Dataset
- 데이터 전처리의 개념에 대해서 설명한다
- 컴퍼티션의 경우 어느 정도 정제된 데이터가 주어지지만, 앞으로 우리가 만나게 될 데이터는 cleaning 되어 있지 않는 경우가 많기 때문에 사전에 여러가지 작업들이 필요하다
- 이미지 데이터는 비교적 전처리할 거리가 그렇게 많지는 않지만 정형데이터나 텍스트 데이터의 경우는 상상을 초월하는 전처리를 경험한다
- 그리고, Generalization(일반화) 관점에서 생각해 볼 수 있는 몇 가지 Skill를 다룬다
- 이러한 과정에서 의사결정을 하는데에는 앞서 말한 것 처럼 문제를 어떻게 정의했느냐가 매우 중요한 요소로 활용될 수 있다
Further Reading
Overview
- 주어진 vanilla data를 모델이 좋아하는 형태의 dataset으로 ..

Pre-processing
data science is

- 보통 경진대회용 데이터는 그 품질이 매우 양호한 편..
bounding box
- “가끔 필요 이상으로 많은 정보를 가지고 있기도 한다”

Resize
- 계산의 효율을 위해 적당한 크기로 사이즈 변경
Example: APTOS Blindness Detection
- ”도메인, 데이터 형식에 따라 정말 다양한 Case가 존재”

Generalization
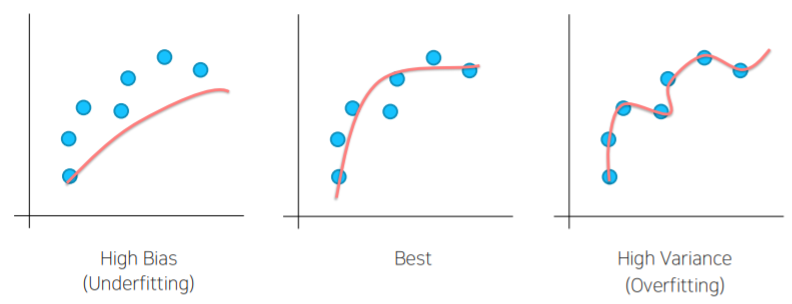
Bias & Variance
- 학습이 너무 안 됐거나, 학습이 너무 됐거나
Train/Validation
- 훈련 셋 중 일정 부분을 따로 분리, 검증 셋으로 활용
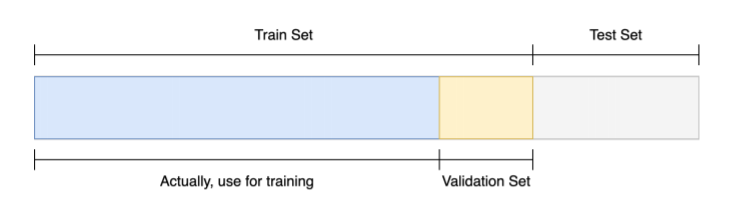
- 검정 셋으로 나눠야 하는 궁극적인 목적
- 학습을 했을때 학습된 결과를 바탕으로 test 셋에 적용을 해서 결과를 볼텐데
- 학습이 사실 제대로 됬는지 검증할 수 있는 방법이 존재하지 않는다
- 이것을 검증하기 위해서 학습에 이용되지 않은 검정 셋을 가지고 검증을 해야지만 모델이 일반화 됬다 안됬다를 판단할 수 있다
- 즉, 검정 셋으로 나누는 이유는 학습에 이용되지 않은 분포가 필요하고 이 분포를 통해서 기학습된 모델이 얼마만큼의 일반화를 가질 수 있는가를 확인 하기 위해서 이다
Data Augmentation
- 주어진 데이터가 가질 수 있는 Case(경우),State(상태)의 다양성

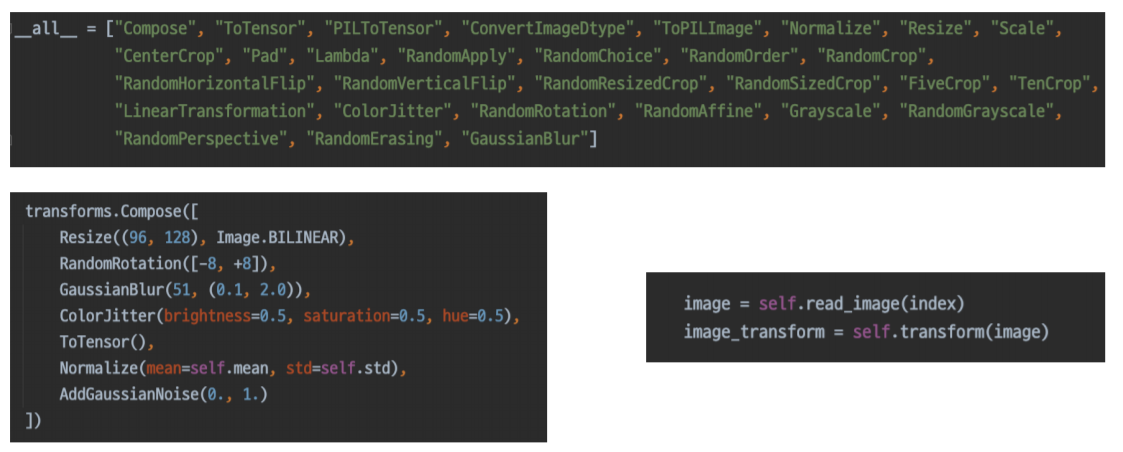
torchvision.transforms
-
Image에 적용할 수 있는 다양한 함수들

-
종류는 많고, 사용은 간편하다!
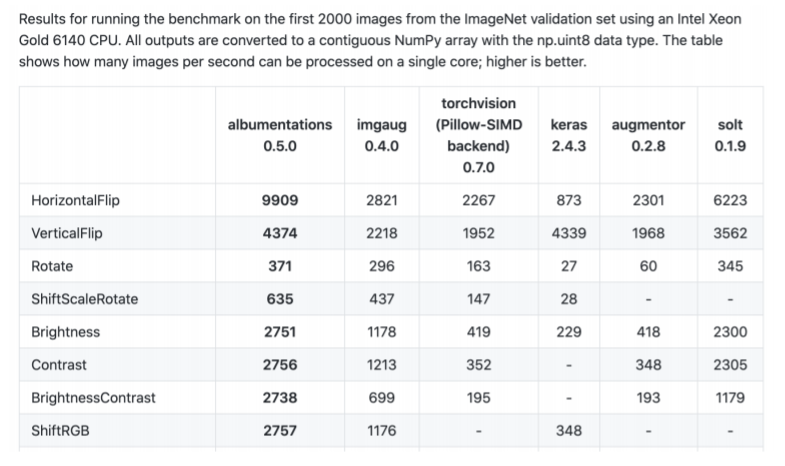
Albumentations 라이브러리
- 더 빠르고, 더 다양하다

‘무조건’ 이라는 단어를 제일 조심하자
- 항상 좋은 결과를 가져다 주지는 않는다
- 이러한 함수들은 여러가지 도구 가운데 하나일 뿐
- 그리고, 무조건 적용 가능한 마스터키 같은 것도 사실 없다
- 앞서 정의한 Problem(주제)을 깊이 관찰해서 어떤 기법을 적용하면 이러이러한 다양성을 가질 수 있겠다 가정하고 실험으로 증명해야 한다
Data Generation
- Vanilla 데이터를 가지고 Dataset을 구성한 다음 모델에 빠르고, 효율적으로 Feeding 하기 위해 알아야 할 것들에 대해서 다룬다
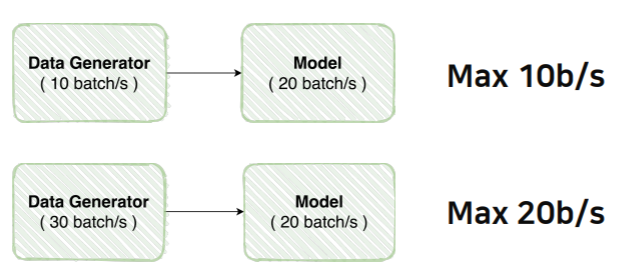
- Data Feeding이라고 말하는 것의 개념과, 실제로 이것을 제대로 하지 않았을 때 어떤 일들이 일어날 수 있는지 알아보자
- 그리고, 파이토치에서 torch.utils.data에 있는 Dataset, DataLoader에 대한 설명과, 그 차이를 다뤄보자
Data Feeding
- 먹이를 주다 = 대상의 상태를 고려해서 적정한 양을 준다
- 예시:
- 여기 어떤 제품을 만드는 공장이 있다고 생각해보자

- 생산량을 늘리려면 역시, 많이 만들면 되지! ...?
- 제작만 늘린다고 해서 만들어지는 제품이 늘어나지 않는다
- 제작이 늘어난다고 해서 포장이 그에 맞게 늘리지 않는다면 제작을 아무리 많이 한들 나오는 제품에는 한계가 있다

- 여기 어떤 제품을 만드는 공장이 있다고 생각해보자
모델에 먹이(Data)를 주다?
- 혹시, 모델 학습을 할 때 비슷한 오류를 범하고 있지 않은가?
Example
- Dataset생성 능력 비교
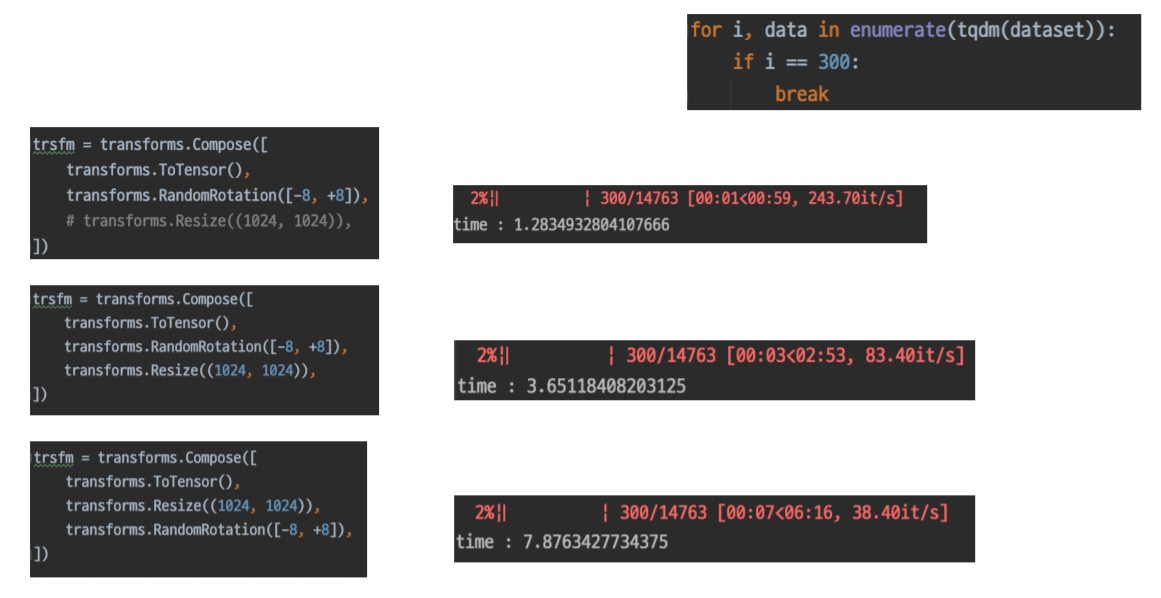
torch.utils.data
Datasets
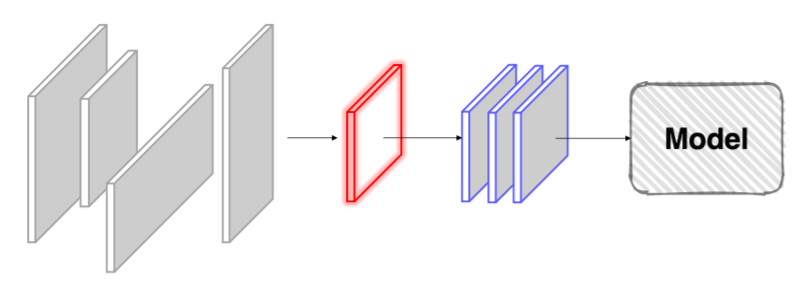
- Dataset 구조
- pytorch에 있는 torch.utils.data에 있는 Dataset 클래스 구조를 아래 간단하게 표현해서 필요한 것들만 나열해서 살펴보자

- import 한 Dataset 클래스를 사용자가 원하는 사용자의 클래스에 상속을 시켜줘야 한다
- 상속 : 사용자가 만든 클래스 MyDataset 이라는 것은 지금 현재 Dataset과 비슷한 클래스(비슷한 부류)에 속한다고 정의하는 것 이라고 생각
- 즉, Dataset을 상속한 사용자가 정의한 MyDataset 클래스 같은 경우는 Dataset의 행세를 할 수 있다라고 이해할 수 있다
- 위에 보이는 여러가지 함수들은 Dataset이라면 가지고 있어야 될 기능들을 모아놓은 것이다
- 애네들이 존재하지 않으면 implementation error가 난다
- init 함수 : 클래스를 선언했을때 최초로 정의됬을때 한번 실행된다
- getitem 함수 : dataset의 데어터 중에서 index위치의 item을 return 해야한다
- len 함수 : 데이터셋 아이템의 전체 길이를 return
- pytorch에 있는 torch.utils.data에 있는 Dataset 클래스 구조를 아래 간단하게 표현해서 필요한 것들만 나열해서 살펴보자
- 혹시 모르니 잠깐 복습하고 가자
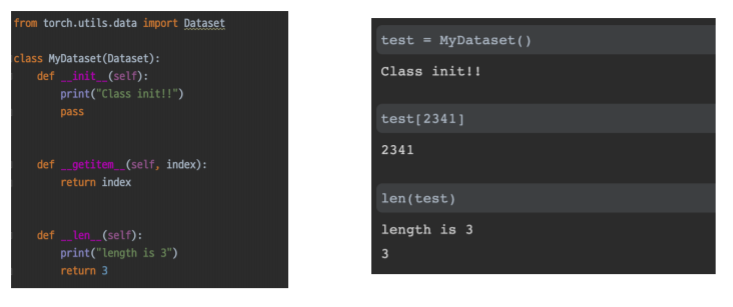
- getitem 함수가 정의 되면 슬라이싱하는 것들이 자동으로 구현이 된다
- test 라는 데이터 셋의 2341번의 요소를 뽑아 올 수 있다
- 위에 정의는 바로 index 를 return 했다
- getitem 함수가 정의 되면 슬라이싱하는 것들이 자동으로 구현이 된다
DataLoader
- 내가 만든 Dataset을 효율적으로 사용할 수 있도록 관련 기능 추가
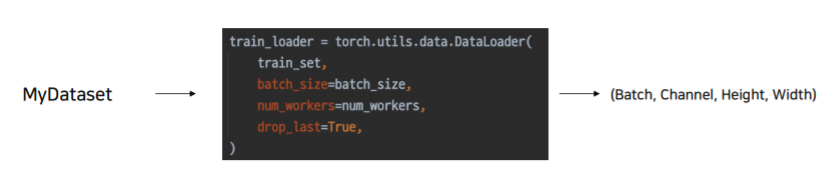
- 엄청 기능이 많다

간단한 실험: num_workers

Dataset과 DataLoader는 분리되는 것이 좋다
- Dataset과 DataLoader는 엄연히 하는 일이 다르다

Further Readings
-
파이토치 공식 Dataset Docs : https://pytorch.org/docs/stable/data.html
-
Dataset, DataLoader Tutorials : https://pytorch.org/tutorials/beginner/data_loading_tutorial.html
-
Data Augmentation 에 도움을 줄 수 있는 다양한 라이브러리가 존재해요. 일례로 Albumentation과 imgaug가 존재해요.각각의 라이브러리는 작동 방식도 다르고 제공하는 기능들도 다 다르기때문에 문서를 살펴보고 자기에게 적합한 기능을 고르는게 중요합니다. 물론 torchvision의 전처리 함수도 훌륭한 기능을 제공합니다.
-
catalyst라는 라이브러리는 파이토치 위에서 다양한 기능을 제공하는 라이브러리인데, 기본 데이터셋 기능을 넘어서 balanced batch sampler와 같은 API를 제공하는 라이브러리에요. 섬세한 학습을 위해 이러한 라이브러리를 살펴보는 것도 도움이 될수 있을거에요.
-
이 깃헙 레포지토리는 다양한 커스텀 데이터셋 예제를 확인할 수 있어요. Task에 맞는 예시를 찾는다면, 큰 도움이 될거에요!

아기개발자