[Contents]
1) pandas 1
2) 딥러닝 학습방법 이해하기
pandas 1
- panel data의 줄임말인 pandas는 파이썬의 데이터 처리의 사실상의 표준인 라이브러리이다
- pandas는 파이썬에서 일종의 엑셀과 같은 역할을 하여 데이터를 전처리하거나 통계 처리시 많이 활용하는 피복 테이블 등의 기능을 사용할 때 쓸 수 있다
- pandas 역시 numpy를 기반으로 하여 개발되어 있으며, R의 데이터 처리 기법을 참고하여 많은 함수가 구성되어 있어 기존 R 사용자들도 쉡게 해당 모듈을 사용할 수 있도록 지원하고 있다
- 구조화된 데이터의 처리를 지원하는 python 라이브러리
- 고성능 array 계산 라이브러리인 numpy와 통합하여, 강력한 '스프레드시트' 처리 기능을 제공
- 인덱싱, 연산용 함수, 전처리 함수 등을 제공함
- 데이터 처리 및 통계 분석을 위해 사용
series
- DataFrame 중 하나의 Column에 해당하는 데이터의 모음 Object
- column vector를 표현하는 object
- index값을 기준으로 series 생성
list_data = [1,2,3,4,5]
list_name = ['a','b','c','d','e']
example_obj = Series(data = list_data, index = list_name)
# data index에 접근하기
example_obj['a'] # 1
example_obj.astype(int) # 데이터 타입 변환
#값 을 리스트로 반환
example_obj.values
# 인덱스만 반환
example_obj.indexDataframe
- Data Table 전체를 포함하는 Object
- dataframe memory
- NumPy array-like
- Each column can have a different type
- Series를 모아서 만든 Data Table = 기본 2차원
Dataframe Indexing
- loc은 index이름, iloc은 index number
df.loc[1] # index location
df['age'].iloc[1:] # index positionDataframe handling
# Column에 새로운 데이터 할당
df.debt = df.age > 40
# column 삭제
del df['debt'] # 메모리 주소를 삭제
df = df.drop('debt', axis=1) selection and drop
#selection w/ column names
df['debt'].head(3)
df[['debt', 'age', 'name']].head(3)Dataframe Operations
s1 = Series(range(1,6), index=list('abcde'))
print(s1)
# a 1
# b 2
# c 3
# d 4
# e 5
s2 = Series(range(5,11), index = list('bcdeef')
print(s2)
# b 5
# c 6
# d 7
# e 8
# e 9
# f 10
s.add(s2) # or s1+s2, index 기분으로 연산수행, 겹치는 index가 없을 경우 Nan값으로 반환
# a NaN
# b 7.0
# c 9.0
# d 11.0
# e 13.0
# e 14.0
# f NaN- df는 column과 index를 모두 고려
- add operation을 쓰면 NaN값 0으로 변환
- operation types : add, sub, div, mul
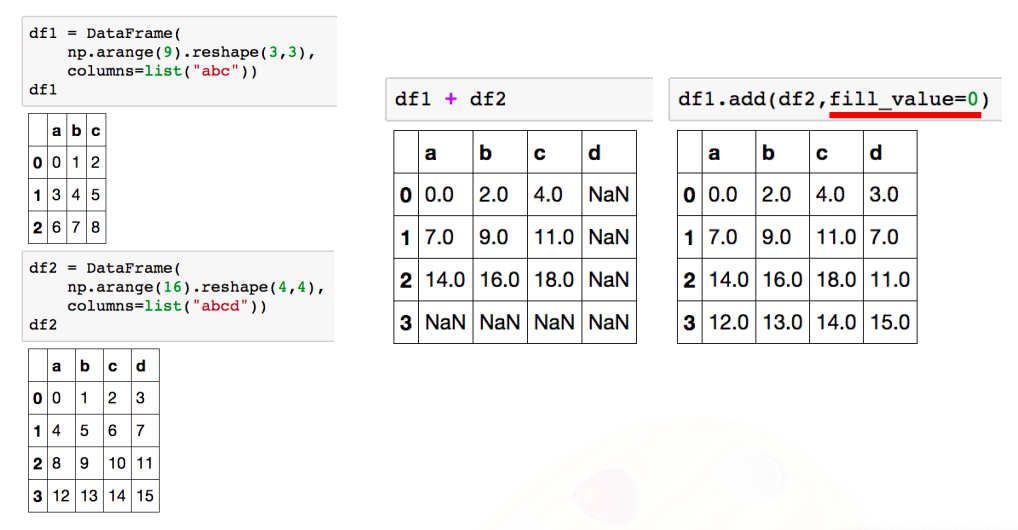
- series + dataframe

lambda, map, apply
- map for series
- pandas의 series type의 데이터에도 map 함수 사용가능
- function 대신 dict, sequence 형 자료등으로 대체 가능
s1 = Series(np.arange(10))
s1.map(lambda x: x**2).head(5)
# 0 0
# 1 1
# 2 4
# 3 9
# 4 16- replace function
- Map 함수의 기능중 데이터 변환 기능만 담당
- 데이터 변환시 많이 사용하는 함수
df.sex.replace({"male":0, "female":1})
df.sex.replace(['male','female'],[0,1], inplace=True)- apply for dataframe
- map 과 달리, series 전체(column)에 해당 함수를 적용
- 입력 값이 series 데이터로 입력받아 handling가능
- 내장 연산 함수를 사용할 때도 똑같은 효과를 겨둘 수 있음
- mean, std 등 사용가능 (df_info.apply(sum))
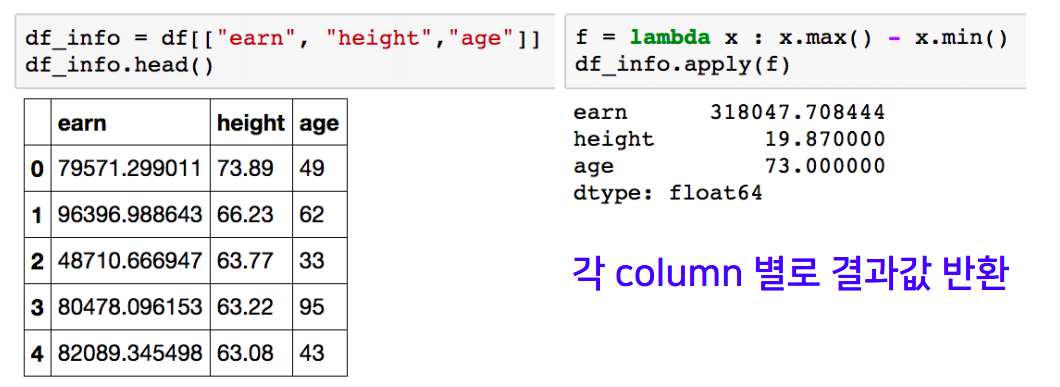
- applymap for dataframe
- series 단위가 아닌 모든 element 단위로 함수를 적용함
- series 단위에 apply를 적용시킬 때와 같은 효과
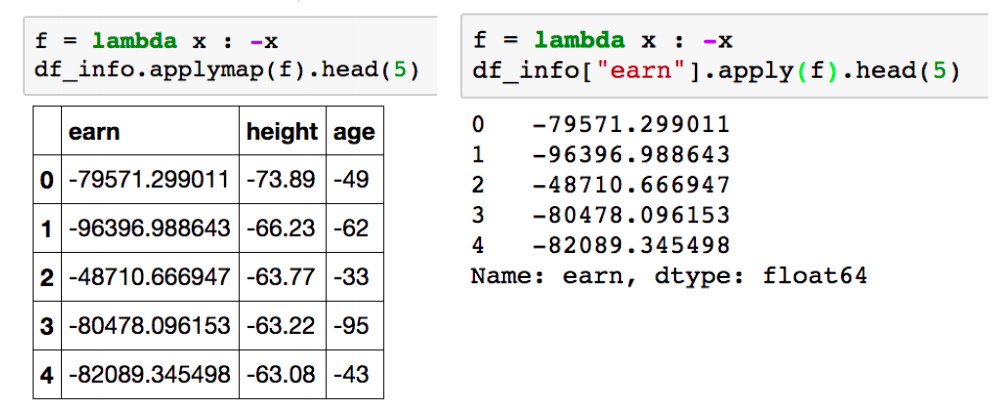
pandas built-in functions
- describe
- Numeric type 데이터의 요약 정보를 보여줌
- unique
- series data 의 유일한 값을 리스트로 반환
- sum
- 기본적인 column 또는 row 값의 연산을 지원
- sub, mean, min, max, count, median, mad, var 등
- isnull
- column 또는 row 값의 NaN(null) 값의 index를 반환
- df.isnull().sum() # Null인 값의 합
- sort_values
- column 값을 기준으로 데이터를 sorting
- correlation & covariance
- 상관계수와 공분산을 구하는 함수
- corr, cov, corrwith
딥러닝 학습방법 이해하기
- 선형모델은 단순한 데이터를 해석할 때는 유용하지만 분류문제나 좀 더 복잡한 패턴의 문제를 풀 때는 예측성공률이 높지 않다
- 이를 개선하기 위한 비선형 모델 인 신경망 을 소개
- 신경망의 구조와 내부에서 사용되는 softmax, 활성함수, 역전파 알고리즘 에 대해 설명
- 딥러닝은 여러 층의 선형모델과 활성함수로 볼 수 있으며, 이 합성함수의 그래디언트를 계산하기 위해서 연쇄법칙을 적용한 역전파 알고리즘을 사용
Further Question
- 분류 문제에서 softmax 함수가 사용되는 이유가 뭘까요?
- softmax 함수의 결과값을 분류 모델의 학습에 어떤식으로 사용할 수 있을까요?
신경망을 수식으로 분해해보자
- 지난 시간까지 데이터를 선형모델로 해석하는 방법을 배웠다면 이제부턴 비선형모델인 신경망(neural network) 을 배워보자
softmax 연산
- 소프트맥스 함수는 모델의 출력을 확률로 해석 할 수 있게 변환해주는 연산 이다
- 분류 문제 를 풀 때 선형모델과 소프트맥스 함수를 결합하여 예측한다
import numpy as np
def softmax(vec):
denumerator = np.exp(vec - np.max(vec, axis=-1, keepdims=True))
numerator = np.sum(denumerator, axis = -1, keepdims=True)
val = denumerator / numerator
return val
vec = np.array([[1,2,0],[-1,0,1],[-10,0,10]])
softmax(vec)- vec - np.max(vec, axis=-1, keepdims=True) : 소프트맥스의 연산이 지수 함수를 사용하다 보니 너무 큰 벡터가 들어오면 발생할 수 있는 overflow 현상을 방지하기 위함
- 그러나 추론을 할 때는 원-핫(one-hot) 벡터로 최대값을 가진 주소만 1로 출력하는 연산을 사용해서 softmax를 사용하진 않는다
- 학습하는 과정에선 softmax가 필요하지만 추론할땐 one-hot 벡터만 사용
활성함수 (activation function)
- 선형모델로 나온 모델 출력물을 비선형모델로 변환
- 변형을 시킨 벡터를 잠재벡터(hidden vector, neuron) 라고 한다
- 활성함수(activation function)는 R 위에 정의된 비선형(nonlinear) 함수 로서 딥러닝에서 매우 중요한 개념이다
- 활성함수를 쓰지 않으면 딥러닝은 선형모형과 차이가 없다
- 시그모이드(sigmoid) 함수나 tanh 함수는 전통적으로 많이 쓰이던 활성함수지만 딥러닝에선 ReLU 함수를 많이 쓰고 있다
- 실수값을 입력으로 받아서 출력을 다시 실수값으로 뱉는 비선형함수
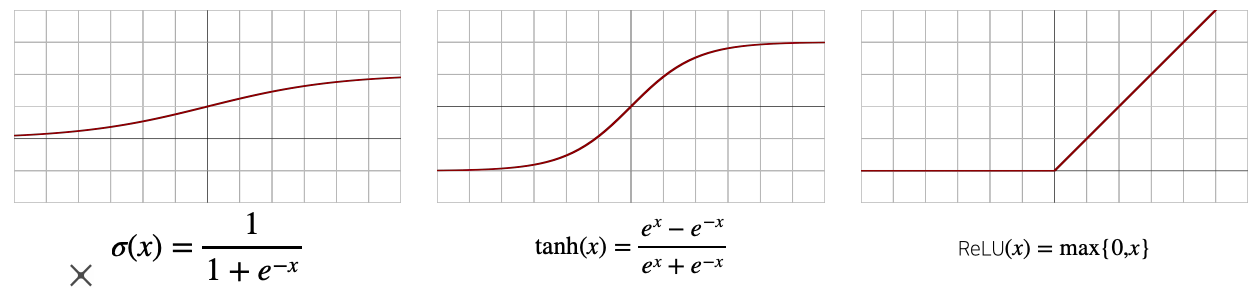
왜 층을 여러개를 쌓나요?
- 이론적으로는 2층 신경망으로도 임의의 연속함수를 근사할 수 있다
- 그러나 층이 깊을수록 목적함수를 근사하는데 필요한 뉴련(노드)의 숫자가 훨씬 빨리 줄어들어 좀 더 효율적으로 학습이 가능 하다
- 층이 깊어질수록 적은 parameter로도 더 복잡한 함수를 표현하는게 가능하다
딥러닝 학습원리: 역전파 알고리즘
- 역전파 알고리즘의 목적 : 각각의 가중치행렬 W에 대해서 손실함수에 대한 미분을 계산할때 역전파 알고리즘을 사용
- 딥러닝은 역전파(backpropagation) 알고리즘 을 이용해서 각 층에 사용된 패러미터 {W(가중치), b(절편)}을 학습한다
- 각 층 패러미터의 그래디언트 벡터를 윗층부터 역순으로 계산하게 된다
역전파 알고리즘 원리 이해하기
-
역전파 알고리즘은 합성함수 미분법인 연쇄법칙(chain-rule) 기반 자동미분(auto-differentiation) 을 사용한다
-
연쇄법칙 예시

예제: 2층 신경망
- 2층 신경망의 역전파 알고리즘 = ?
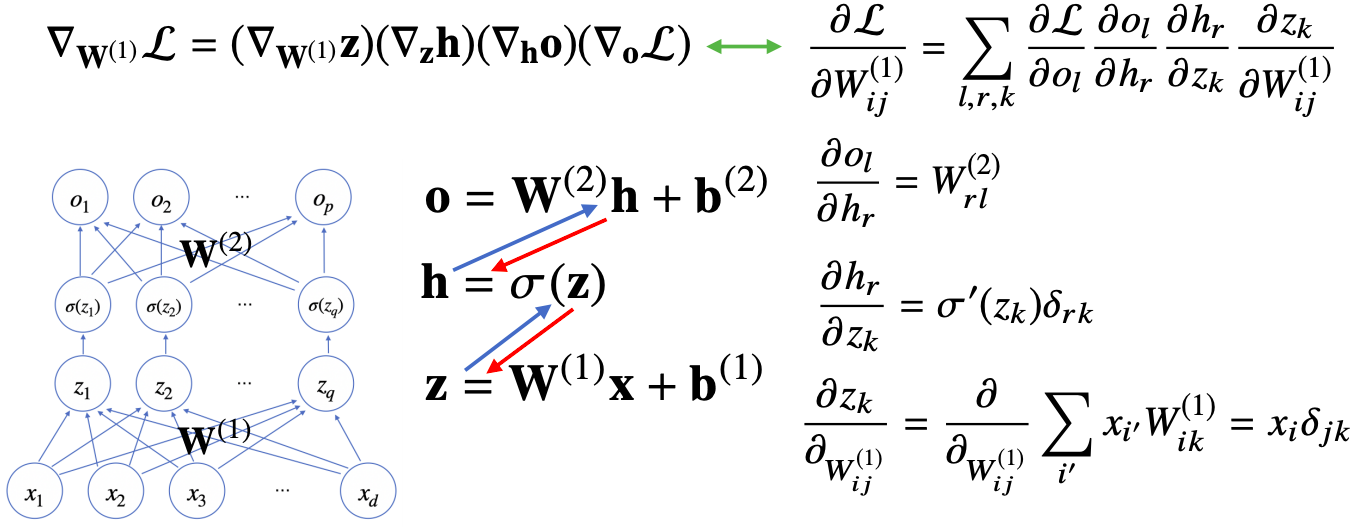

아기개발자