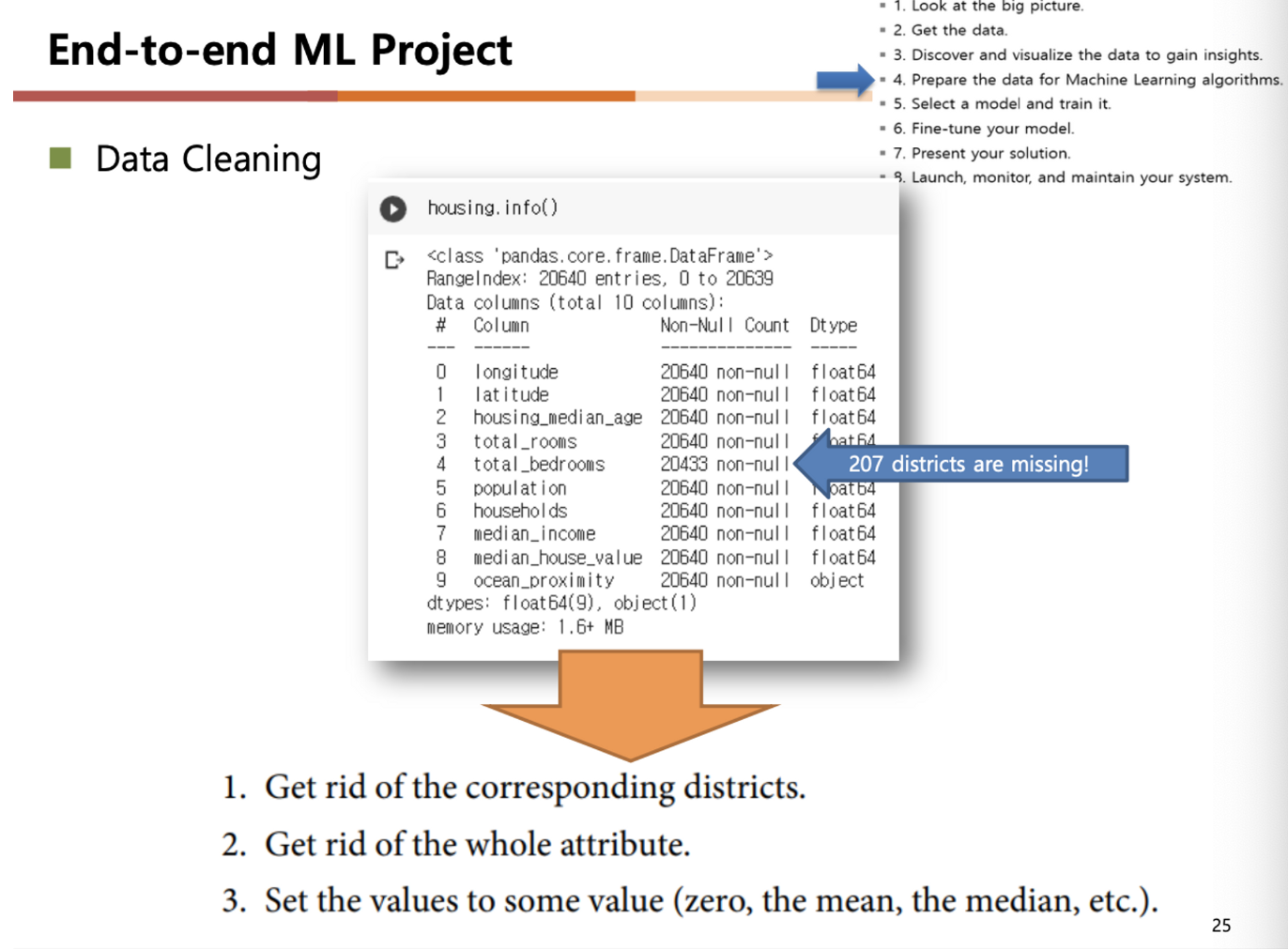
-
missing value가 나타나고 있는 total_bedrooms에 대해서 부족한 207개의 데이터 값을 계산해서 넣어줄 수 있다
-
-
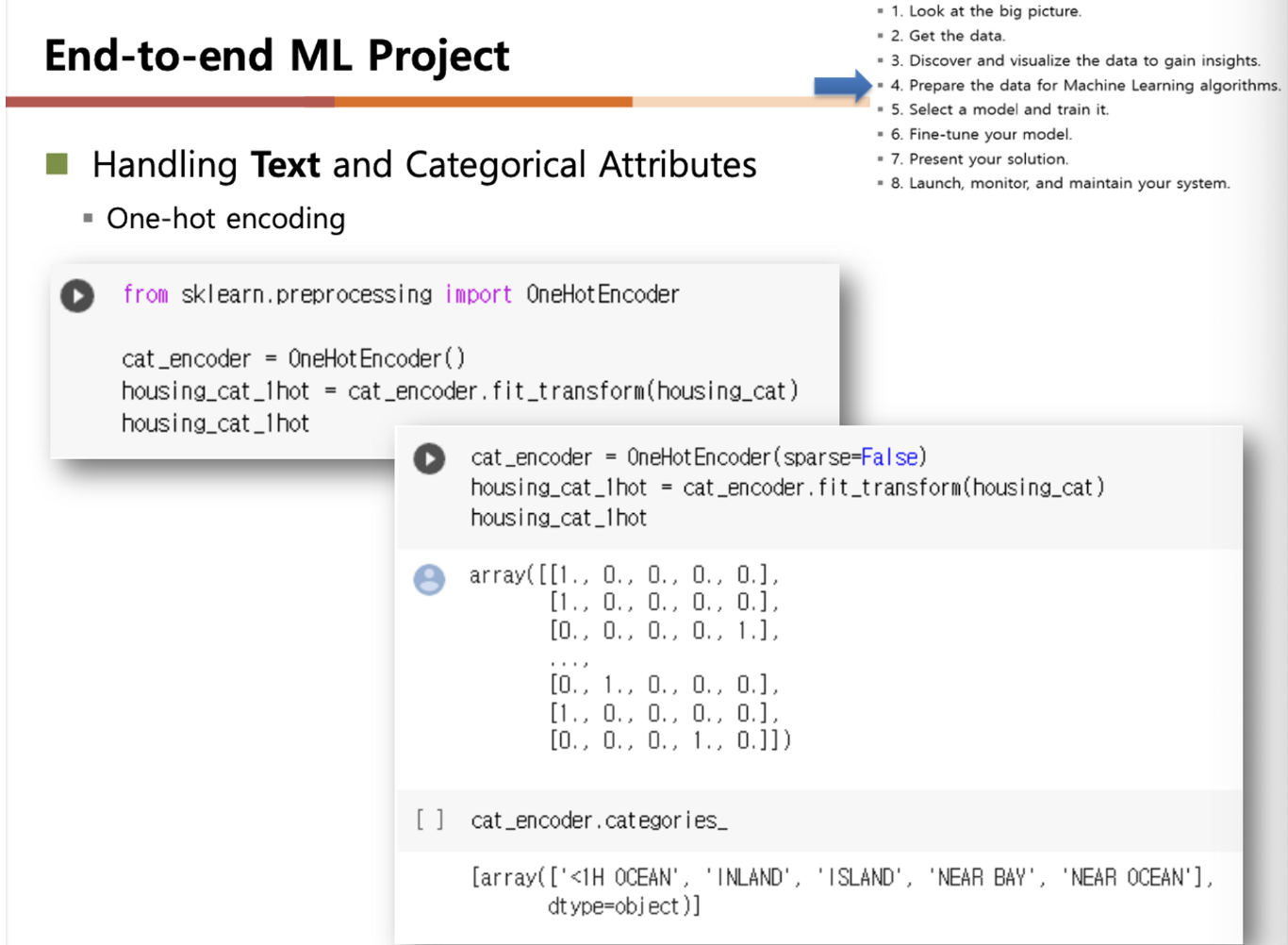
Handling Text and Categorical Attributes
- categorical attribute를 어떻게 다룰 것인가? ⇒ 수학적 연산이 불가
- 대부분 머신러닝 알고리즘은 숫자로 작업하는 것을 선호
- text ⇒ number converting (encoding)이 필요함
- one-hot encoding
- 단순 순열 숫자로 나타내지 않은 이유는, 숫자값 자체에 의미가 있다고 머신러닝모델이 판단할 수 있기 때문에, 숫자의 위치에 따른 의미를 부여하는 방식
- 숫자의 위치가 중요할 뿐, 순서가 중요한 것은 아님
-
Feature Scaling

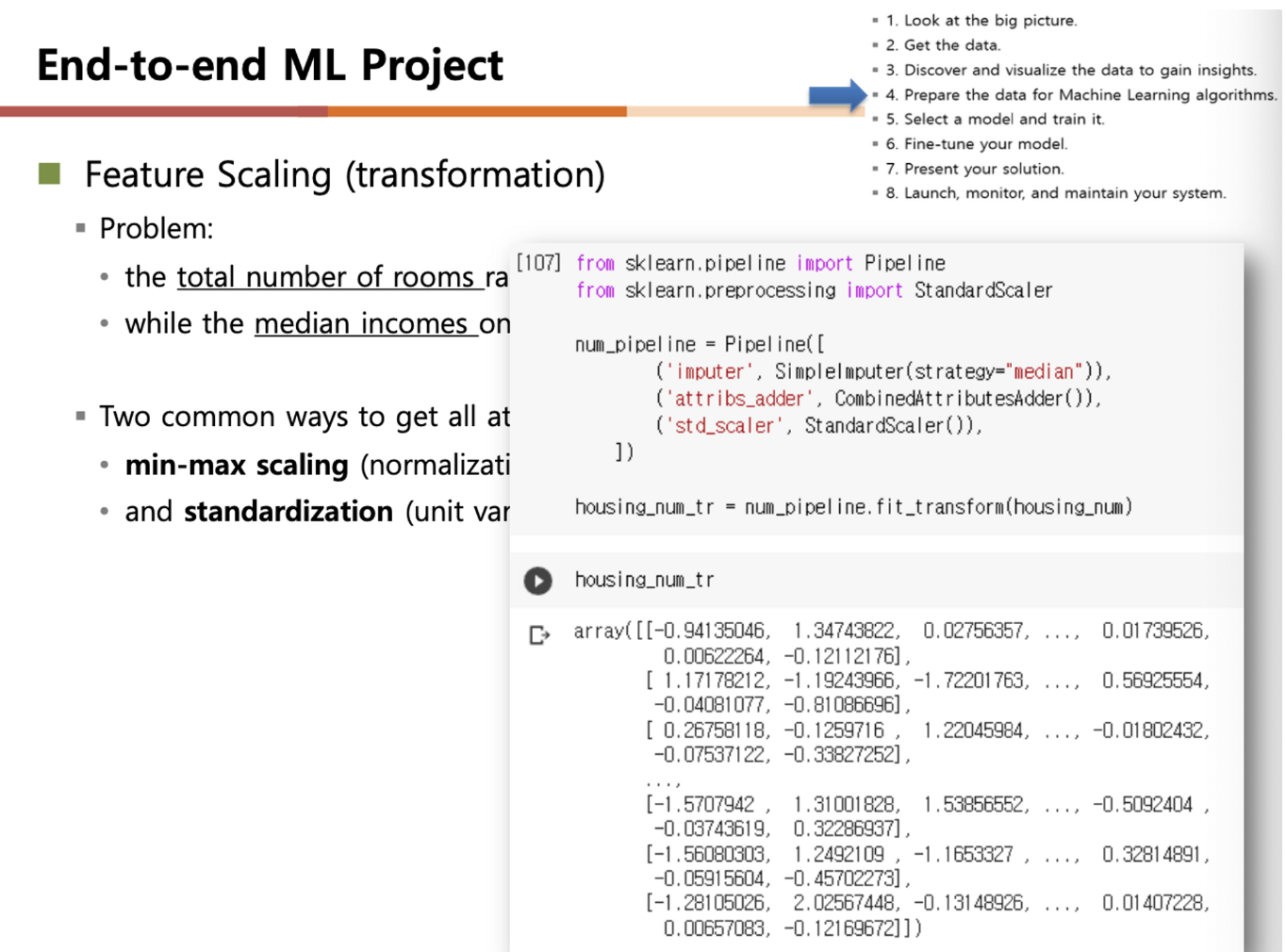
- min-max scaling 방식
- 소수의 큰 값 또는 작은 값에 의한 영향을 최소화하기 위해, 전체 데이터 값을 0~1사이 범위로 표현하는 방식
- standardization
- 데이터 값들의 분포를 적용한 표준화 방식 (평균, 표준편차)
- Training and Evaluation on the Training Set
- Linear Regression - 정확한 값을 예측하기 보다는 유사값을 예측하는 경우 적합
- Decision Tree Regression
- Train data 한정, 정확도를 높게 끌어올리는 model ⇒ Test data에 대한 정확도가 높지 않을 수 있다 ⇒ 이러한 단점을 보완하기 위해서, Decision Tree 를 여러 번 생성하여 mean 값을 살펴보는 Random Forest Regression 방식을 사용할 수 있음
- Train data 한정, 정확도를 높게 끌어올리는 model ⇒ Test data에 대한 정확도가 높지 않을 수 있다 ⇒ 이러한 단점을 보완하기 위해서, Decision Tree 를 여러 번 생성하여 mean 값을 살펴보는 Random Forest Regression 방식을 사용할 수 있음
- Fine-Tuning 파라미터 미세 조정
- Grid Search
- 균일하게 grid를 그려서 모든 parameter 조합 중 최적을 찾음
- 장점 : 알아서 더 좋은 파라미터를 찾아줌
- 단점 : 모든 parameter를 search → 오래 걸림
- Randomized Search
- hyper-parameter space가 굉장히 클 때, 임의의 parameter를 search
- Ensemble Methods
- 최적의 성능을 보이기 위해 , 여러 모델들을 조합하는 방식
- Decision Tree 가 특정 train data에 편향된 결과가 나온다 할지라도, 다양하게 편향된 decision Tree를 조합하는 Random Forest 방식을 사용하면 더 좋은 결과를 얻을 수도 있음
- Grid Search

데이터분석&엔지니어링이 가능한 AI 서비스 개발자를 꿈꿉니다:)