[Contents]
1) RNN and Language Modeling
2) LSTM and GRU
Recurrent Neural Network(RNN) and Language Modeling
- 자연어 처리 분야에서 Recurrent Neural Network(RNN)를 활용하는 다양한 방법과 이를 이용한 Language Model을 학습
- Language Model은 이전에 등장한 단어를 condition으로 다음에 등장할 단어를 예측하는 모델이다
- RNN을 이용한 character-level의 language model에 대해서 알아본다
- RNN을 이용한 Language Model에서 생길 수 있는 초반 time step의 정보를 전달하기 어려운 점, gradient vanishing/exploding을 해결하기 위한 방법 등에 대해 다시 한번 복습할 수 있는 시간
Further reading
RNN
- How to calculate the hidden state of RNNs
- we can process a sequence of vectors by applying a recurrence formula at every time step
- Notice: The same function and the same set of parameters are used at every time step
- : previous hidden-state vector
- : input vector at some time step
- : new hidden-state vector
-
-
-
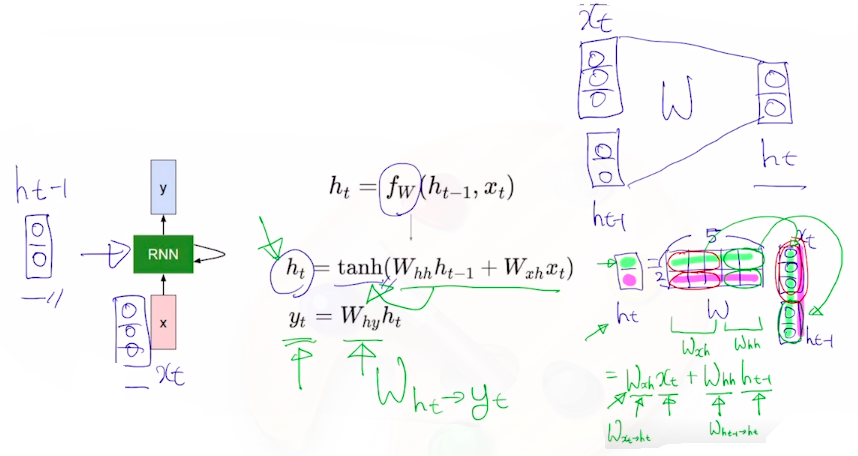
- : RNN function w/ parameters
- : output vector at time step
- 예측값을 나타내는 output 는 매 time step마다 계산해야 하는 경우도 있고 마지막 time step에서만 계산하는 경우도 있다
- 예) 문장 'I study math' 가 주어졌을때 각 단어별로 해당 단어의 품사를 예측해야하는 경우 매 time step마다 각 단어의 품사를 예측하는 값이 나와야한다
- 예) 문장 'I hate this movie' 가 주어졌을때 이 문장이 긍정인지 부정인지 예측해야하는 경우 마지막 단어까지 모두 읽은 후 마지막 time step에서만 긍부정 값을 예측한다
Types of RNNs
-
one-to-one
- standard neural network
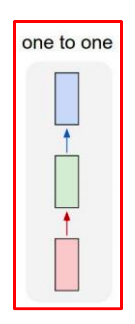
- standard neural network
-
one-to-many
- Image Captioning
- 입력 : 하나의 이미지
- 출력 : 이미지에 대한 설명 글 예측/생성
- 필요한 단어를 time step별로 순차적으로 생성
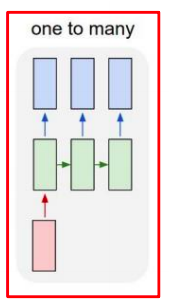
- Image Captioning
-
many-to-one
- sentiment classification(감정분석)
- 입력 : 문장
- 출력 : 감정분석 후 예측
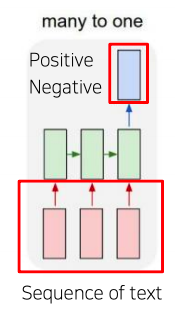
- sentiment classification(감정분석)
-
many-to-many
- machine translation(기계번역)
- 입력 : 영어 문장
- 출력 : 한글 문장
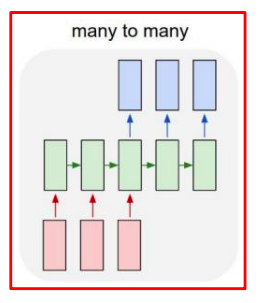
- video classification on frame level
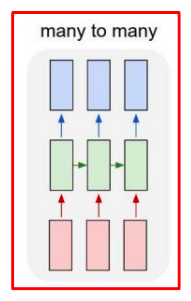
- machine translation(기계번역)
character-level language Model
- example of training sequence 'hello'
- vocabulary : [h,e,l,o]
- 아래 예시에선 의 차원은 3차원으로 정의했다
- Logit =
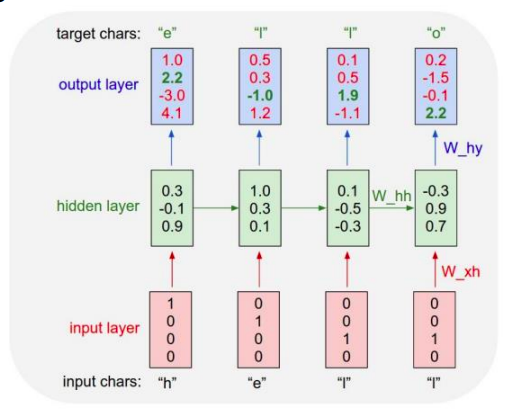
- output layer에 나온 예측 벡터가 target chars의 원핫벡터(ground truth)와 최대한 가까워지게하는 를 찾아 역전파를 이용하여 학습한다
- At test-time, sample characters one at a time, feed back to model
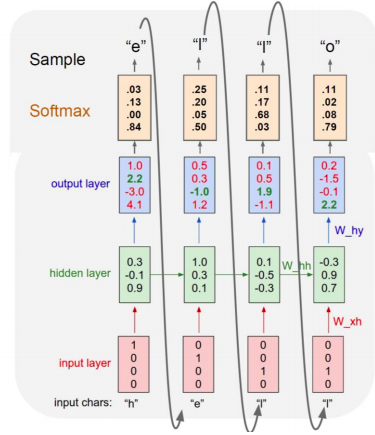
Backpropagation through time(BPTT)
- forward through entire sequence to compute loss, then backward through entire sequence to compute gradient
- 현실적으로 학습해야하는 sequence가 길어지면 한꺼번에 처리할수 있는 정보나 데이터의 양이 한정된 gpu resource 메모리에 모두 담기지 못할수 있기 때문에 truncation (chunk로 잘라서)을 통해 제한된 길이로 하습을 진행한다
- Run forward and backward through chunks of the sequence instead of whole sequence
- carry hidden states forward in time forever, but only backpropagate for some smaller number of steps
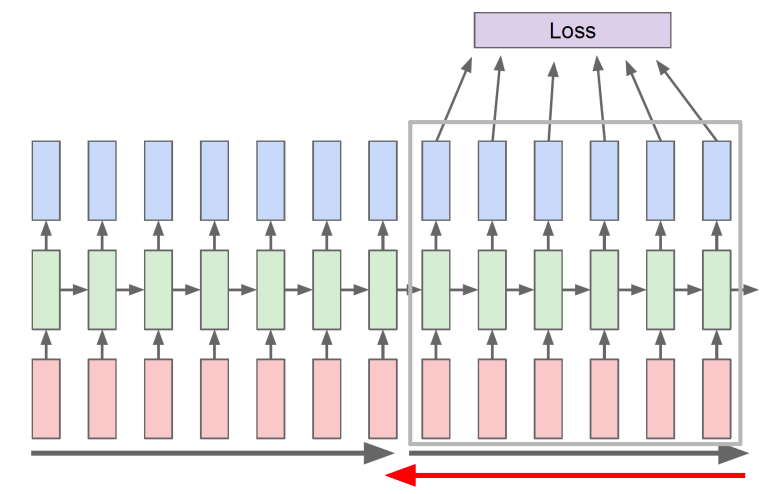
- RNN에서 필요로 하는 정보를 저장하는 공간은 매 time step마다 update를 수행하는 벡터에 담긴다
Vanishing/Exploding Gradient Problem in RNN
- RNN is excellent, but...
- multipling the same matrix at each time step during backpropagation causes gradient vanishing or exploding
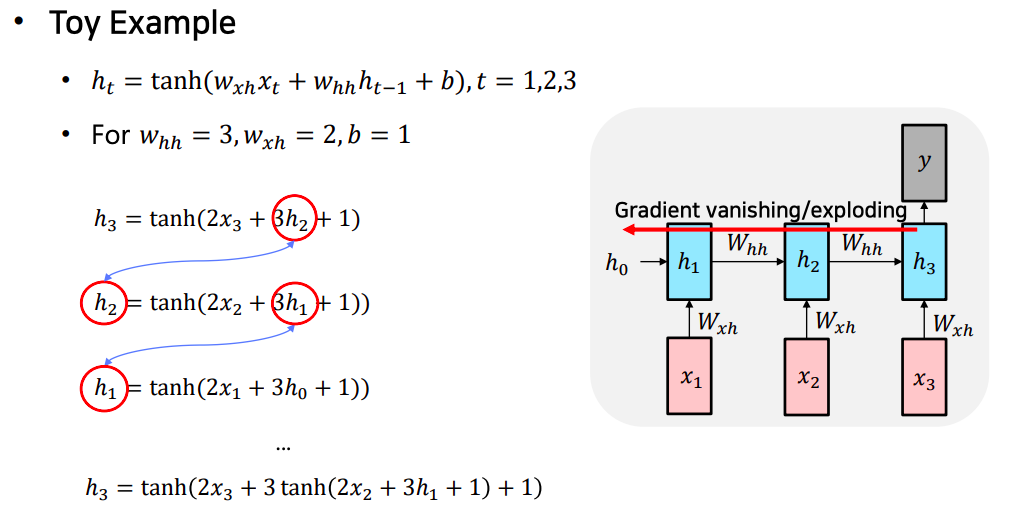
- hidden state vector와 곱해지는 값 3이 time step을 거슬러 올라갈수록 계속 곱해진다
- 마찬가지로 gradient를 계산할때도 3이 time step 갯수만큼 거듭제곱이 되어서 gradient 값이 explode 한다
- 만약 hidden state vector와 곱해지는 값이 0.2 였다면 이 경우는 반대로 0.2가 time step의 차이만큼 곱해지면서 0.2의 거듭제곱이 곱해지면서 빠르게 그 값은 0으로 vanishing 해진다
- 결국엔 모델이 적절하게 학습하는데 필요한 gradient를 time step을 넘어서 전달해주는 과정에서 기하급수적으로 커지거나 작아진다
LSTM and GRU
- RNN을 개선한 알고리즘으로 등장했던 LSTM과 GRU에 대해서 다시 한번 살펴본다
- 기존 vanilla RNN의 gradient vanishing/exploding 문제와 long term dependency의 측면에서 훨씬 더 좋은 성능을 보인다
Further Reading
Further Question
- BPTT 이외에 RNN/LSTM/GRU의 구조를 유지하면서 gradient vanishing/exploding 문제를 완화할 수 있는 방법이 있을까요?
- RNN/LSTM/GRU 기반의 Language Model에서 초반 time step의 정보를 전달하기 어려운 점을 완화할 수 있는 방법이 있을까요?
Long Short-Term Memory(LSTM)
- vanilla RNN의 gradient vanishing/exploding 을 해결하고 time step이 먼 경우에도 필요로하는 정보를 보다 효과적으로 처리하고 학습할 수 있도록 하는 즉, vanilla RNN에서의 long term dependency 를 개선한 모델
- Core idea : pass cell state information straightly w/o any transformation
- solving long-term dependency problem
- LSTM에서는 전 time step에서 넘어오는 정보가 두 가지 이다
- : cell state vector
- : RNN의 hidden state vector와 동일
- cell state vector를 한번 더 가공해서 그 time step에서 노출할 필요가 있는 정보만을 남긴 즉, filtering 된 정보를 담은 벡터
- i : Input gate, whether to write to cell
- f : Forget gate, whether to erase to cell
- o : Output gate, How much to reveal cell
- g : Gate gate, how much to write to cell
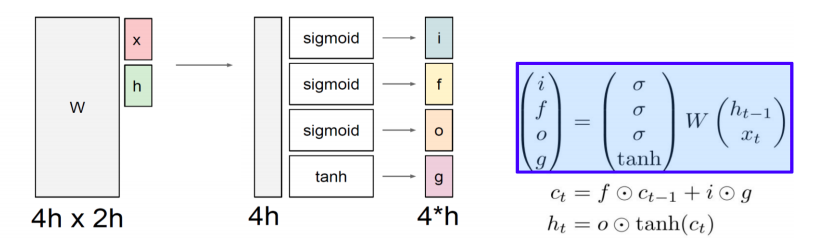
- 4개의 벡터 중 sigmoid를 통해 나오는 처음 3개의 벡터들은 sigmoid의 특성상 각 벡터의 원소들이 0~1 사이의 값을 가지게 된다
- sigmoid를 통해 나온 벡터는 다른 벡터와 element-wise multiplication 을 통해서 원래 값이 가지던 정보에 일부 만을 가지도록 하는 역할
- sigmoid의 값이 0.3 이 나왔을때 이 값과 곱해지는 또다른 벡터의 값이 가령 5였다면
- 0.3 x 5 = 1.5 즉, 5라는 원래값이 가지던 크기의 30% 만큼의 값만을 보존해준다
- 마지막 tanh 통해 나온 값은 tanh 특성상 -1~1 사이의 값을 가지게 되고
- 이는 vanilla RNN에서 선형 결합 후 tanh를 통해서 최종 hidden state vector 를 -1 ~ 1 사이의 값으로써 유의미한 정보를 담는 역할을 했듯이
- 만찬가지로 tanh가 현재 time step에서 LSTM에서 계산되는 유의미한 정보라고 생각할 수 있다
- 기본적으로 이러한 벡터들은 전 time step에서 넘어온 cell state vector 벡터를 적절하게 변환하는데 사용된다
Forget gate
-
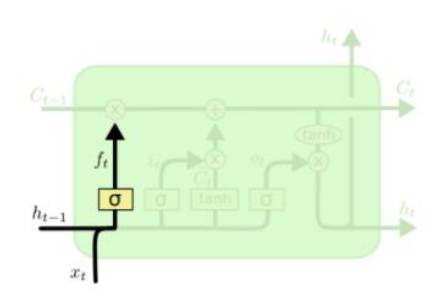
-
이전 cell state vector 에서 3차원 벡터 값인 3,5,-2 가 주어진 경우에 forget gate 와 element wise multiplication을 하는데 sigmoid의 값을 통해 나온 forget gate 값이 가령 0.7, 0.4, 0.8 라 하면
- 이전 cell state vector에서 넘어온 3이라는 첫번째 dimension의 값에서 70% 만큼을 유지해서 2.1 이라는 값을 가지고
- 5라는 두번째 dimension의 값에서 40% 만큼을 유지해서 2.0의 값을
- -2라는 세번째 dimension의 값에서 80% 만큼을 유지해서 -1.6의 값만을 벡터로 유지한다
- forget gate의 forget 이라는 단어의 의미로 볼때 이전 time step에서 넘어온 정보중 70%, 40%, 80% 만 보존한다는 말은 결국 30%, 60%, 20% 를 잊어버리겠다는 뜻과 같아 forget gate라 부르게 된다
Input Gate, Gate gate
- Generate information to be added and cut it by input gate
- Generate new cell state by adding current information to previous cell state
- 현재 time step에서의 를 계산해준다
- Gate gate 인 를 바로 더해주는 것이 아니라 input gate 와 곱한 후 더해주는 것은 다음과 같이 이해할 수 있다
- 가령 한번의 선형 변환만으로 에 더해줄 정보를 만들기가 어려운 경우에는 더해주고자 하는 값보다 좀 더 큰 값들로 구성되있는 정보를 의 형태로 만들어준 후 =
- 그 값에서 각 dimension별로 특정 비율만큼의 정보를 덜어내서 실제로 에 더해주고자 하는 정보를 두 단계에 걸쳐서 만든다는 의미이다 =
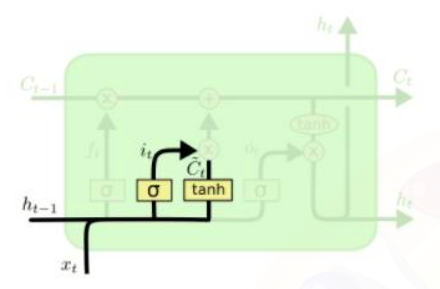
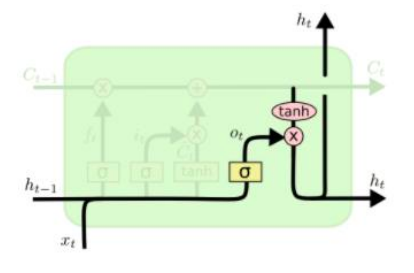
Output gate, Hidden state vector
-
Generate hidden state by passing cell state to tanh and output gate
-
pass this hidden state to next time step, and output or next layer if needed
-
: 기억해야 할 필요가 있는 모든 정보를 담고 있는 벡터
-
: 현재 time step에서 예측값을 내는 output layer의 입력으로 사용되는 벡터로써 해당 time step에 예측값의 직접적으로 필요한 정보만을 담은 형태의 값
Gated Recurrent Unit(GRU)
- What is GRU?
- c.f) in LSTM
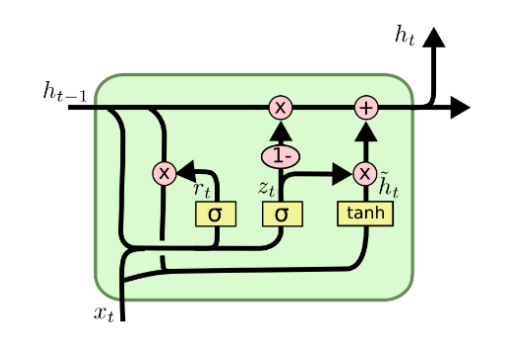
- LSTM과 비교할때 GRU는 모델 구조를 경량화 해서 적은 메모리 요구량과 빠른 계산 시간이 가능하도록 만든 모델
- 내부적으로 볼때 LSTM에서 두 개의 독립된 gate(forget gate, input gate)를 통해서 하던 연산을 GRU에서는 하나의 gate(input gate())만으로 연산을 하므로써 계산량과 메모리 요구량을 LSTM에 비해 훨씬 줄인 경량화 된 모델
- GRU의 가장 큰 특징으로써 LSTM에서 두 가지 종류의 벡터로 존재하던 cell state vector와 hidden state vector 를 통합해서 GRU에서는 오직 hidden state vector 만 존재한다
- GRU의 전체적인 동작 원리는 LSTM과 비슷하다
- 다만 LSTM이 보다 완전한 형태의 정보를 가지는 벡터가 였던만큼 GRU에서는 통합된 벡터인 는 좀 더 LSTM의 cell state vector 와 비슷한 역할을 한다
- GRU에서의 hidden state vector 의 업데이트 과정을 보면
- LSTM에서는 는 forget gate와 이전 time step의 cell state vector 인 의 곱과 input gate와 현재 만들어진 정보인 gate gate 의 곱을 더해주는 과정을 거쳤다면
- GRU에서는 forget gate, input gate 이 두 개의 gate 벡터 중 input gate 인 만을 사용하고 forget gate 자리에는 1 - input gate 값을 사용한다
- 예를 들어 input gate로 사용된 가 0.6, 0.3, 0.8로 구해진 경우에는 1 - 는 0.4, 0.7, 0.2에 해당하는 벡터로 구성된다
- 즉, input gate가 커지면 커질수록 forget gate에 해당하는 값은 점차 작은 값이 된다
- 결국 hidden state vector 는 이전 time step에 hidden state vector 와 현재 만들어진 정보인 이 두개의 정보간의 각각 독립적인 gating을 한 후 더하는 것이 아니라 두 정보간의 가중평균을 내는 형태로 계산된다
Backpropagation in LSTM?GRU
- uninterrupted gradient flow
- 정보를 담는 주된 벡터인 cell state vector가 업데이트 되는 과정이 기존의 vanilla RNN에서 동일한 라는 행렬을 계속적으로 곱해주는 형태의 연산이 아니라 전 time step의 cell state vector에서 그때그때 서로 다른 값으로 이루어진 forget gate 를 곱하고
- 다음엔 필요로 하는 정보를 곱셈이 아닌 덧셈을 통해서 원하는 정보를 만들어준다라는 사실로 인해서 gradient vanishing/exploding 문제가 사라진다
- 기본 적으로 덧셈연산은 backpropagation을 수행할때 gradient를 복사해주는 연산이 되고 따라서 항상 동일한 곱해주는 vanilla RNN에 비해 멀리 있는 time step에 까지 gradient 를 큰변형 없이 전달해줄 수 있고 이를 통해 long term dependency 문제를 해결
summary on RNN/LSTM/GRU
- RNNs allow a lot of flexibility in architecture design
- 다양한 길이를 가질수 있는 sequence 데이터에 특화된 유연한 형태의 딥러닝 모델 구조
- Vanilla RNNs are simple but doesn't work very well
- Backward flow of gradients in RNN can explode or vanish
- Common to use LSTM or GRU: their additive(덧셈) interactions improve gradient flow
References

아기개발자