[Contents]
- File / Exception
- Log Handling
- Python data handling
[File / Exception]
- 프로그램을 제대로 만들기 위해 알아야 하는 예외 처리와 파일 다루기에 대해서 배운다.
- 대부분의 경우 우리가 만드는 프로그램에는 우리가 예상치 못한 오류가 생기곤 한다.
- 이를 해결하기 위해서 사전에 모든 경우를 다 지정해서 대비하는 경우도 있지만, 특정 상황에서 발생할 수 있는 예외를 포괄적으로 지정해서 대비하는 경우도 있다.
- 또, 실제 프로그램을 작성할 때는 파일에 존재하는 데이터를 사용하는 경우가 많다.
- 추가적으로 여러가지 프로그램을 진행하면서 기록을 남기는 로깅에 대해서도 배운다.
- 로그 데이터를 남기는 건 오늘날 데이터 기반의 애플리케이션 개발에서 매우 중요한 이슈가 되고 있다.
- 로그 데이터를 설계하는 것이 하나의 분야로 자리잡고 있을 만큼 매우 관심을 받고 있다.
- 프로그램 사용할 때 일어나는 오류들
- 주소를 입력하지 않고 배송 요청
- 저장도 안 했는데 컴퓨터 전원이 나감
- 게임 아이템 샀는데 게임에서 튕김
Exception
1) 예상 가능 한 예외
2) 예상이 불가능 한 예외
- 예상 가능한 예외
- 발생 여부를 사전에 인지할 수 있는 예외
- 사용자의 잘못된 입력, 파일 호출 시 파일 없음
- 개발자가 반드시 명시적으로 정의 해야함
- 예상이 불가능한 예외
- 인터프리터 과정에서 발생하는 예외, 개발자 실수
- 리스트의 범위를 넘어가는 값 호출, 정수 0으로 나눔
- 수행 불가시 인터프리터가 자동 호출
- 예외 처리 (Exception Handling)
- 예외가 발생할 경우 후속 조치 등 대처 필요
1) 없는 파일 호출 -> 파일 없음을 알림
2) 게임 이상 종료 -> 게임 정보 저장
- 명시적으로 막는 방법 : if문을 사용, exception handling
- 프로그램 = 제품, 모든 잘못된 상황에 대처가 필요
- 예외가 발생할 경우 후속 조치 등 대처 필요
Exception Handling
- try ~ except 문법
try:
예외 발생 가능 코드
except <Exception Type>: # 완전히 다른 exception type가 들어가 있으면 exception을 발견하지 못한다.
예외 발생시 대응하는 코드- 0으로 숫자를 나눌 때 예외처리 하기
for i in range(10):
try:
print(10 / i)
except ZeroDivisionError:
print("Not divided by 0")-
Built-in Exception: 기본적으로 제공하는 예외
Exception 이름 내용 IndexError List의 Index 범위를 넘어갈 때 NameError 존재하지 않은 변수를 호출 할 때 ZeroDivisionError 0으로 숫자를 나눌 때 ValueError 변환할 수 없는 문자/숫자를 변환할 떄 FileNotFoundError 존재하지 않는 파일을 호출할 때 -
try ~ except ~ else
try:
예외 발생 가능 코드
except <Exception Type>:
예외 발생시 동작하는 코드
else:
예외가 발생하지 않을 때 동작하는 코드- try ~ except ~ finally
try:
예외 발생 가능 코드
except <Exception Type>:
예외 발생시 동작하는 코드
finally:
예외 발생 여부와 상관없이 실행됨- raise 구문
- 필요에 따라 강제로 Exception을 발생
raise <Exception Type>(예외정보)
while True:
value = input("변환할 정수 값을 입력해주세요")
for digit in value:
if digit not in "0123456789":
raise ValueError("숫자값을 입력하지 않으셨습니다")
print("정수값으로 변환된 숫자 -", int(value))- assert 구문
- 특정 조건에 만족하지 않을 경우 예외 발생
- 특정 조건에 만족하지 않아 코드를 사전에 미리 멈추는 경우는 굉장히 긴 코드 일 경우 시간과 resource의 사용을 줄인다
- 사전에 사용자에게 변수를 제대로 쓰고 있는지 확인하기 위해서 함수 제일 윗부분에 주로 사용한다
assert 예외조건
def get_binary_number(decimal_number):
assert isinstance(decimal_number, int) # True 혹은 False, False는 AssertionError를 발생. True는
return bin(decimal_number)
print(get_binary_number(10.0))File Handling
-
File System, 파일 시스템
- OS에서 파일을 저장하는 트리구조 저장 체계
-
file from wiki
- 컴퓨터 등의 기기에서 의미 있는 정보를 담는 논리적인 단위
- 모든 프로그램은 파일로 구성되어 있고, 파일을 사용한다.
-
파일의 종류
- 기본적인 파일 종류로 text파일과 binary 파일로 나눔
- 커퓨터는 text파일을 처리하기 위해 binary파일로 변환시킴 (예: pyc파일)
- 파일이라는 시스템을 저장할 때 기본적으로 사람 눈에는 text 파일이고 저장하지만 일반적으로 컴퓨터는 text파일을 저장하기 위해서 binary 형태로 파일을 변환을 시켜서 저장하기 때문에 모든 text 파일도 실제는 binary파일이다, ASCII/Unicode 문자열 집합으로 저장되어 사람이 읽을 수 있음
| Binary 파일 | Text 파일 |
|---|---|
| 컴퓨터만 이해할 수 있는 형태인 이진(법)형식으로 저장된 파일 | 인간도 이해할 수 있는 형태인 문자열 형식으로 저장된 파일 |
| 일반적으로 메모장으로 열면 내용이 깨져 보임(메모장 해설 부락) | 메모장으로 열면 내용 확인 가능 |
| 엑셀파일, 워드 파일 등등 | 메모장에 저장된 파일, HTML 파일, 파이썬 코드 파일 등 |
- Python File I/O
- 파이썬은 파일 처리를 위해 'open' 키워드를 사용함
f = open('<파일이름>', '접근모드')
f.close()| 파일 열기 모드 | 설명 |
|---|---|
| r | 읽기모드 - 파일을 읽기만 할 때 사용 |
| w | 쓰기모드 - 파일에 내용을 쓸 때 사용 |
| a | 추가모드 - 파일의 마지막에 새로운 내용을 추가 시킬 때 사용 |
- 파이썬의 File Read
- read() txt 파일 안에 있는 내용을 문자열로 반환
f = open('i_have_a_dream.txt', 'r') # 대상파일이 같은 폴더에 있을 경우
contents = f.read()
print(contents)
f.close()
# with 구문과 함께 사용하기
with open('i_have_a_dream.txt', 'r') as my_file:
contents = my_file.read() # 파일 전체를 list로 반환
print(type(contents), contents) # Type 확인
print(contents) # 리스트 값 출력
# 실행 시 마다 한 줄 씩 읽어 오기
# 파일 용량이 커서 한번에 메모리에 올릴 수 없을 경우 한 줄씩 읽어오는 방법을 사용해야한다.
with open("i_have_a_dream.txt", "r") as my_file:
i = 0
while True:
line = my_file.readline()
if not line:
break
print (str(i) + " === " + line.replace("\n","")) #한줄씩 값 출력
i = i + 1- 파이썬의 file write
# mode는 'w', encoding = 'utf8'
f = open("count_log.txt",'w' , encoding="utf8") # 한글 = utf8
for i in range(1, 11):
data = "%d번째 줄입니다.\n" % i
f.write(data)
f.close()
# mode는 'a'는 추가 모드
# a = append, 기존 파일에 덮어쓰기
with open("count_log.txt",'a', encoding="utf8") as f:
for i in range(1, 11):
data = "%d번째 줄입니다.\n" % i
f.write(data)- 파이썬의 directory 다루기
# os 모듈을 사용하여 Directory 다루기
import os
os.mkdir('log')
# 디렉토리가 있는지 확인하기
if not os.path.isdir('log'):
os.mkdir('log')
# 디렉토리가 있는지 확인하기 2
try :
os.mkdir('abc')
except FileExistsError as e:
print('already created')
# 디렉토리가 있는지 확인하기 3
os.path.exists('abc') # True/False
# 파일을 옮길때 사용하는 모듈 shutil
import shutil
source = 'i_have_a_dream.txt'
dest = os.path.join('abc', 'andrew.txt') # join = abc\\andrew.txt
shutil.copy(source, dest) # shutil.copy = 파일 복사 함수 - 최근에는 pathlib 모듈을 사용하여 path를 객체로 다룸
import pathlib
cwd = pathlib.Path.cwd()
cwd # WindowsPath('D:/workspace')
cwd.parent # WindowsPath('D:/')- Log 파일 생성하기
- 디렉토리가 있는지
- 파일이 있는지 확인 후
import os
if not os.path.isdir("log"):
os.mkdir("log")
if not os.path.exists("log/count_log.txt"):
f = open("log/count_log.txt", 'w', encoding="utf8")
f.write("기록이 시작됩니다\n")
f.close()
with open("log/count_log.txt", 'a', encoding="utf8") as f:
import random, datetime
for i in range(1, 11):
stamp = str(datetime.datetime.now())
value = random.random() * 1000000
log_line = stamp + "\t" + str(value) +"값이 생성되었습니다" + "\n"
f.write(log_line)- Pickle
- 파이썬의 객체를 영속화(persistence)하는 built-in 객체
- 객체는 메모리에 저장되어 있다
- 메모리는 파이썬의 인터프리터가 끝나면 객체도 메모리에서 사라진다
- 객체를 메모리에 영속화/저장을 해서 이후에도 사용하고 싶을때 Pickle을 사용한다
- 객체를 binary 파일로 저장
- 데이터, object 등 실행중 정보를 저장 -> 불러와서 사용
- 저장해야하는 정보, 계산 결과(모델) 등 활용이 많음
- 파이썬의 객체를 영속화(persistence)하는 built-in 객체
# pickle모듈로 객체를 저장
import pickle
f = open("list.pickle", "wb") # writebinary
test = [1, 2, 3, 4, 5] # 리스트 객체
pickle.dump(test, f) # dump = 리스트 객체를 f변수에 할당되어 있는 정보에 저장
f.close()
# 객체 불러오기
f = open("list.pickle", "rb") # readbinary
test_pickle = pickle.load(f)
print(test_pickle) # [1, 2, 3, 4, 5]
f.close()Log Handling
- 게임을 만들었는데 Hack쓰는 유저들 때문에 망할 수 있다
- 어떻게 잡을 수 있을까?
- 일단 상황을 기록하는것 부터 해야한다 (로그 남기기)
-
로그 남기기 - Logging
- 프로그램이 실행되는 동안 일어나는 정보를 기록으로 남기기
- 유저의 접근, 프로그램의 Exception, 특정 함수의 사용
- Console 화면에 출력, 파일에 남기기, DB에 남기기 등등
- 기록된 로그를 분석하여 의미있는 결과를 도출 할 수 있음
- 실행 시점에서 남겨야 하는 기록 - 유져를 분석하기 위한
- 개발 시점에서 남겨야하는 기록 - 에러를 사전에 잡기 위해서
-
print vs logging
- 기록을 print로 남기는 것도 가능함
- 그러나 Console 창에만 남기는 기록은 분석시 사용불가
- 때로는 레벨별(개발, 운영)로 기록을 남길 필요도 있음
- 모듈별로 별도의 ㅣogging을 남길 필요도 있음
- 이러한 기능을 체계적으로 지원하는 모듈이 필요함
-
logging 모듈
- Python의 기본 Log 관리 모듈
import logging
logging.debug("틀렸잖아!")
logging.info("확인해")
logging.warning("조심해!")
logging.error("에러났어!!!")
logging.critical("망했다...") - logging level
- 프로그램 진행 상황에 따라 다른 Level의 Log를 출력함
- 개발 시점, 운영 시점 마다 다른 Log가 남을 수 있도록 지원함
- DEBUG > INFO > WARNING > ERROR > Critical
- Log 관리시 가장 기본이 되는 설정 정보들을 관리
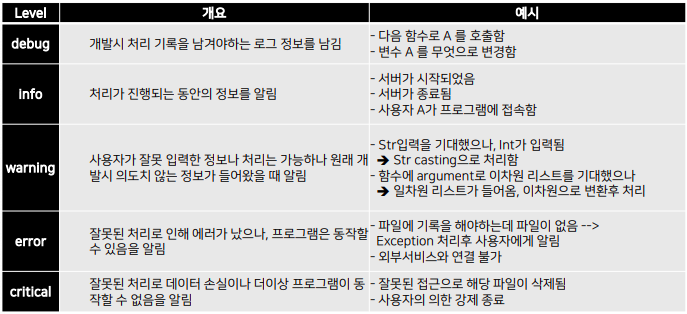
import logging
logger = logging.getLogger("main") # Logger 선언
stream_hander = logging.StreamHandler() # Logger의 output 방법 선언
logger.addHandler(stream_hander) # Logger의 output 등록 - 실제 프로그램을 실행할 땐 여러 설정이 필요
- 데이터 파일 위치
- 파일 저장 장소
- Operation Type 등
- 이러한 정보를 설정해줄 방법이 필요
1) configparser - 파일에
2) argparser - 실행 시점에
- configparser
- 프로그램의 실행 설정을 file에 저장함
- Section, Key, Value 값의 형태로 설정된 설정 파일을 사용
- 설정파일을 Dict Type으로 호출후 사용

import configparser
config = configparser.ConfigParser()
config.sections()
config.read('example.cfg')
config.sections()
for key in config['SectionOne']:
print(key)
config['SectionOne']["status"]- argparser
- Console 창에서 프로그램 실행시 Setting 정보를 저장함
- 거의 모든 Console 기반 Python 프로그램 기본으로 제공
- 특수 모듈도 많이 존재하지만(TF), 일반적으로 argparse를 사용
- Command - Line Option 이라고 부름

Logging 적용하기
- Log의 결과값의 format을 지정해줄 수 있음
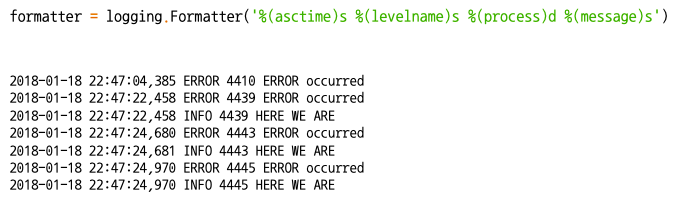
- 딥러닝 할 때는 굉장히 오랜시간 학습을 하기 때문에 중간중간 기록들을 남겨야(로깅) 하기 때문에 로깅의 개념을 알아두자!!
[Python data handling]
- 파이썬에서 다룰 수 있는 CSV, 웹, XML, JSON 네 가지 데이터 타입에 대해서 배운다
- CSV 파일 포맷은 어떠한 프로그래밍 언어든 데이터를 다루는 분야에서 가장 기본이 되는 타입형태이다
- 우리가 계속 써온 데이터 저장형태인 엑셀의 텍스트 데이터 형태로 이해하면 된다
- 매우 중요한 데이터 타입으로 파이썬으로 핸들링하는 것에 익숙해지는 것이 필요하다
- 다음으로 웹이다. 우리가 모두 알고 있듯이 이미 웹은 우리가 세상에서 가장 많은 정보를 제공하고 가장 많은 시간을 사용하고 있는 공간이다
- 이 정보를 어떻게 자동으로 확보할 것인지에 대해서 배운다
- 먼저 기본적인 웹을 표현하는 가장 기본적인 언어인 HTML에 대해서 배운다
- HTML은 웹에서 나타나는 정보의 표현 방법 중 가장 대표적인 방법 으로 거의 모든 정보를 HTML 분석으로 얻을 수가 있다
- 다음으로 그 HTML을 분석하기 위해 대표적인 방법인 정규표현식(regex) 에 대해서 배우게 된다
- 정규표현식은 텍스트 데이터 분석에 있어 가장 대표적인 분석 방법으로, HTML외에도 다양한 유형의 텍스트에서 특정 정보를 뽑아내는데 사용 한다
- 마지막으로 데이터를 저장하는 다양한 포멧중 하나인 XML(eXtensible Markup Languages) 과 JSON(JavaScript Object Notation) 에 대해서 다룬다
- XML 프로그래밍 언어에서 데이터를 저장하고 불러오는 전통적인 파일포맷은 흔히 레거시 시스템 (오래전에 구축된 시스템) 에서 raw파일을 저장하는 대표적인 포맷 이다.
- JSON은 이와 달리 모바일이 활발히 사용되면서 사용되기 시작하는 저장 포맷으로 웹에서 많이 사용되는 JavaScript의 문법을 활용하여 저장하는 포맷 이다
CSV (Comma separate Values)
- csv, 필드를 쉼표(,)로 구분한 텍스트 파일
- 엑셀 양식의 데이터 를 프로그램에 상관없이 쓰기 위한 데이터 형식 이라고 생각하면 쉽다
- 탭(TSV), 빈칸(SSV) 등으로 구분해서 만들기도 함
- 통칭하여 character-separated values(CSV) 부름
- 엑셀에서는 '다름 이름 저장' 기능으로 사용 가능
- csv 파일 읽기 예제
line_counter = 0 #파일의 총 줄수를 세는 변수
data_header = [] #data의 필드값을 저장하는 list
customer_list = [] #cutomer 개별 List를 저장하는 List
with open ("customers.csv") as customer_data: #customer.csv 파일을 customer_data 객체에 저장
while True:
data = customer_data.readline() #customer.csv에 한줄씩 data 변수에 저장
if not data: break #데이터가 없을 때, Loop 종료
if line_counter==0: #첫번째 데이터는 데이터의 필드
data_header = data.split(",") #데이터의 필드는 data_header List에 저장, 데이터 저장시 “,”로 분리
else:
customer_list.append(data.split(",")) #일반 데이터는 customer_list 객체에 저장, 데이터 저장시 “,”로 분리
line_counter += 1
print("Header :\t", data_header) #데이터 필드 값 출력
for i in range(0,10): #데이터 출력 (샘플 10개만)
print ("Data",i,":\t\t",customer_list[i])
print (len(customer_list)) #전체 데이터 크기 출력-
csv 객체로 csv처리
- Text파일 형태로 데이터 처리시 문장 내에 들어가 있는 "," 등에 대해 전처리 과정이 필요
- 파이썬에서는 간단히 CSV파일을 처리하기 위해 csv 객체를 제공함
-
csv 객체 활용
reader = csv.reader(f, delimiter = ',', quatechar = '"', quoting = csv.QUOTE_ALL)| Attribute | Default | Meaning |
|---|---|---|
| delimiter | , | 글자를 나누는 기준 |
| lineterminator | ₩r₩n | 줄 바꿈 기준 |
| quotechar | " | 문자열을 둘러싸는 신호 문자 |
| quoting | QUOTE_MINIMAL | 데이터 나누는 기준이 quotechar에 의해 둘러싸인 레빌 |
import csv
seoung_nam_data = []
header = []
rownum = 0
with open("korea_floating_population_data.csv","r", encoding="cp949") as p_file: # 맥은 encoding = 'utf8'
csv_data = csv.reader(p_file) #csv 객체를 이용해서 csv_data 읽기
for row in csv_data: #읽어온 데이터를 한 줄씩 처리
if rownum == 0:
header = row #첫 번째 줄은 데이터 필드로 따로 저장
location = row[7]
#“행정구역”필드 데이터 추출, 한글 처리로 유니코드 데이터를 cp949로 변환
if location.find(u"성남시") != -1:
seoung_nam_data.append(row)
#”행정구역” 데이터에 성남시가 들어가 있으면 seoung_nam_data List에 추가
rownum +=1
with open("seoung_nam_floating_population_data.csv","w", encoding="utf8") as s_p_file:
writer = csv.writer(s_p_file, delimiter='\t', quotechar="'", quoting=csv.QUOTE_ALL)
# csv.writer를 사용해서 csv 파일 만들기 delimiter 필드 구분자
# quotechar는 필드 각 데이터는 묶는 문자, quoting는 묶는 범위
writer.writerow(header) #제목 필드 파일에 쓰기
for row in seoung_nam_data:
writer.writerow(row) #seoung_nam_data에 있는 정보 list에 쓰기웹
-
우리가 늘 쓰는 그 것
- World Wide Web (WWW), 줄여서 웹 이라고 부름
- 우리가 늘 쓰는 인터넷 공간의 정식 명칭
- 데이터 송수신을 위한 HTTP 프로토콜 사용, 데이터를 표시하기 위해 HTML 형식을 사용
-
Web은 어떻게 동작하는가?
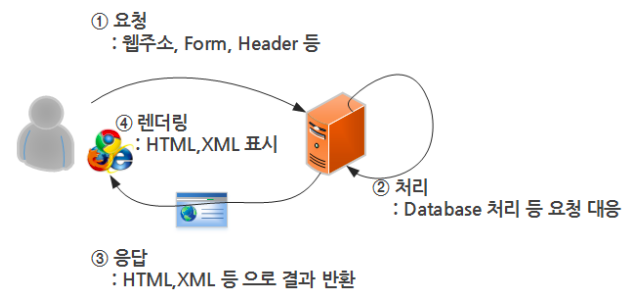
1) 서버에 요청
2) 서버에서 처리
3) 처리된 결과를 HTML파일에 사용자에게 보내준다.
4) 사용자는 HTML을 다운로드 받고 사용되는 browser가 렌더링해서 사용자에게 보여준다
- 왜 웹을 알아야 하는가?
- 정보의 보고, 많은 데이터들이 웹을 통해 공유됨
- 환율정보 : https://finance.naver.com/
- 날씨정보 : https//goo.gl/nwi8WE
- 미국 특허정보 : https://bit.ly/3pxFkjb
- HTML도 일종의 프로그램, 페이지 생성 규칙이 있음
- 규칙을 분석하여 데이터의 추출이 가능
- 추출된 데이터를 바탕으로 하여 다양한 분석이 가능
- 정보의 보고, 많은 데이터들이 웹을 통해 공유됨
HTML (Hyper Text Markup Language)
- 웹 상의 정보를 구조적으로 표현 하기 위한 언어
- 제목, 단락, 링크, 등 요소 표시를 위해 Tag 를 사용
- 모든 요소들은 꺽쇠 괄호 안에 둘려 쌓여 있음
- Hello, World # 제목 요소, 값은 Hello, World
- 모든 HTML은 트리 모양의 포함관계를 가짐
- 일반적으로 웹 페이지의 HTML 소스파일은 컴퓨터가 다운로드 받은 후 웹 브라우저가 해석/표시

정규식 (regular expression)
- 정규 표현식, regexp 또는 regex 등으로 불림
- 복잠한 문자열 패턴 을 정의하는 문자 표현 공식
- 특정한 규칙 을 가진 문자열의 집합을 추출
- 주민등록 번호, 전화번호, 도서 ISBN 등 형식이 있는 문자열을 원본 문자열로부터 추출함
- HTML 역시 tag를 사용한 일정한 형식이 존재하여 정규식으로 추출이 용이함
- 관련자료 : 자료
- 문법 자체는 매우 방대, 필요한 것들은 인터넷 검색을 통해 찾을 수 있음

-
정규식 연습장 활용하기
1) 정규식 연습장 연습장 으로 이동
2) 테스트하고 싶은 문서를 Text란에 삽입
3) 정규식을 사용해서 찾아보기. 이 페이지를 보세요 페이지
-
정규식 기본 문법 # 1
- 문자 클래스 [ ] : [와] 사이의 문자들과 매치 라는 의미
- 예: [abc] <- 해당 글자가 a,b,c중 하나가 있다.
- "-" 를 사용 범위를 지정할 수 있음
- 예: [a-zA-Z] : 알파벳 전체, [0-9] : 숫자 전체
- 문자 클래스 [ ] : [와] 사이의 문자들과 매치 라는 의미
-
정규식 기본 문법 - 메타 문자
- 정규식 표현을 위해 원래 의미 X, 다른 용도로 사용되는 문자
- . ^ $ * + ? { } [ ] \ | ( )
- . : 줄바꿈 문자인 \n를 제외한 모든 문자와 매칭
- : 앞에 있는 글자를 반복해서 나올 수 있음
- : 앞에 있는 글자를 1회이상 반복
- {m.n} : 반복 횟수를 지정
- ? : 반복 회수가 1회
- | : or
- ^ : not
- 정규식 표현을 위해 원래 의미 X, 다른 용도로 사용되는 문자
-
정규식 in 파이썬
- re 모듈을 import 하여 사용 : import re
- 함수 : search - 한 개만 찾기, findall - 전체 찾기
- 추출된 패턴은 tuple로 반환됨
XML (eXtensible Markup Lanaguage)
-
데이터의 구조와 의미를 설명하는 TAG(MarkUp)를 사용하여 표시하는 언어
-
TAG 와 TAG사이에 값이 표시되고, 구조적인 정보를 표현할 수 있음
-
HTML과 문법이 비슷, 대표적인 데이터 저장 방식
-
정보의 구조에 대한 정보인 스키마와 DTD 등으로 정보에 대한 정보(메타정보)가 표현되며, 용도에 따라 다양한 형태로 변경가능
-
XML은 컴퓨터(예: PC <-> 스마트폰) 간에 정보를 주고받기 매우 유용한 저장 방식으로 쓰이고 있음
-
XML 예제
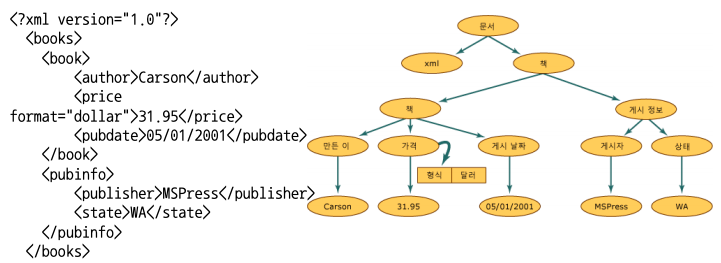
- XML도 HTML과 같이 구조적 markup 언어
- 정규표현식으로 parsing이 가능함
- 그러나 좀 더 손쉬운 도구들이 개발되어 있음
- 가장 많이 쓰이는 parser인 beautifulsoup으로 파싱
- BeautifulSoup
- HTML, XML등 Markup 언어 Scraping을 위한 대표적인 도구
- lxml 과 html5lib 과 같은 Parser(XML, HTML을 분석하는 도구)를 사용함
- 속도는 상대적으로 느리나 간편히 사용할 수 있음
JSON (JavaScript Object Notation)
- 원래 웹 언어인 Java Script의 데이터 객체 표현 방식
- 간결성 으로 기계/인간이 모두 이해하기 편함
- 데이터 용량이 적고, Code로의 전환이 쉬움
- 이로 인해 XML의 대체제로 많이 활용되고 있다

-
json 모듈을 사용하여 손 쉽게 파싱 및 저장 가능
-
데이터 저장 및 읽기는 dict type 과 상호 호환 가능
-
웹에서 제공하는 API는 대부분 정보 교환 시 JSON 활용
-
페이스북, 트위터, Github 등 거의 모든 사이트
-
각 사이트 마다 Developer API의 활용법을 찾아 사용
-
JSON Read
- JSON 파일의 구조 확인 -> 읽어온 후 -> Dict Type 처럼 처리

- JSON Write
- Dict Type으로 데이터 저장 -> json 모듈로 write

