Model 1
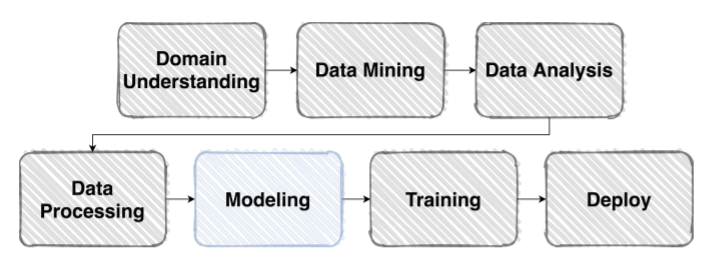
- 이제 본격적으로 모델을 디자인하는 과정이다
- 파이토치라는 프레임워크가 어떤 특징을 가지고 있는지와, 파이토치가 어떻게 모델 그래프(체인)을 구성하게 되고, 파라미터 값을 어떻게 저장하고 있는지, forward라는 함수의 동작 과정에 대해서 약간 디테일 하게 접근한다
Further Reading
Overview
- 이제, 데이터 셋으로 원하는 출력을 만들어 줄 모델을 구성할 차례이다
Model
“In general, a model is an informative representation of an object, person or system”
Design Model with Pytorch
nn.Module
- Pytorch 모델의 모든 레이어는 nn.Module 클래스를 따른다
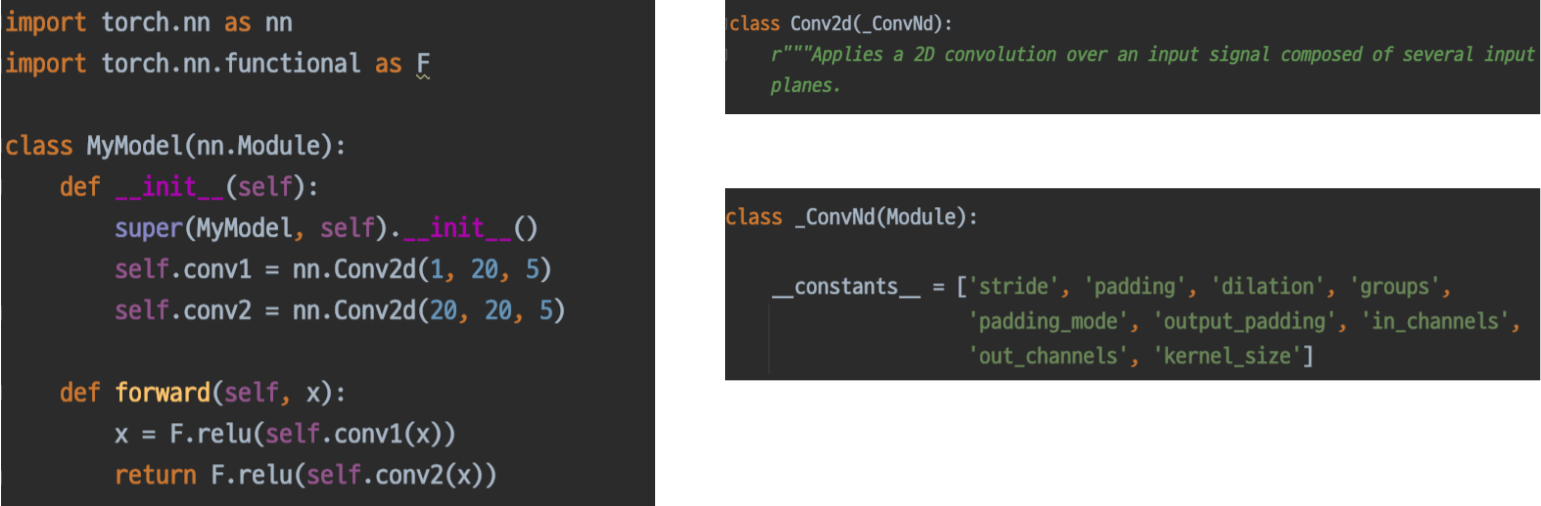
modules
- init에서 정의한 또 다른 nn.Modules
forward
- 이 모델(모듈)이 호출 되었을 때 실행 되는 함수

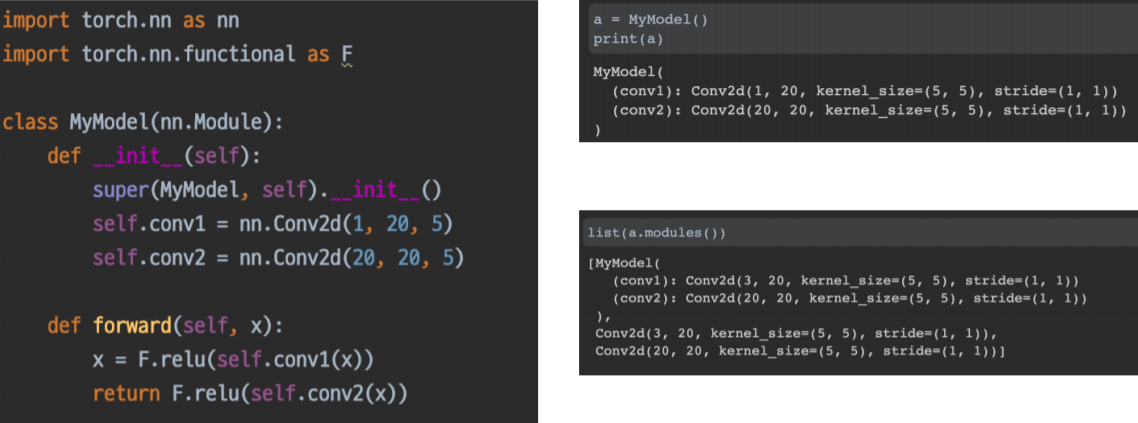
nn.Module Family
- nn.Module을 상속받은 모든 클래스의 공통된 특징
- 모든 nn.Module은 forward() 함수를 가진다
- 내가 정의한 모델의 forward()를 한번만 실행한 것으로 그 모델의 forward에 정의된 모듈 각각의 forward()가 실행된다

- 내가 정의한 모델의 forward()를 한번만 실행한 것으로 그 모델의 forward에 정의된 모듈 각각의 forward()가 실행된다
- 모든 nn.Module은 forward() 함수를 가진다
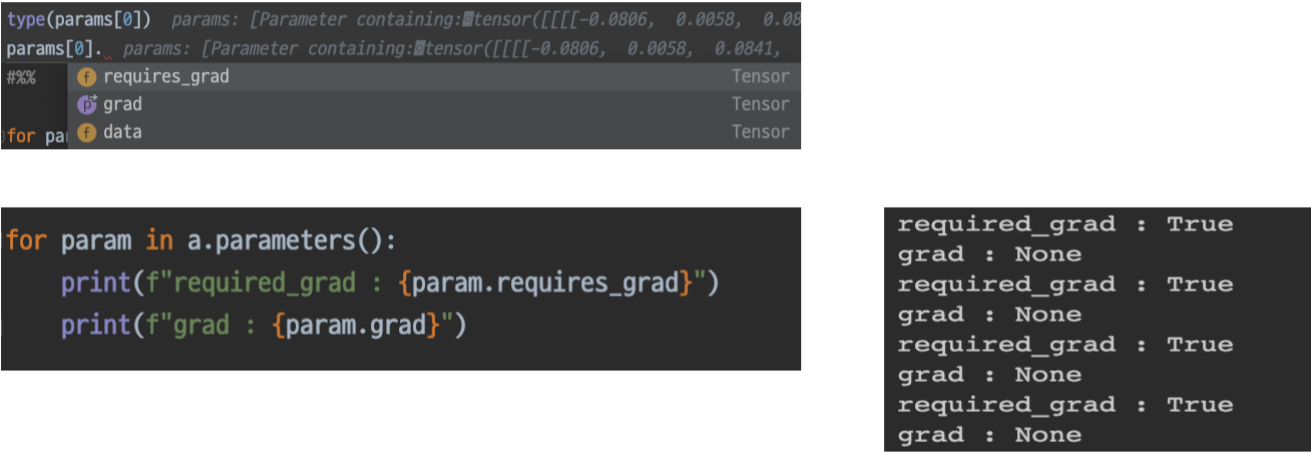
Parameters
-
모델에 정의되어 있는 modules가 가지고 있는 계산에 쓰일 Parameter

-
각 모델 파라미터 들은 data, grad, requires_grad 변수 등을 가지고 있습니다
Pytorch의 Pythonic
- Pythonic하다는 것의 장점
- Python의 Dictionary

- 우리가 이러한 형식과 구조를 미리 알고 있다면 여러가지 응용이 가능할 뿐더러, 발생할 수 있는 에러들도 핸들링 할 수 있다
Model 2
- 일반적으로, 모델을 새로 설계 하는 데는 시간이 걸린다
- 나는 당장 서비스를 해야 하는데, 모델 설계에 시간을 많이 쏟고 있다면 비효율적일 수 있습다
- 따라서, 기존에 검증된 우수한 모델 구조와 미리 학습된 weight를 재사용하는 방법에 대해서 다룬다
- 지금껏 Computer vision 분야에서 훌륭한 모델 아키텍쳐가 나올 수 있게 된 배경과, 그 모델들을 어떻게 우리 태스크로 가져와서 활용할 수 있을지, 활용할 때 주의사항은 없을지 등에 대해서 알아보도록 하자
Further Reading
Pretrained Model
Pretrained Model의 배경
- 모델 일반화를 위해 매번 수 많은 이미지를 학습시키는 것은 까다롭고 비효율적

이미 공개되어 있는 수 많은 Pretrained Model
- 미리 학습된 좋은 성능이 검증되어 있는 모델을 사용하면 시간적으로 매우 효율적
- torchvision 보다 더 다양한 실험은 해본 timm 도 참고 가능

- torchvision 보다 더 다양한 실험은 해본 timm 도 참고 가능
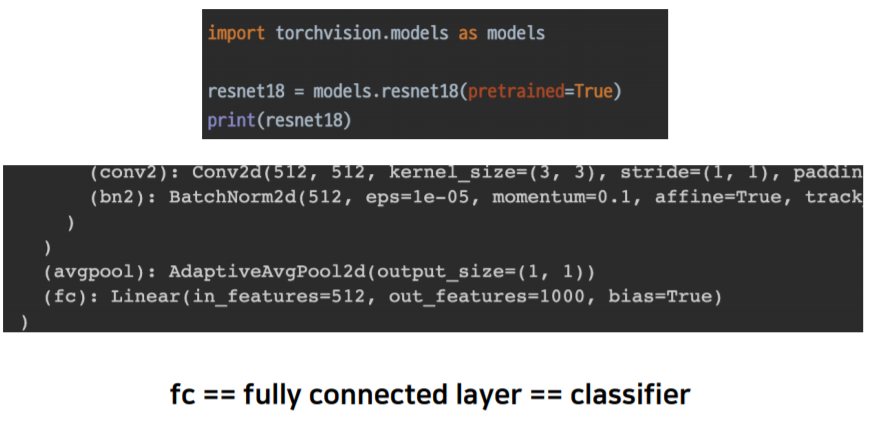
torchvision.models
- 너무나도 손쉽게 모델 구조와 Pretrained Weight를 다운로드 할 수 있다

Transfer Learning
CNNbase모델 구조 (simple)
- Input + CNN Backbone + Classifier → Output

Code Check
- Torchvision model 구조
내 데이터, 모델과의 유사성
- Ex)ImageNet Pretraining

- 내가 설정한 문제와 비교

Case by Case
-
Case 1. 문제를 해결하기 위한 학습 데이터가 충분하다

- 만약 CNN backbone이 사용자가 풀려고 하는 문제와 매우 흡사한 문제라면 CNN backbone을 굳이 trainable 하게 만들 필요가 없다
- 사용자의 task에 맞는 classifier로 변경 후 이 부분만 학습하게 되면 CNN backbone에서 나왔던 feature 를 분류하는 것만 학습이 되는 것이고 이 feature들은 사실은 속성이 같기 때문에 똑같은 feature들이 나올 수 있고 이것들이 classifier가 새로 만들어진다 해도 어느정도 당위성을 가지고 있다라고 볼 수 있다
- 따라서 이 classifier를 충분히 표현할 수 있는 학습 데이터가 충분하고 pre-train 모델과 task similarity 도 같다면 CNN backbone은 유지하고 classifier만 학습하면 된다
- 빠르고 간단 명료한 장점이 있다
- 이런 과정을 feature extraction 이라고 한다
- task similarity 가 완전히 다르더라도 pre-trained 된 모델의 backbone 까지 학습을 하게되면 생각보다 아무것도 없었던 파라미터에서 시작하는것 보다는 수렴속도나 성능이 훨씬 더 좋아진다
- 이런 과정을 fine tuning 이라고 한다
-
Case 2.학습 데이터가 충분하지 않은 경우..

- pre-trained 된 모델의 task와 높은 상관관계를 가지고 있다면 적은 데이터로도 충분히 feature extraction 을 통해 높은 성능을 낼 수 있다
- 하지만 데이터도 충분하지 않고 pre-trained 모델의 task와의 유사성도 낮다면 overfitting/underfitting 될 확률이 매우 높다
-
따라서 pre-training 모델을 사용하는 데에는 위와같은 조건들이 있다
- 우리의 모델과 pre-trained 모델의 task 유사성과 학습 데이터의 양을 모두 고려해서 transfer learning 을 잘 활용할 수 있는지 없는지가 나뉘게 된다

아기개발자