다층 퍼셉트론(MLP)
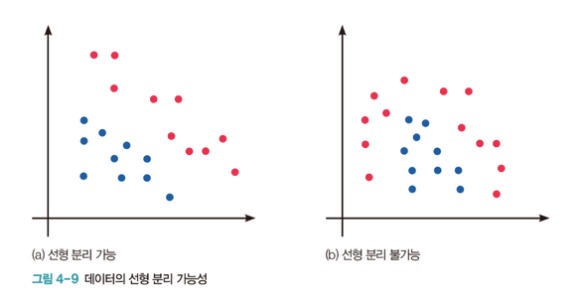
- 단일 선형분리 만으로는 분리 불가능한 문제를, 여러 개의 선을 이용하면 분리할 수 있음
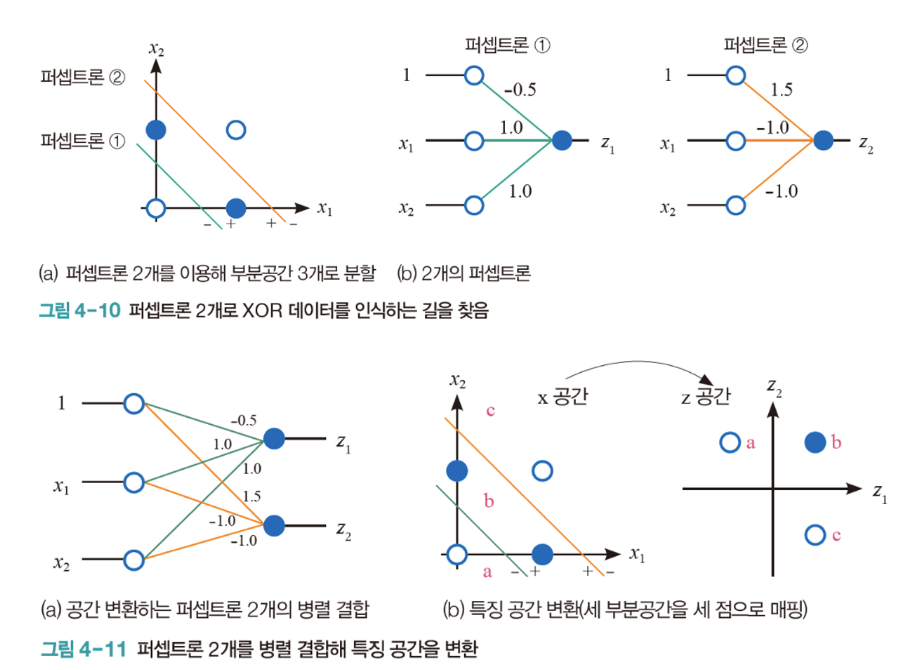
- (x0, x1, x2) 로 표현되던 feature space → (z1, z2) feature space로 변환
- 축을 변환시키면, 쉽게 선형 분리가 가능해 질 수 있다.
- 퍼셉트론 1과 퍼셉트론 2는 feature space를 변환하기 위해 사용
- 그렇다면, 축의 변환을 어떻게 할 수 있는가?
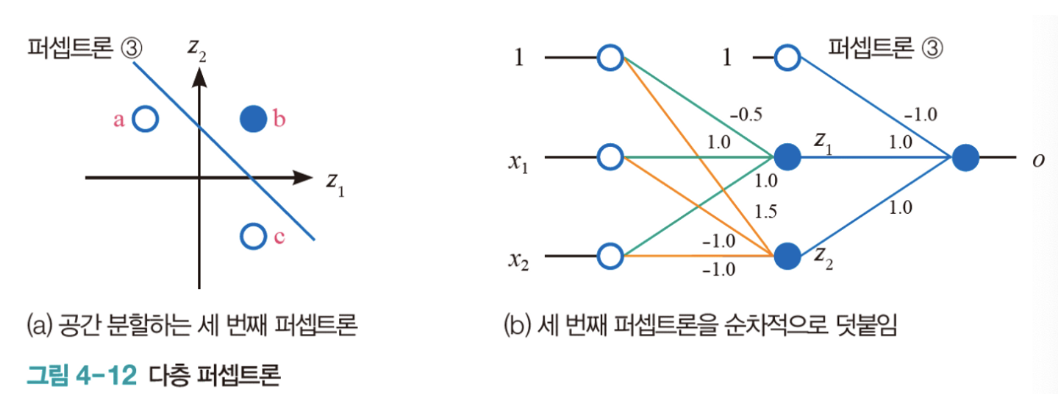
- 퍼셉트론3 은 이전 퍼셉트론 층에 의해서 변환된 feature space 내의 값을 input으로 하여 output을 산출하는 퍼셉트론 층이다.
- 단순히 층에서 퍼셉트론을 병렬배치 한 것이 아니라, 순차적으로 쌓기
[예제] XOR를 푸는 다층 퍼셉트론
신경망을 공간 변환기로 볼 수 있음
- 원래는 선형 분리가 불가능한 문제, 초기의 feature space의 값을, 선형분리가 가능하도록 퍼셉트론을 병렬 배치를 통해 feture space를 변환할 수 있다
- 이러한 feature space를 임시 공간 ⇒ 은닉층, 은닉 공간이라 함
- 이전 공간보다 분류에 더 유리하도록 학습
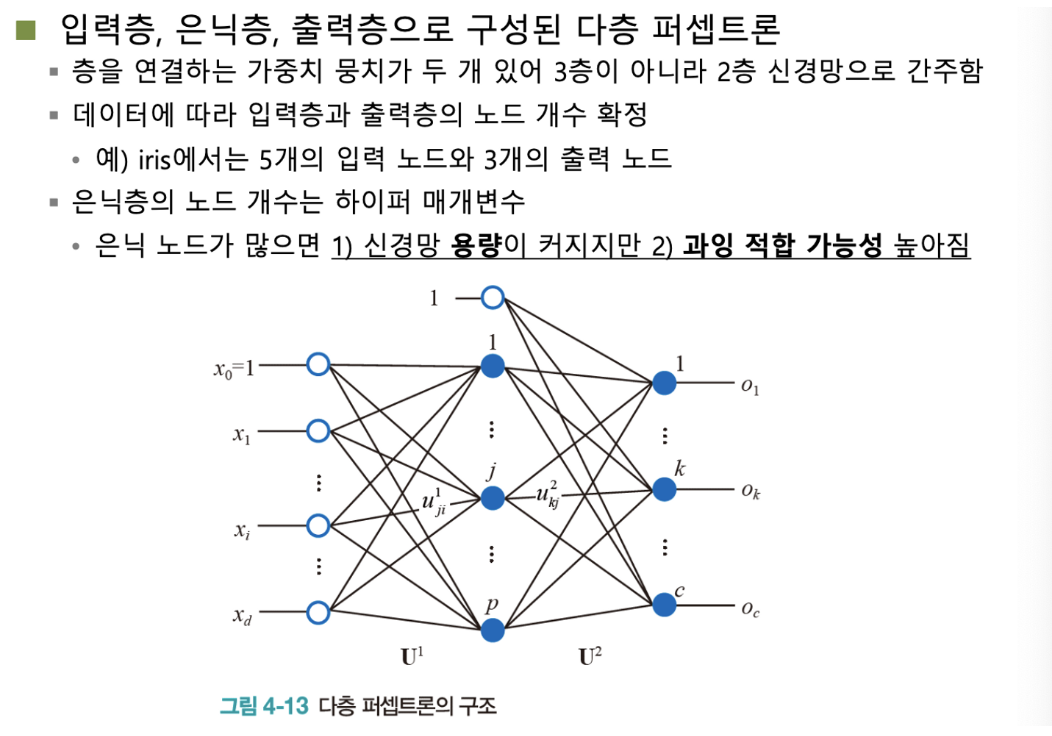
- 입력 데이터 개수에 따라, 입력 층의 노드 개수를 결정
- 출력 데이터 개수에 따라, 출력 층의 노드 개수를 결정
- 그렇다면, 은닉층의 노드 개수는?, 은닉층의 깊이는 어떻게 결정할 수 있는가?
- 은닉층의 노드 개수는 하이퍼 파라미터 ( 사용자의 입력에 따라 결정 )
- 초기 값을 지정하고, 최적화를 통해 최적의 노드 개수를 찾을 수 있다
- 은닉층의 노드 개수가 많으면, 신경망 용량이 커지고, 과적합 가능성이 높아짐
- 학습시간이 오래 걸릴 수 있고, 일반화 성능이 떨어질 수 있다
- 아래 첨자에 유의할 것
- 오른쪽 첨자가 이전 층의 노드, 왼쪽 첨자가 다음 층의 노드를 의미

- [Activation Function] ReLU
- 은닉층에서 가장 많이 사용되는 활성 함수
- 왜 많이 사용할까?
- 기존에는 sigmoid 함수를 많이 사용하였으나, 시그모이드는 출력값이 0 ~ 1가 나옴에 따라, 시간이 지날수록, 0에 수렴하는 기울기 소실 문제가 많이 발생할 수 있다.
- ReLU는 양수 범위에서는 자기 자신 값을 반환하므로, 기울기 소실문제가 발생하지 않고, 음수인 경우 0을 반환하므로, +/-가 반복되는 신호에서 - 신호 흐름을 차단할 수 있다.
- 학습 속도와 가중치 업데이트 속도가 매우 빠르다
- 입력 값이 음수인 경우, 기울기가 0이 되어 가중치 업데이트가 되지 않는 한계점이 존재함
- 기울기 소실을 방지하기 위한 함수이기 때문에, 은닉층에서만 사용할 것
- 0에서 미분이 되지 않는 문제점 또한 있다
- [Activation Function] softmax
MLP 학습 방법

- 손실함수 J 에 vertical line이 두 개가 있다
- 제곱했는 계산에 root 계산이 적용되었음을 의미 (손실함수값의 과대화 방지)
- RMSE ⇒ Root of MSE , 평균제곱오차에 제곱근 계산이 적용됨
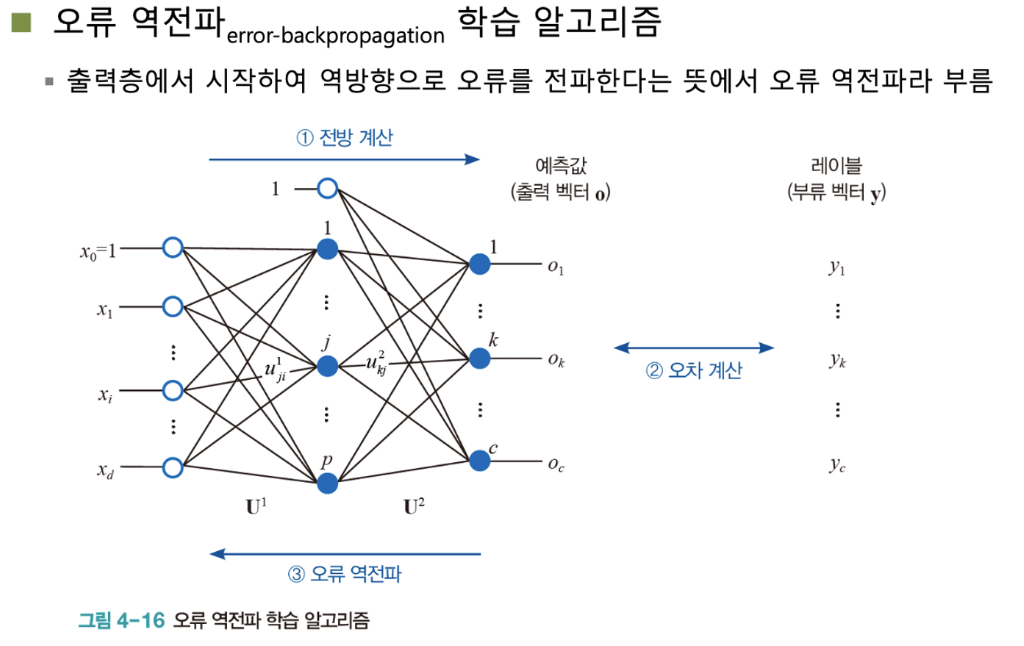
- 오차를 계산하고, 손실을 줄여나갈 수 있는 가장 좋은 방법은 예측값을 산출하는 가장 마지막층의 가중치부터 점진적으로 수정해 나가는 것이 가장 좋다
- 모델 학습과 반대 방향으로의 가중치 개선 ⇒ 오류 역전파
MLP 하이퍼 파라미터
- Hidden layer의 # node
- 다양한 하이퍼 파라미터들이 존재


데이터분석&엔지니어링이 가능한 AI 서비스 개발자를 꿈꿉니다:)