- PyTorch에서 제공하는 autograd 패키지에 대해서 공부한다
- autograd 패키지는 PyTorch Tensor의 모든 연산에 대해 자동 미분을 제공한다
- 노트에서 소개한 개념들을 실제 구현할 때 필요한
(1) gradient들이 computational graph를 통해 input으로 전달하는 방법과
(2) user-defined function을 hook하는 방법을 중점적으로 다룬다
- saliency map을 구하기 위해서 필요한 기본적인 구현 디테일에 대해서 살펴보자
- saliency map을 구하기 위해선 class score에서 부터 gradient를 구해서 input 도메인에 gradient 를 구하는 것이 최종적인 목표이다
- 이렇게 backpropagate 된 gradient들을 accumulate 한다든지 아니면 gradient 자체를 visualize 해서 saliency map을 얻는다
Exercise. Autograd
- gradient를 구하는 방법은 Autograd를 활용해야 한다
- Autograd
- Automatic gradient calculating API
- Automatic differentiation is a building black of every DL library (forward & backward passes)
- 대부분의 딥러닝 라이브러리의 고유한 기능을 한다
- 기본적으로 딥러닝 라이브러리들이 많은 convolution operation이나 딥러닝에 최적화된 operation 을 제공하지만 기본적으로는 행렬 연산을 하는 라이브러리다
- 기존에 행렬 연산 라이브러리들이 많았지만 그것들과 딥러닝 라이브러리의 가장 큰 특징이 autograd이다
- autograd는 forward pass 와 backward pass가 가능하게 만든다
- 우리가 무언가 하나의 값을 계산하기 위해서 다양한 process를 거쳐서 계산을 하게되는데
- 이때 많은 변수들을 사용하는데
- 이 연산을 반대로 gradient를 계산할 수 있도록 쉽게 만들어 준다
- computational graph 라는 편리한 구조를 사용해서 automatic differentiation을 편하게 구현할 수 있도록 만들었다
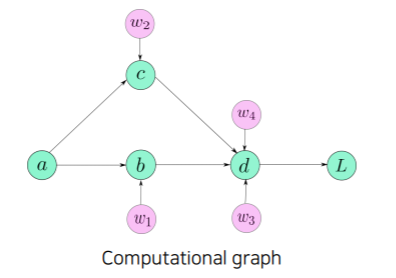
- computational graph가 의미하는 것은 위의 그림을 예시로 들면 이 계산되기 까지 어떤 history(어떤 연산들, 연결성을 가지고 계산이 되었나)를 가지고 있었는지 계보를 기록하는 것이다
- 이런 기록들을 저장하는 이유는 backprogation할때 에서부터 에 대한 gradient를 구하고 싶다 라고 하면 에서 부터 gradient가 전파되서 흐르는 형태로 backprogation을 계산할 수 있다
- backward를 구현하기 쉽게만드는 computational graph를 항상 유지하고 있다
Autograd - Tutorial
- Automatically computing gradients of y with respect to x
- x 에 대한 y gradient를 계산하는 예제
x = torch.randn(2, requires_grad = True) # x는 2dimension의 변수로 선언
y = x * 3 # y함수를 x에 대한 연산으로 정의
gradients = torch.tensor([100, 0.1], dtype = torch.float)
# y에 대한 backward를 콜하게 되면 y가 여태껏 계산되면서 저장해온 computation graph 즉, history 를 가지고 거꾸로 backpropagation을 하면서 나가는 것이다
# delta y/ delta ?, ? = y가 계산될때 사용했던 모든 변수들을 다 미리 계산해 놓을 수 있다
y.backward(gradients)
print(x.grad) # x.grad를 통해 delta y/ delta x 를 출력해준다
# y 함수를 보면 3이 나와야한다고 생각해야 하지만 아래와 같이 나온다
# 그 이유는 위에 y.backward() 함수 내에서 gradients라는 argument가 들어갔기 때문이다
# backward 안에 어떤 argument가 들어가게 되면 delta y/ delta ? 를 계산하는 것이 아니라
# argument가 곱해진 delta y/ delta ? 를 계산해준다
# tensor([300.0000, 0.3000]) - backward 함수의 API가 이런걸 계산하게끔 설계가 되어있다
- 위와 같이 설계한 이유는
- 예: , 라는 함수가 에 대한 함수인데 어떤 스칼라 값 가 나왔다
- 이 스칼라값에 대해서 나중에 backpropagation하기 위해서 미분을 할것이다
- 이때 우리는 까지 얻을 수 있을것이다
- 그 다음에 를 보면 이 는 즉, 에 대한 함수라고 해보자
- 그래서 이 에 대해서도 를 구하려고 했던 것이다
- 그래서 예를들어서 그 더 윗단에 어떤 함수를 통해서 가 이용이 됬고 결국에는 위쪽에서 backpropagation을 통해서 gradient가 넘어오면 에 대한 이 와 결합이 되어서 chain rule을 완성시키기 위해서 위와 같은 backward API(y.backward(gradients))를 만든것이다
- 즉, 이파트가 사실은 그 윗단의 gradient라고 치고 y.backward() 에 들어가는 것이다
- 그렇다면 에 대한 backward인 이게 계산이 되는데 이걸 argument로 넣어주면서 두 개가 곱해지게 되는것이다
- 그러면 곱하기 곱하기 를 통해 최종적으로 이 gradient가 구해지게 되는것이다
- y.backward(gradients)와 같이 gradients argument에 벡터를 넣어주는 경우는 gradients 파트가 미분 행렬일때만 넣어준다
- 만약 미분 행렬이 아닌 미분 값일때에는 안넣어줘도 된다 default로 1이 들어간다
- 예를 들어서 예제에서 loss.backward() 해줄때 자체가 스칼라 값이기 때문에 1을 넣어주거나 또는 아무것도 넣어주지 않는다
- loss 윗단에서 무언가 계산을 하지 않으니깐 1을 곱해준다
Autograd - Tutorial (requires_grad)
- requires_grad indicates autograd to compute and store gradients
- With requires_grad = False option, RuntimeError occurs when y.backward() is called
- 만약 requires_grad = False로 해서 x 가 gradient를 갖지 못하게 만들면 backward 하게 되면 에러가 난다
- 에러가 나는 이유는 y 를 통해서 backward로 가봤더니 x 에서 사용된 변수가 전부다 gradient를 담을 수 있는 그릇이 없는것이다
- 즉, backward가 불가능한 함수라 에러가 난다
# requires_grad = True 일때 x 가 gradient 를 저장할 수 있는 변수로 선언한다
# 그래야 x.grad를 호출할 수 있다
x = torch.randn(2, requires_grad = True)
y = x * 3
gradients = torch.tensor([100, 0.1], dtype = torch.float)
y.backward(gradients)
print(x.grad) # tensor([300.0000, 0.3000])- 또 다른 주의점은 y에 대해서 backward를 한번 호출하고 또 한번 호출하면 기존에 있었던 미분값하고 두번째 호출했을때 호출한 미분값하고 더해진다(accumulate)
- 두번 호출하게 되면 runtimeerror가 난다
- 에러가 나는 이유는
- backward를 한번 호출하면 그 중간에 계산했었던 computation graph 를 항상 저장하고 있으면 너무 heavy해서 지워버린다
- 그래서 중간의 intermediate resources 즉, 중간 결과들을 전부 다 버린다
- 사실 backpropagation을 하면 중간에 computation graph를 다 날리더라도 맨 마지막에 종말단에 있는 gradient만 확보하면 되기 때문에 retain_graph = False 가 default 로 설정 되어있다
- 그러다 보니깐 backward를 한번 호출하면 computational graph가 날라가 버린다
- 따라서 backward 를 한번 호출하고 두번째 backward를 호출하고 싶다면 retain_graph = True 옵션을 사용해야 한다
- .backward(retain_graph = True) : to indicate not to free intermediate resources
- 따라서 retain_graph를 쓰든 쓰지 않던 backward를 사용하고 zero_gradient를 해주지 않으면 gradient가 계속 accumulate 되는 특성이 있다
gradients = torch.tensor([100, 0.1], dtype = torch.float)
y.backward(gradients, retain_graph = True)
print(x.grad) # tensor([300.0000, 0.3000])
y.backward(gradients)
print(x.grad) # tensor([600.0000, 0.6000]) # gradients are accumulatedAutograd - Tutorial (grad_fn)
- A tensor y is a computed result, so it contains the grad_fn attribute
- referencing function (class) that is called to construct
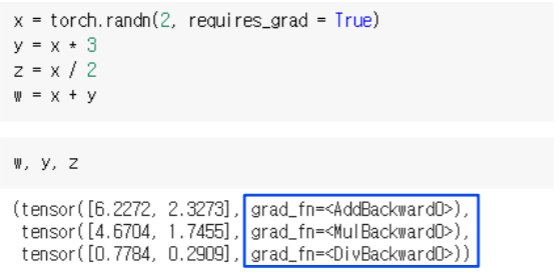
- referencing function (class) that is called to construct
- x로 부터 y, z, w 를 만들어 computational graph을 형성한다
- y, z, w 가 각각 computational graph를 가지고 있다
- 이 computation graph를 어떤식으로 실제로 backpropagation 할때 구현이 되냐를 보게되면
- grad_fn attribute로 구현되어 있다
- 무슨 얘기냐면 w, y, z를 각각 출력해보면 각 w, y, z 값 자체를 출력해주고 두번째에 grad_fn 이라는 또다른 attribute가 있다
- grad_fn attribute에 function 클래스가 등록 되어있다
- 위 예시를 예로 들면 w 바로 직전에 computation graph의 operation은 더하기 이고 이 더하기에 x, y 변수가 걸려있다
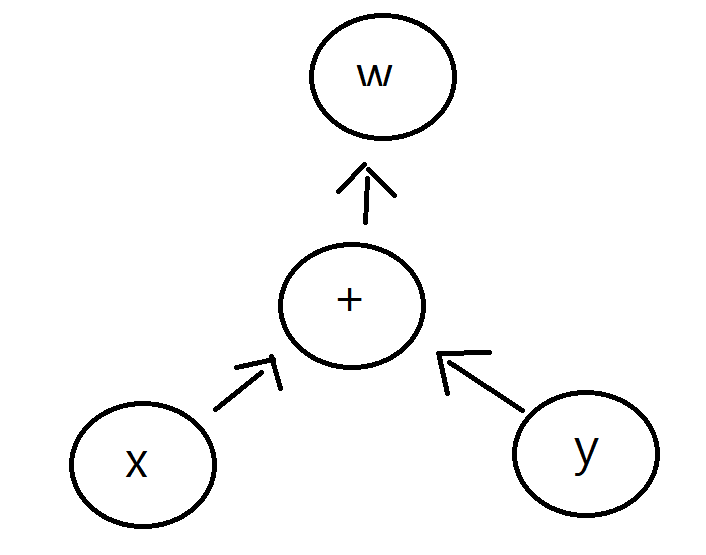
- w의 gradient를 backpropagation할때 gradient function을 보면 더하기를 통해 이루어져 있고 더하기의 backward 가 어떻게 구현이 되어져야 하는지를 function class로써 생성자로 등록되어 있다
- 따라서 backward를 호출하면 AddBackward 가 호출이 되면서 backpropagation이 이루어진다
Class activation mapping (CAM)
-
we want an activation at an intermediate layer (instead of the scores at the last layer)
-
we want to store gradients at an intermediate layer

-
hook: register_forward_hook
- hook은 중간에서 gradient를 얻는 방법이다
- hook을 사용할대 register_forward_hook, register_hook 함수를 알아야한다
- hooking이 의미하는건 어떤 function call을 했을때 두 개의 software component사이에 전달 되는 메세지를 intercept(낚아채는) 하는 의미다

- register_hook이라 하면 backward 가 call 될때 backward 중간에 있는 어떤 정보를 낚아채는 것이다
- 그래서 위와 같이 우리가 gradient backward를 hook하게 되면 gradient를 계산할 때마다 그 gradient를 낚아채올 수 가 있는 function이다
Autograd - Tutorial (hook)
-
hooking을 사용하기 위해서 간단한 3개의 hidden layer를 가지고 있는 simple network를 정의해서 보도록 하자

-
signature of hook function - forward
- hooking을 사용하기 위해서 hook 이라는게 동작할때 어떤걸 수행 해야하는지 signature of hook function을 정의해야한다
- hooking event가 발생했을때 hook function내에 정의된 아래 동작들이 수행되게끔 구현해야한다
- 아래 프로토타입과 맞게끔 설정해줘야한다
- input하고 output을 항상 받는 arguement가 있어야하고
- 또한 이 function은 class의 멤버 함수로 설정했기 때문에 self가 붙는다

-
register hook function
- 다음은 hooking을 어디서 잡아볼까를 생각해야하는데
- hooking을 걸고 싶은 layer에다가 hooking function을 register_forward_hook을 건다
- register_forward_hook을 걸어주므로써 앞으로 forwarding 될때 activation이 계산될때 hooking 이 발생하는 형태이다
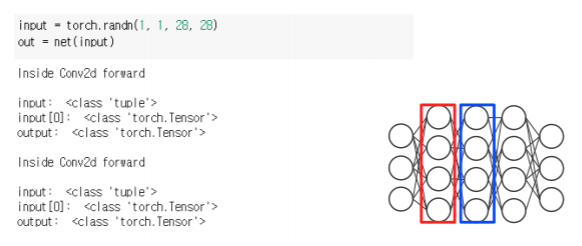
- 아래의 conv1 에 register_forward_hook을 걸었을때 conv1 layer가 계산이 되어서 forward가 될때 그때 hook function를 동작하라고 등록을 하는거다
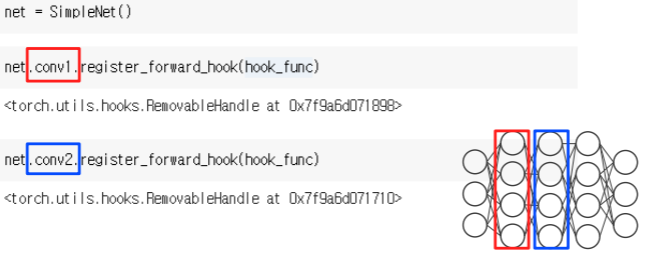
- 그렇다면 이제 forward pass 를 하게 되면서 activation이 계산될때 만들어진 hook_func 이 자동으로 호출된다
- 그래서 아래를 살펴보면 우리가 random input을 만들어주고 network의 입력으로 넣어주면
- conv이 첫번재 동작할때 우리가 hook_func 안에서 정의했던 동작들이 수행된다
-
register_forward_pre_hook
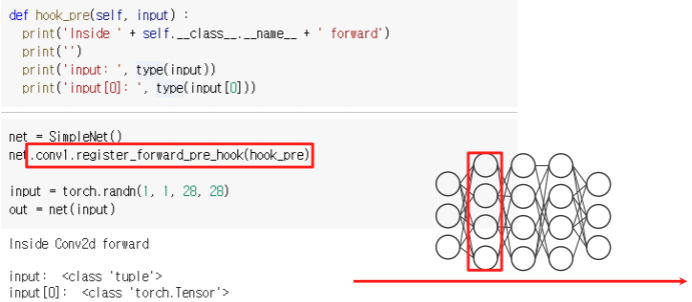
- with register_forward_pre_hook, hook_func gets executed before the forward pass
- hook이 발생하는 시점이 forward pass 하기 바로 직전에 발생한다
- pre_hook 발생하는 event 시점의 호출되는 함수가 argument로 들어간다
-
register_backward_hook
- hook_func gets executed when the gradients with respect to module inputs are computed
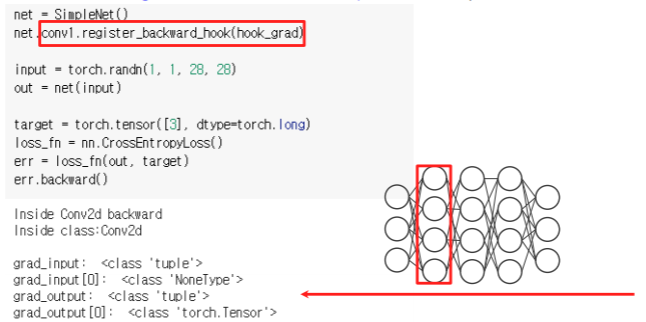
- conv1 layer에다가 backward_hook을 걸어주게 되면 일단 input을 만들어주고 네트워크로 forwarding 해줄때 까지는 hook_func 이 호출되지 않는다
- 뒤쪽에서 에러를 계산한 다음에 backward 함수를 호출하게 되면 backpropagation이 되어 올때 hook이 걸린 layer의 backpropagation이 실행되고 hook_func이 실행된다
- hook_func gets executed when the gradients with respect to module inputs are computed
-
__signature of hook function - backward
- grad_input and grad_output mean the gradients with respect to input and output, respectively
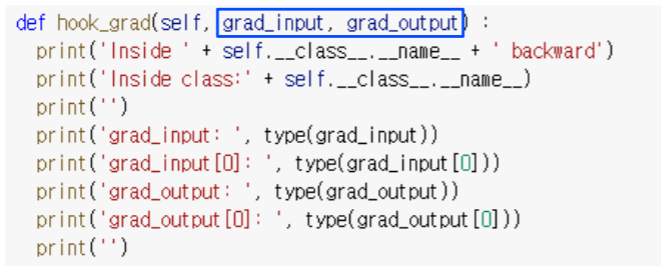
- 주의할점은 argument 자체 (grad_input, grad_output)을 변경하면 안된다
- 대신에 gradient를 바꾸고 싶다하면 선택적으로 return할 수 있다
- 아래 return을 걸어주면서 어떤 gradient가 되었으면 좋겠다라는 새로운 gradient를 계산해서 넣어주면 이 hook을 통과하면서 backpropagation gradient가 넘어오게 되면서 다음으로 넘어갈대 gradient가 변형되서 넘어가게 되서 실제로 backpropagation에 반영이 된다
- grad_input and grad_output mean the gradients with respect to input and output, respectively
Autograd - Tutorial (remove)
- Handle.remove() will remove the hook

- register를 지우는 방법은
- register hook을 호출할때 리턴값(위에선 h로 정의)을 받는데 이것을 handle 이라고 부른다
- 이 handle을 보관하고 있다가 나중에 network를 forward를 통해서 hooking을 다하고 어떤 결과를 다 본다음에 더이상 hooking이 필요없다 라고 하면 h.remove() 를 사용해서 register 된 hook을 지워준다
Autograd - Toy activation example
-
gradCAM을 구현할때 register_forward_hook으로 중간에 activation을 가져오는 방법은 어떻게 구현할 수 있는지 살펴보자
-
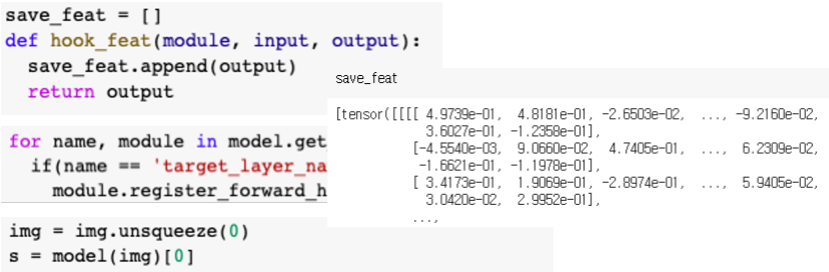
먼저 hook_func을 정의한다
- 이때 작업은 feature가 들어왔을때 그 feature를 저장한다
- 그냥 저장하는 것이 아니라 전역변수로 선언해서 다른데서도 볼 수 있게 만들어준다
- hook_func 이 실행되면 output을 append 해서 save_feat 에 계속 쌓아간다

-
다음으로는 hook_func 을 적절한 layer에 register 해준다
- 먼저 모델에서 그 모델에 각각의 모든 모듈들을 for loop을 통해서 하나하나 방문하면서 만약에 그 모듈의 이름이 우리가 원하는 target layer의 이름과 일치할때 그 모듈에 register를 한다
-
다음에 해야하는 작업은 input이 들어왔을때 forward를 하는것이다
- foward call을 하면서 target으로 지정했던 layer를 지나쳐 갈때 그대 hook_func이 실행되게 되고 save_feat에 output feature가 저장된다

- foward call을 하면서 target으로 지정했던 layer를 지나쳐 갈때 그대 hook_func이 실행되게 되고 save_feat에 output feature가 저장된다
-
check save_feat

아기개발자