- 단순히 픽셀 마다의 클래스를 분류하는 semantic segmentation은 동일한 클래스에 속하는 개별 물체를 구분하지 못한다
- 이와 달리 instance segmentation은 영상 내에 동일한 물체가 여러 개 존재하는 경우에 각각의 물체를 구분하며 동시에 픽셀 단위의 mask도 예측하는 방법이다
- 그리고 semantic segmentation과 instance segmentation을 결합하여 더욱 복잡한 task인 panoptic segmentation을 소개한다
- 또 다른 물체를 인식하는 방법에는 각 물체를 대표하는 점들을 예측하는 것이 있다
- 이러한 task를 landmark localization이라고 하며 사람의 동작을 인식하는 human pose estimation에 주로 사용되고 있다
- Landmark localization을 대표하는 모델인 hourglass를 위주로 해당 task를 소개한다
Further Questions
- Mask R-CNN과 Faster R-CNN은 어떤 차이점이 있을까요? (ex. 풀고자 하는 task, 네트워크 구성 등)
- Faster R-CNN의 RoI pooling을 개선하여 RoI align을 적용함과 동시에 mask branch를 추가하여 instance segmentation task를 풀고자 하는 모델이 Mask R-CNN입니다. 결국 두 모델의 큰 차이점은 RoI align과 mask branch에 있습니다.
- Panoptic segmentation과 instance segmentation은 어떤 차이점이 있을까요?
- Instance segmentation은 object detection과 같이 개별 물체를 인식함과 동시에 해당 물체에 대한 segmentation까지 풀고자 하는 task입니다. Panoptic segmentation은 이러한 instance segmentation을 semantic segmentation과 결합하여 thing과 stuff를 모두 구분하고자 한 task입니다.
- Landmark localization은 human pose estimation 이외의 어떤 도메인에 적용될 수 있을까요?
- Landmark localization은 RoI extraction, face alignment 등 굉장히 다양한 분야에 적용될 수 있는 task입니다.
Instance segmentation
What is instance segmentation
- 같은 물체 클래스라도 개체 즉, instance가 다르면 구분이 가능한지에 대한 여부이다
- instance segmentation은 같은 물체 클래스를 따로따로 분류한다
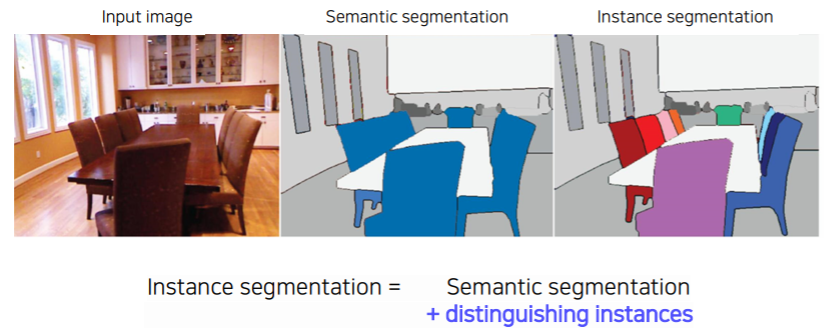
Instance segmenters
-
Mask R-CNN
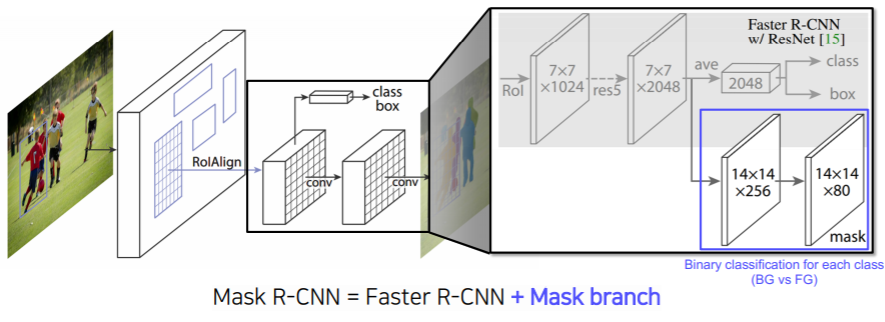
- 기존에 배웠던 Faster R-CNN과 거의 동일한 구조를 가지고 있다
- faster R-CNN RPN 에서 결과로 나온 bounded box proposal을 이용해서 RoI pooling 이라는 방법을 사용했다
- 이 기존 RoI pooling은 정수 좌표밖에 지원하지 않았다
- Mask R-CNN 에서는 RoIAlign 이라는 새로운 pooling layer을 제안했다
- interpolation을 통해서 소수점 픽셀 레벨의 풀링을 지원한다
- 그러므로써 좀 더 정교한 feature를 뽑을 수 있게 되어 뒷단의 성능 증가로 이어지게 된다

-
기존의 faster R-CNN 에서는 pooling 된 feature 위에 올라가있던 classificiation 과 box regression head 가 두개 있다
-
Mask R-CNN 은 기존의 head 옆에 mask branch 하나가 더 있다
- upsampling을 통해서 각 클래스별로 binary mask를 예측하도록 하는 구조를 가지고 있다
- semantic segmentation map과 동일하다
- 하나의 bounding box에 대해서 일괄적으로 모든 클래스에 대한 마스크를 일단 생성한다
- 그 다음에 classification head 에서 클래스를 예측하는 결과를 이용해서 어떤 마스크를 선택을할지 참조 한다
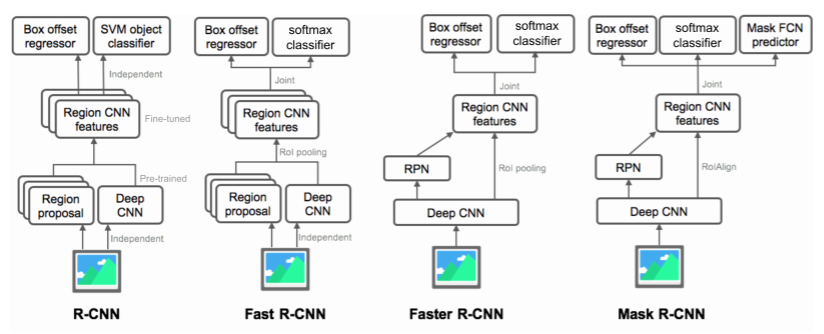
summary of the R-CNN family
YOLACT (You Only Look At CoefficienTs)
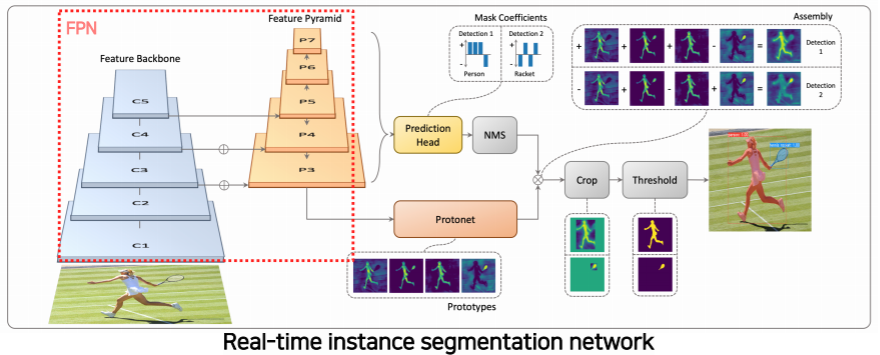
- single-stage network
- 기본 backbone 구조는 feature pyramid 구조를 사용한다
- 고해상도 feature map을 가지고 사용할 수 있다
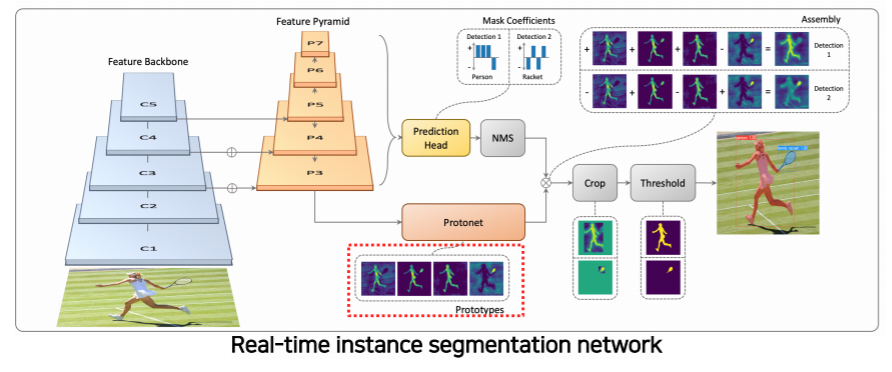
- 가장 큰 특징은 마스크의 프로토타입을 추출해서 사용한다
- 마스크는 아니지만 추후에 마스크로 합성될 수 있는 기본적인 여러 물체의 soft segmentation component 들을 생성한다
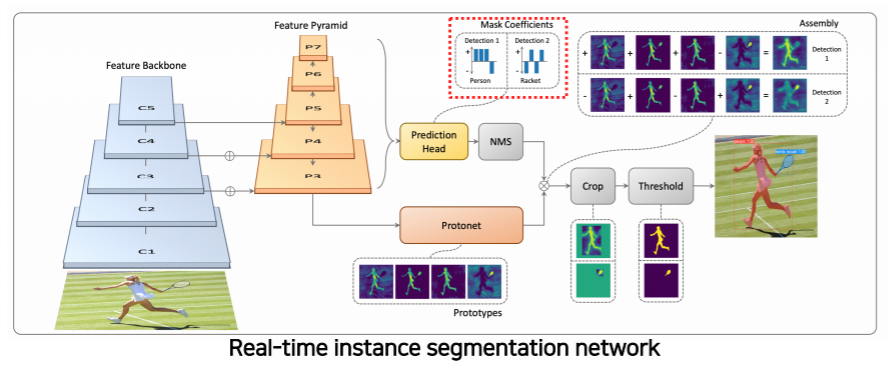
- prediction head 에서 각 detection에 대해서 프로토타입들을 잘 합성하기 위한 coefficient 들을 출력한다
- 이 coefficient과 프로토타입을 선형 결합을 해주므로써 각 detection에 적합한 mask response map을 생성해준다
- 위 예시에서는 detection 1 에 해당하는 경우에는 사람이 dominant한 경우이고
- detection 2 에서는 racket이 dominant 한 경우다
- 마스크를 효율적으로 생성하기 위해서 프로토타입 갯수를 object(class) 갯수하고 상관없이 적당하게 작게 설정하는 대신에 그것에 선형 결합으로 다양한 마스크를 생성하는것이 핵심이다
YolactEdge (2020)
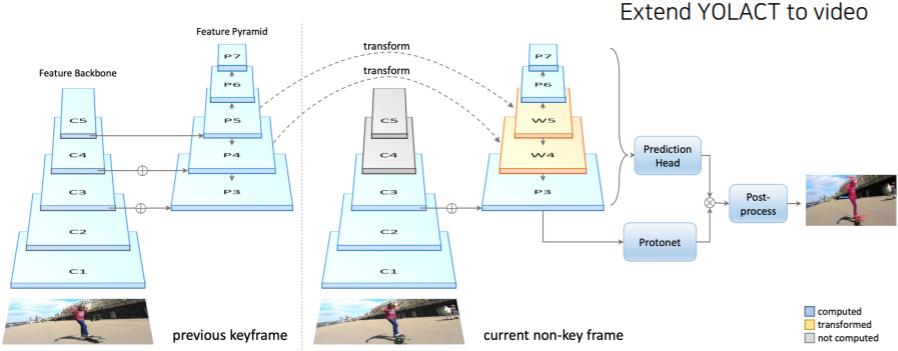
- 이전 frame 중에서 key frame에 해당하는 frame의 feature를 다음 frame의 전달을 해서 특징 map의 계산량을 획기적으로 줄인다
- feature를 전달해서 속도적인 측면에서는 개선을 했지만 실제로 비디오에 따라서 독립적으로 processing이 되는 구조이기 때문에 아직까지는 mask의 한계점들이 존재한다
Panoptic segmentation
What is panoptic segmentation
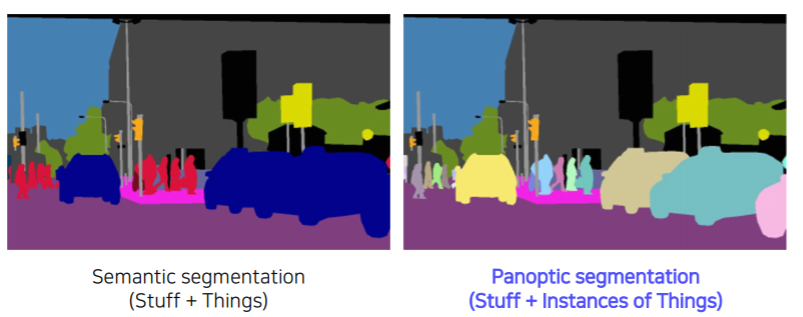
- 기존의 instance segmentation은 배경에는 관심이 없고 그저 움직이는 작은 물체들에 대해서 segmentation을 수행했다
- panoptic segmentation은 배경정보 뿐만 아니라 관심을 가질만한 물체들의 instance 까지도 구분해서 segmentation을 수행한다
UPSNet
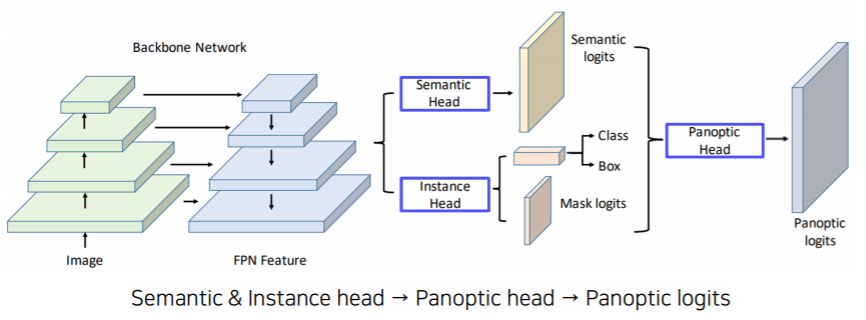
- FPN 구조를 사용하여 고해상도의 feature map을 뽑는다
- head branches
- semantic head : fully convolution 구조로 semantic map을 예측한다
- instance head : 물체의 detection과 box regression 그리고 마스크의 로짓을 추출하는 task
- panoptic head : 뒷단에 개별적인 head 들의 결과들을 융합해 최종적으로 하나의 segmentation map을 만든다
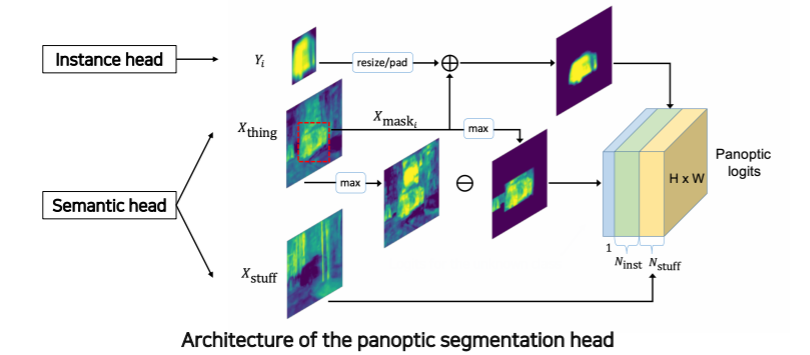
- instance head의 output과 semantic head의 output으로 부터 panoptic head가지 자세하게 살펴보자
- 각 head 에서 나온 결과
- instance 에 해당하는 mask
- 각 물체들과 배경을 예측하는 mask
- 배경을 나타내는 mask response는 최종 출력으로 바로 들어간다
- 각 instance 들을 bounding box 가 아닌 전체 영상에 해당하는 위치에 다시 넣으면서 보강하기 위해서 semantic head의 물체 부분을 masking을 해서 그 response를 instance response 와 같이 더해줘서 최종 출력에 넣어준다
- instance 와 배경에 관련된 물체 이외에 소속되지 않는 unknown class 의 물체들을 고려하기 위해 물체의 semantic mask map에 instance 로 사용된 부분들을 제외해서 나머지 beta 적인 부분들을 unknown 클래스로 합쳐서 하나의 채널로 추가를 하게 된다
VPSNet
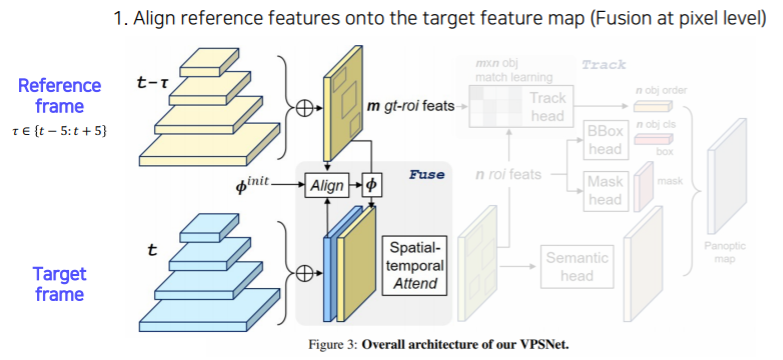
- 두 시간차를 가지는 영상사이에 motion map을 사용해서 각 프레임에서 나오는 feature map을 motion에 따라서 warping을 해준다
- motion map : 두개의 영상이 있으면 한 영상에서의 포인트가 다음 영상에 어디로 가는지 모든 픽셀에 대한 대응점들을 가지고 있는 motion을 나타낸 map이다
- 이걸 활용해서 이 feature를 마치 에서 뽑힌 feature 이지만 현재 target frame 인 에서 찍은것과 마찬가지로 이 feature들을 하나씩 motion vector 에 따라서 옮겨준다
- 그 다음에 원래 각 frame 에서 찍혔던 feature와 warping 된 feature 두개를 합쳐서 사용한다
- 이렇게 함으로써 현재 프레임에서 추출된 feature 만으로 대응하지 못하거나 보이지 않게 가려졌던 부분들도 이전 프레임에서 빌려온 특징들 덕분에 더 높은 detection 성공률이 얻어진다
- 여러 프레임의 feature를 합쳐서 사용함으로써 시간 연속적으로 smooth 한 segmentation이 될 확률도 높아진다
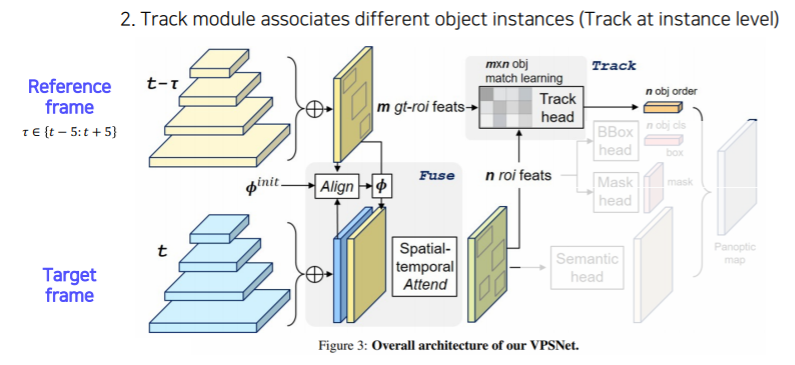
- 그 다음으로는 VPN을 통해서 RoI 들의 feature 를 추출해서 tracking head를 통해서 기존 RoI들과 현재 RoI들이 어떻게 서로 연관 되어있는지, 이전에 몇번 id를 가졌던 물체 였는지를 찾아서 연관성을 만든다
- 이렇게 함으로써 같은 물체는 같은 id 를 가질 수 있도록 시간에 따라서 tracking을 하게끔 만들어 준다
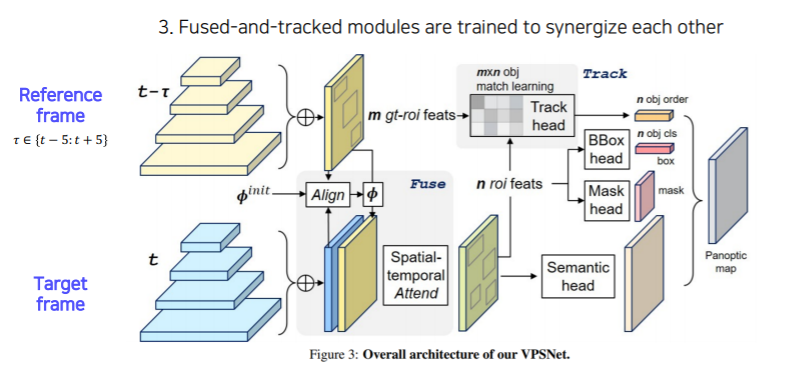
- 나머지는 UPSNet 과 동일하다
- Bounded box head, Mask head, Semantic head 각각의 head에서 나온 결과들을 하나의 Panoptic segmentation map 으로 합쳐준다
- 지금까지 instance segmentation, panoptic segmentation 을 살펴봤다
- 지금부터는 segmentation과 비슷한 각 픽셀별 classification을 하지만 또 다른 중요한 task인 landmark localization 이라는 새로운 task에 대해서 살펴보자
Landmark localization
What is landmark localization?
- Landmark localization (= keypoint estimation) : Predicting the coordinates of keypoints
- 주로 많이 사용되는 응용은 얼굴이나 사람의 포즈를 추정하고 tracking하는데에 많이 사용된다
- 얼굴이나 사람의 몸통등 특정 물체에 대해서 중요하다고 생각하는 특징 부분들을(landmark) 정의하고 그것들을 추정하고 추적하는 것을 landmark localization task라 한다
- 여기서 landmark는 미리 정의를 해놓은 특징들이다

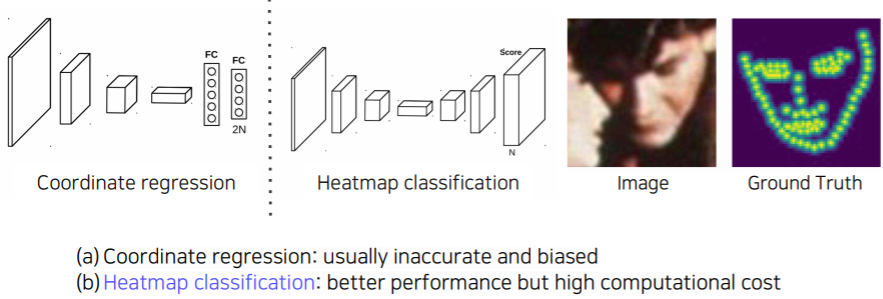
Coordinate regression vs. heatmap classification
-
coordinate regression
- key point 를 찾기 위해서 쉽게 생각할 수 있는 방법은 이전에 배웠던 box regression 처럼 각 포인트에 위치를 바로 예측하는 방식이 있다
- 하지만 이 방식들은 부정확하고 종종 일반화에 문제가 있다
- 따라서 대안으로 heatmap classification 이 제안됬다
-
heatmap classification
- semantic segmentation 처럼 한 채널들이 각각의 key point를 담당하게 되고
- 각 key point 마다 하나의 클래스로 생각해서 그 key point가 발생할 확률 map을 각 픽셀별로 classification 하는 방법으로 대신 해결
- 성능이 훨씬 좋아지긴 하나 모든 픽셀에 대해서 판별을 해야하기 때문에 계산량이 많다는 단점이 존재한다
-
landmark location to Gaussian heatmap
- heatmap 표현은 각 위치마다 confidence가 나오는 형태의 표현
- 위치가 label로 주어졌을때 heatmap label로 변환을 해야한다
- location에서 부터 heatmap으로 어떻게 변환할 것인지에 대해서 살펴보자
# generate gaussian
size = 6 * sigma + 1 # 임의로 영상크기 사이즈를 만든다 (보통 출력 해상도의 크기를 사용)
# 출력 영상의 모든 픽셀의 좌표 (모든 점들의 좌표) 값들을 나열 하기 위해서 x,y 를 미리 생성
x = np.arange(0, size, 1, float)
y = x[:, np.newaxis]
# 임의로 x0, y0 를 센터 포인트에 대응하게끔 만들어 주는데
# 정사각형 이기 때문에 거기서 중간 포인트를 평균 값으로
# landmark 에 location으로 가정하기 위해서 간단하게 예제를 만든다
x0 = y0 = size // 2
# the gaussian is not normalized, we want the center value to equal 1
#
if type == 'Gaussian':
g = np.exp(- ((x - x0) ** 2 + ((y - y0)) ** 2) / (2 * sigma ** 2))
elif type == 'Cauchy':
g = sigma / (((x - x0) ** 2 + (y - y0) ** 2 + sigma ** 2) ** 1.5)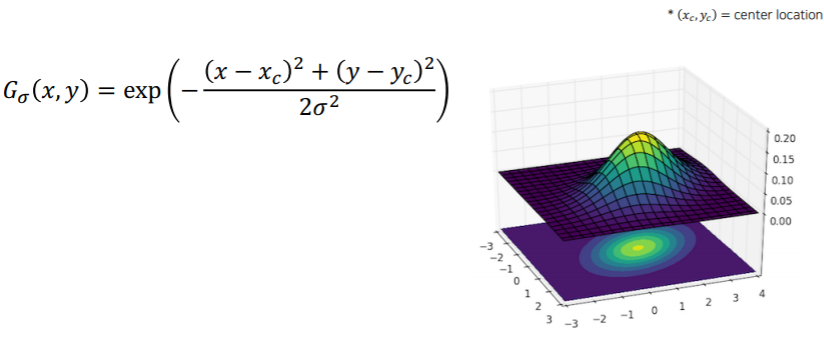
- label 로 주어진 가 gaussian의 평균을 나타낸다 라고 하고 그 위치 근처에 gaussian 분포를 씌운다
- then, how would you convert a Gaussian heatmap to a landmark location? (think about it)
Hourglass network
- Stacked hourglass modules allow for repeated bottom-up and top-down inference that refines the output of the previous hourglass module
- 이렇게 모델의 구조를 설계한 이유는 영상 전체를 작게 만들어서 receptive field를 키우고 이것을 기반으로 landmark를 찾는다
- receptive field 크게 가져가서 큰 영역을 보면서도 skip connection이 있어서 low level feature를 참고해서 정확한 위치를 특정하게끔 유도를 했다
- 이 과정을 여러번 거쳐서 점점 더 큰 그림과 디테일을 같이 구체화해 나가면서 결과를 개선해 나간다
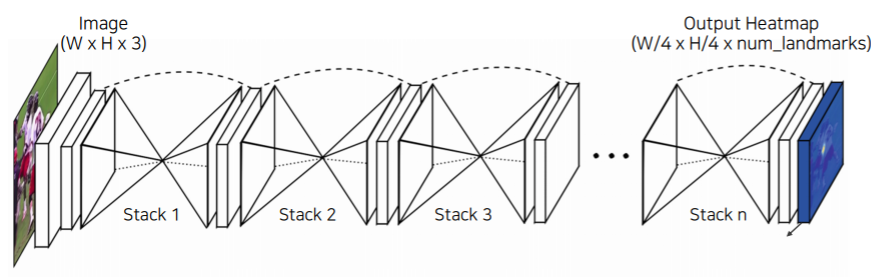
- 아래는 hourglass 부분을 확대해서 보면
- UNet하고 비슷한 구조다
- UNet과 다른점은 UNet은 concatenation 이고 여기서는 더하기 이다
- 따라서 dimension 이 UNet 처럼 늘지 않는다
- 대신에 skip 할때 또 다른 convolution layer를 통과해서 전달이 되게 된다
- hourglass 모델은 FPN에 조금더 가까운 구조이다
- 왜냐하면 더하기를 하고 convolution을 거치기 때문이다
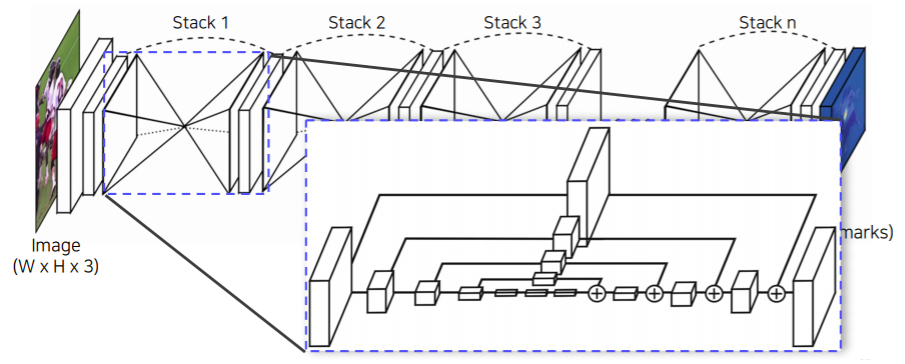
- 왜냐하면 더하기를 하고 convolution을 거치기 때문이다
- 지금까지는 몇몇개의 중요한 sparse 한 landmark 만 찾는 방법들을 알아봤다
- 이번에는 신체 전체에 대해서 dense한 landmark를 찾는 방법을 살펴보자
Extensions
-
DensePose
- 신체의 모든 부위에 landmark의 위치를 알게되면 3D 를 알게 되는것과 마찬가지다

- 신체의 모든 부위에 landmark의 위치를 알게되면 3D 를 알게 되는것과 마찬가지다
-
UV map is a flattened representation of 3D geometry
- UV map은 표준 3D 모델에 각 V 를 2D 로 펼쳐서 이미지 형태로 만들어 놓은 좌표 표기법이다
- UV map에서의 한점은 3D mash 모델상의 한점과 1 대 1로 매치가 된다
-
Also, UV map is invariant to motion (i.e., canonical coordinate)
- 3D mash 가 움직여도 이 id는 보존이(tracking) 된다
- 즉, UV map 과 3D mesh 관계가 변하지 않는다
- UV map 은 고정된 형태의 지도인데 특정 점의 위치를 알고 있으면 3D 상에서 어디에 위치하는지 계속알 수 있다
-
따라서 UV map의 좌표를 바로 출력하는 DensePose 는 3D mesh를 바로 출력하는 것과 마찬가지다
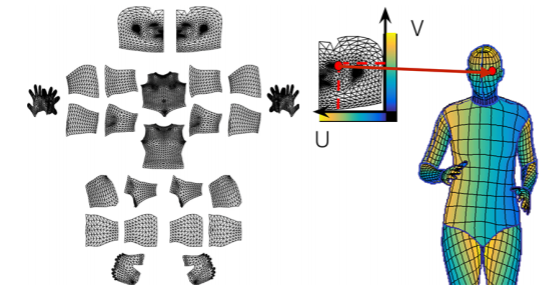
-
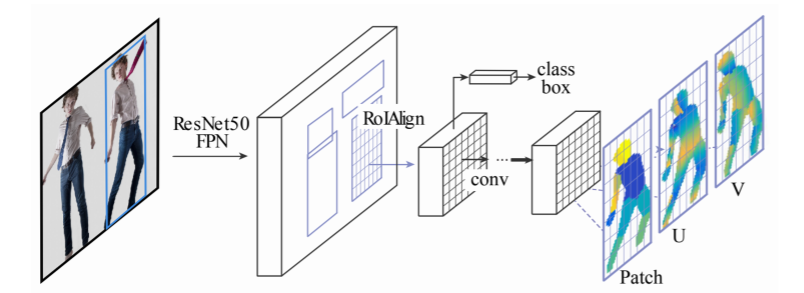
DensePose R-CNN = Faster R-CNN + 3D surface regression branch
- patch : 각 body part의 segmentation map
- 입력 데이터와 출력간의 관계를 잘 설계함으로써 2D 구조의 CNN으로 3D를 잘 예측하는 스마트한 방법을 설계했다
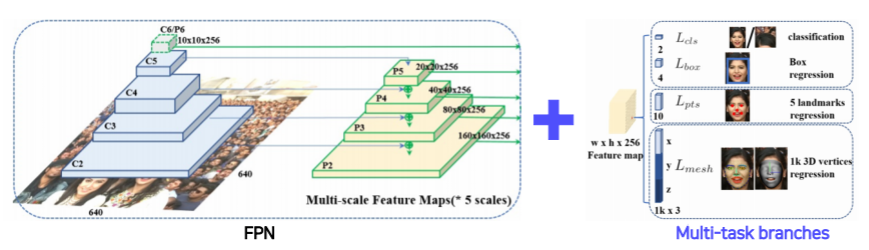
Extensions - RetinaFace
- RetinaFace - FPN + Multi-task branches (classification, bounding box, 5 point regression(5개의 landmark를 detect), mesh regression(3D face mesh를 출력하는 task))
- 다양한 task의 branch 를 사용해서 다양한 task를 한번에 풀도록 만들었다
- 이런 Multi-task 방법으로 모델을 만들게 되면 학습을 할때 장점이 생긴다
- 각 task 마다 공통적으로 얼굴에 대한 조금씩 다른 task를 통해서 오는 공통된 정보 이외에 조금식 다른 정보를 backbone network가 학습하기 때문에 훨씬 강하게 학습되는 효과가 있다
- 왜냐하면 gradient가 여러군데에서 오면 이 gradient 들이 공통되는 정보도 있고 조금 다른 정보들도 있는데 한번에 업데이트 될때 데이터를 더 많이 본 효과도 있다
- 따라서 사용한 데이터양 대비해서 성능 향상 폭이 큰 경우가 많이 존재한다
Extensions pattern
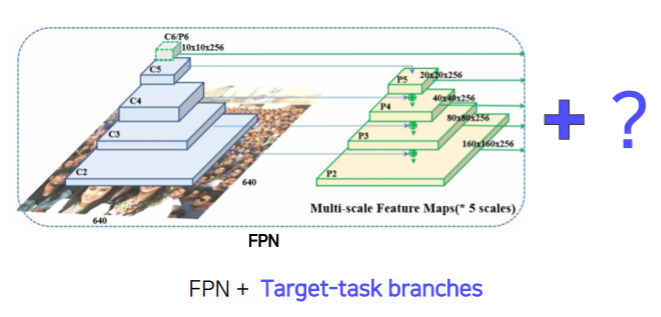
- 이렇게 backbone network 위에 본인이 관심있는 target task에 해당하는 head만 만들어주면 다양한 응용에 적용이 가능하다
- 이게 현재 computer vision에 큰 디자인 패턴에 흐름이다
Detecting objects as keypoints
- 마지막으로는 object detection때 bounding box가 아닌 key point 형태로 detection을 하는 방법들을 살펴보자
CornerNet & CenterNet
-
CornerNet
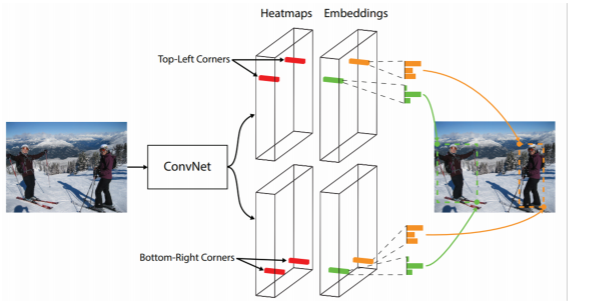
- Bounding box = {Top-left, Bottom-right} corners
- Bounding box 가 왼쪽 위에 점 그리고 오른쪽 아래 점 이렇게 두 개의 corner point만 있으면 bounding box 하나가 결정된다
- backbone network에서 나온 feature map에 heatmap 표현을 통한 두 점을 각각 검출하도록 한다
- embedding : 각 포인트가 가지는 정보를 표현하는 head를 하나 더 둔다 그 다음에 학습할때 두 코너에서 나오는 embedding 포인트는 만약 서로 같은 object 에서 나왔다면 같아야 한다 라는 조건을 걸어줘서 학습한다
- 입력으로 영상을 주면 heatmap head에서는 corner point만 잔뜩 추력하고 그다음 embedding matching을 통해서 bounded box로 추출이 가능하도록 만들어 준다
- Bounding box = {Top-left, Bottom-right} corners
-
성능보다는 속도를 강조한 구조이다
-
CenterNet(1)
- Bounding box = {top-left, bottom-right, center} points
- 왼쪽 위, 오른쪽 아래 뿐만 아니라 센터 포인트의 역할이 성능을 높여준다

-
CenterNet(2)
- Bounding box = {Width, Height, Center} points
- 센터 포인트에서 코너 두 개를 추가를 검출하면 bounded box에 대해서 표현이 redundant 하다
- 왜냐하면 이미 왼쪽 위하고 오랜쪽 아래만 가지고도 잘 표현되는 bounded box를 가운데 점을 하나 더 추가한 거기 때문이다
- 따라서 bounded box 하나를 특정하기에 적합한 최소의 정보는 센터, 폭, 높이 정보만 있으면 bounded box가 유니크 하게 결정이 될 수 있다

-
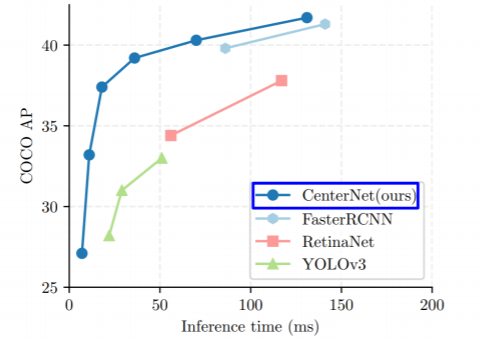
CenterNet(2) 가 다른 모델에 비해 속도가 가장 빠르다
-
또한 성능도 뛰어나다
Key takeaways
- task 들이 대부분 비슷한 디자인 패턴을 갖는다
- 따라서 다양한 task에 대해서 맨땅에 헤딩해서 새로운 구조를 도전하기 보다는
- 디자인 패턴을 따라서 설계를 하면 좀 더 쉽다
- 데이터 또는 출력을 변경하는 것으로 속도나 성능 향상을 크게 가져올 수 있다
- 데이터 표현이 중요하다

아기개발자
좋은 글 정말 잘 읽고 갑니다!
Image Segmentation 분야에 대해서 전혀 모르는데,
친절한 설명과 깔끔한 정리 덕분에 편하게 이해했습니다.
감사합니다!