[Contents]
1) Intro to NLP
2) Bag-of-words
3) Word Embedding
Intro to NLP
- 자연어 처리의 첫 시간으로 NLP에 대해 짧은 소개하고 자연어를 가장 간단한 모델 중 하나인 bag-of-words 를 소개
- Bag-of_words 는 단어의 표현에 있어서 one-hot-encoding을 이용하며, 단어의 등장 순서를 고려하지 않는 아주 간단한 방법 중 하나이다
- 간단한 모델이지만 많은 자연어 task에서 효과적으로 동작하는 알고리즘 중 하나이다
- Bag-of-words 를 이용해 문서를 분류하는 Naive Bayes Classifier 에 대해서 설명
- 단어를 벡터로 표현하는 방법, 문서를 벡터로 표현하는 방법 에 대해 고민해보자
Natural Langauge Processing level
- low-level parsing : 단어를 준비하기 가장 low-level task
- Tokenization
- 문장을 이루는 각 단어들을 정보단위로 생각하고 이러한 단어들을 token이라 부른다
- 주어진 문장을 단어단위로 쪼개나가는 과정을 tokenization이라 부른다
- Stemming
- 수많은 어미의 변화속에서도 단어들이 모두다 같은 의미를 나타내는 단어라는 것을 컴퓨터가 이해할 수 있어야 한다
- 단어의 다양한 의미변화를 없애고 그 의미만을 보존하는 즉, 단어의 어근을 추출하는 것을 stemming이라 한다
- Tokenization
- Word and phrase level
- Named entity recognition(NER)
- 단일 단어 혹은 여러단어로 이루어진 고유명사를 인식하는 task (예: New York Times)
- part-of-speech(POS) tagging
- 단어들이 문장내에서의 품사 혹은 성분이 무엇인지 알아내는 task
- noun-phrase chuncking, dependency parsing, coreference resolution
- Named entity recognition(NER)
- sentence level
- sentiment analysis
- 주어진 문장이 긍정 혹은 부정 어조인지 예측하는 감정 분석
- 또한 this movie was not that bad 라는 문장에서 bad 라는 부정적인 단어가 들어가있음에도 이 문장을 부정이 아닌 긍정으로 분류할 수 이어야 한다
- machine translation (기계번역)
- sentiment analysis
- multi-sentence and paragraph level (다수의 문장 및 문단 level의 task)
- entailment prediction
- 두 문장간의 논리적인 내포 혹은 모순관계를 예측
- 예:
- 문장 1) 어제 John이 결혼을 했다
- 문장 2) 어제 최소한 한명은 결혼을 했다
- 첫 문장이 참인 경우에 두번째 문장은 자동으로 참이 된다
- 하지만 '어제 한명도 결혼하지 않았다' 라는 문장이 주어지면 이 문장은 문장 1 이랑 양립할 수 없는 즉, 논리적으로 모순관계를 가지게 된다
- question answering
- 독해 기반의 질의 응답
- dialog systems
- 챗봇과 같은 대화를 수행할 수 있는 기술
- summarization
- 주어진 문장을 한줄로 요약해주는 task
- entailment prediction
Text mining
- 빅데이터 분석과 관려있다
- extract useful information and insights from text and document data
- e.g., analyzing the trends of AI-related keywords from massive news data
- Document clustering (e.g., topic modeling)
- e.g., clustering news data and grouping into different subjects
- highly related to computational social science
- e.g., analyzing the evolution of people's political tendency based on social media data
Information retrieval (정보 검색)
- highly related to computational social science
- 현재 검색기술은 점차 고도화 되면서 검색 기술은 성숙한 상태를 이루었기 때문에 기술발전도 NLP, text mining 분야에 비해 상대적으로 느리다
- 그렇지만 정보검색 분야에 포함되는 추천시스템의 기술발전은 활발하다
Bag-of-Words
bag-of-words representation
- step 1. text dataset에서 유니크한 단어들을 모아서 사전을 구축
- 예시 문장들: 'John really really loves this movie', 'Jane realy likes this ong'
- 사전: {'John','really','loves','this','movie','Jane','likes','song'}
- 중복된 단어를 제거
- step 2. encoding unique words to one-hot-vectors
- 사전 : {'John','really','loves','this','movie','Jane','likes','song'}
- John: [1 0 0 0 0 0 0 0]
- really: [0 1 0 0 0 0 0 0]
- loves: [0 0 1 0 0 0 0 0]
- this: [0 0 0 1 0 0 0 0]
- movies: [0 0 0 0 1 0 0 0]
- Jane: [0 0 0 0 0 1 0 0]
- likes: [0 0 0 0 0 0 1 0]
- song: [0 0 0 0 0 0 0 1]
- 원핫 벡터의 경우 좌표공간상에서 어떤 단어쌍이든지 간에 유클리디언 거리가 모두 이다
- L2 노름 :
- 코사인 유사도는 모두 0으로 동일하게 계산된다
- 즉, 단어의 의미와 상관없이 모두가 동일한 관계를 가지는 형태로 단어의 벡터 표현을 설정하는 것이다
- 사전 : {'John','really','loves','this','movie','Jane','likes','song'}
- 이러한 단어들로 구성된 문장 혹은 다수의 문장으로 구성된 하나의 문서의 경우에도 word-level에 one-hot vector를 확정해서 나타낼 수 있다
- 각 문장이나 문서에 포함된 단어들의 one-hot vector들을 모두 더한 벡터로서 문장과 그 문서를 나타낼 수 있고 이를 bag-of-words라 부른다
- 문장 1: 'John really really loves this movie'
- John + really + really + loves + this + movie : [1 2 1 1 1 0 0 0]
- 문장 2: 'Jane really likes this song'
- Jane + really + likes + this + song : [0 1 0 1 0 1 1 1]
NaiveBayes Classifier for document classification
- bag-of-words로 나타낸 문서를 정해진 카테고리 혹은 클래스 중에 하나로 분류할 수 있는 대표적인 방법
- 문서가 분류될수 있는 카테고리 혹은 클래스가 총 개 있다고 생각
- 특정한 문서 가 주어질 때 그 문서가 개의 각각 클래스에 속할 확률분포
- = # Bayes Rule
- 여기서 분모는 어떤 특정한 문서 가 뽑힐 확률을 의미하는데 우리는 라는 어떤 문서가 고정된 하나의 문서라고 볼수 있다
- 따라서 이 를 상수값으로 볼 수 있고
- 이 값은 구하고자 하는 operation상에서 무시 할 수 있게 된다
- = # dropping the denominator
- MAP : 'maximun a posteriori' = most likely class
- 가장 높은 확률을 가지는 클래스 를 택하는 방식을 통해서 문서 분류 수행한다
- =
- : 특정 카테고리 가 고정이 되었을때 문서 가 나타날 확률
- 문서 는 첫번째 단어 부터 마지막 단어 까지 동시에 나타나는 동시 사건으로 볼 수 있다
- 각 단어가 등장할 확률 : 가 고정되어 있는 경우 단어들이 서로 독립이라고 가정할 수 있다면 각 단어가 나타낼수 있는 확률을 모두 곱한 형태로 나타낼 수 있다
Example
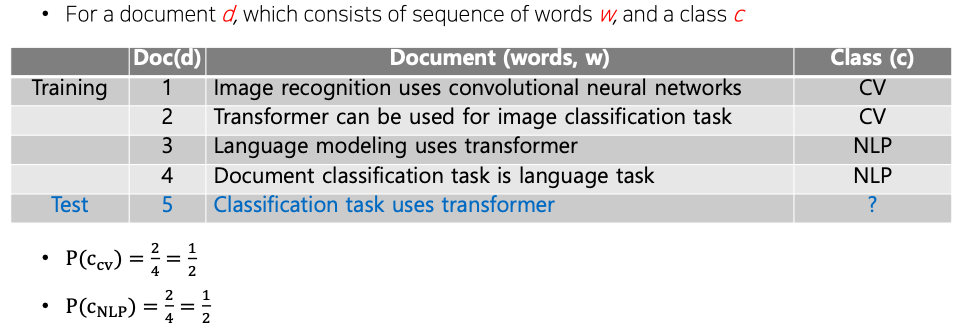
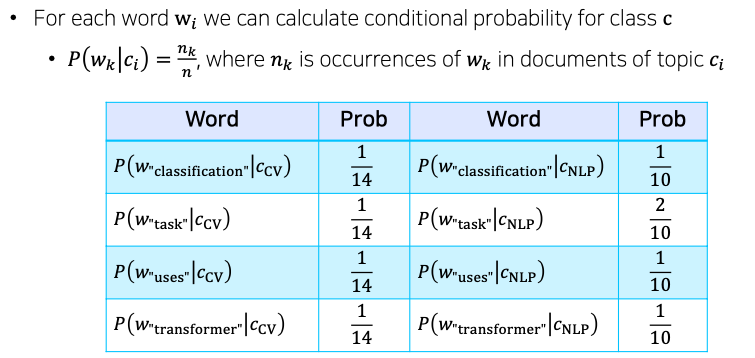

- NaiveBayes Classifier 문제점 :
- 특정한 클래스 내에서 학습 데이터 내에 어떤 특정한 단어가 전혀 발견 되지 않았을 경우 그 해당하는 단어가 나타날 확률은 0으로 추정이 될 것이다
- 이 경우에 그 단어가 포함될 문장이 주어진 경우에는 그 클래스가 될 확률은 무조건 0으로 계산되기 때문에 다른 단어들이 아무리 그 해당 클래스가 밀접한 관련이 있었다 하더라도 절대 그 클래스로 분류되는 것이 불가능 해지게 된다
- 이를 해결하기 위해서 다양한 추가적인 regularization 기법들이 추가되엇 활용된다
Word Embedding
- 단어를 벡터로 표현하는 또 다른 방법인 Word2Vec과 GloVe 를 소개
- Word2Vec과 GloVe는 하나의 차원에 단어의 모든 의미를 표현하는 one-hot-encoding과 달리 단어의 distributed representation을 학습하고자 고안된 모델
Further Reading
Further Question
- Word2Vec과 GloVe 알고리즘이 가지고 있는 단점이 무엇인가?
What is Word Embedding?
- 각 단어들을 어떤 특정한 차원으로 이루어진 공간상의 한 점 혹은 그 점의 좌표를 나타내는 벡터로 변환해주는 기법
- 단어를 벡터로 표현하는 방법으로, 단어를 밀집 표현으로 변환한다
- 'cat' and 'kitty' are similar words, so they have similar vector representations -> short distance
- 'hamburger' is not similiar with 'cat' or 'kitty', so they have differect vector representation -> far distance
희소 표현(Sparse Representation)
- 앞서 원-핫 인코딩을 통해서 나온 원-핫 벡터들은 표현하고자 하는 단어의 인덱스의 값만 1이고, 나머지 인덱스에는 전부 0으로 표현되는 벡터 표현 방법이다
- 이렇게 벡터 또는 행렬(matrix)의 값이 대부분이 0으로 표현되는 방법을 희소 표현(sparse representation)이라고 한다
- 따라서 원-핫 벡터는 희소 벡터(sparse vector)다
- 희소 벡터의 문제점은 단어의 개수가 늘어나면 벡터의 차원이 한없이 커진다다
- 원-핫 벡터로 표현할 때는 갖고 있는 코퍼스에 단어가 10,000개였다면 벡터의 차원은 10,000이다 즉, 단어 집합이 클수록 고차원의 벡터가 된다
- 심지어 그 중에서 단어의 인덱스에 해당되는 부분만 1이고 나머지는 0의 값을 가진다
- 예) 단어가 10,000개 있고 나무란 단어의 인덱스는 3였다면 원 핫 벡터=
- 나무 = [ 0 0 1 0 0 0 0 0 0 0 0 0 ... 중략 ... 0] # 이 때 1 뒤의 0의 수는 9997개.
- 이러한 벡터 표현은 공간적 낭비가 심하다
- 공간적 낭비를 일으키는 것은 원-핫 벡터뿐만은 아니라 희소 표현의 일종인 DTM과 같은 경우에도 특정 문서에 여러 단어가 다수 등장하였으나,
- 다른 많은 문서에서는 해당 특정 문서에 등장했던 단어들이 전부 등장하지 않는다면 역시나 행렬의 많은 값이 0이 되면서 공간적 낭비를 일으킨다
- 뿐만 아니라, 원-핫 벡터는 단어의 의미를 담지 못한다는 단점이 있다
밀집 표현(Dense Representation)
- 희소 표현과 반대되는 표현
- 밀집 표현은 벡터의 차원을 단어 집합의 크기로 상정하지 않고 사용자가 설정한 값으로 모든 단어의 벡터 표현의 차원을 맞춘다
- 또한, 이 과정에서 더 이상 0과 1만 가진 값이 아니라 실수값을 가지게 된다
- 예) 10,000개의 단어가 있을 때 나무란 단어를 밀집 표현을 사용하고, 사용자가 밀집 표현의 차원을 128로 설정한다면, 모든 단어의 벡터 표현의 차원은 128로 바뀌면서 모든 값이 실수가 된다
- 나무 = [0.2 1.8 1.1 -2.1 1.1 2.8 ... 중략 ...] # 이 벡터의 차원은 128
- 이 경우 벡터의 차원이 조밀해졌다고 하여 밀집 벡터(dense vector)라한다
워드 임베딩(Word Embedding)
- 단어를 밀집 벡터(dense vector)의 형태로 표현하는 방법
- 밀집 벡터를 워드 임베딩 과정을 통해 나온 결과라고 하여 임베딩 벡터(embedding vector)라고도 한다
| 원-핫 벡터 | 임베딩 벡터 | |
|---|---|---|
| 차원 | 고차원(단어 집합의 크기) | 저차원 |
| 다른 표현 | 희소 벡터의 일종 | 밀집 벡터의 일종 |
| 표현 방법 | 수동 | 훈련 데이터로부터 학습 |
| 값의 타입 | 1과 0 | 실수 |
Word2Vec
- 같은 문장에서 나타난 인접한 단어들간에 의미가 비슷할 것이라는 가정을 사용한다
- 따라서 어떤 한 단어가 주변에 등장하는 단어들을 통해 그 의미를 알 수 있다라는 아이디어에서 착안
- 주어진 학습를 바탕으로 어떤 단어가 주변에 나타나는 단어들의 확률분포를 예측하게 된다

- 주어진 학습를 바탕으로 어떤 입력단어가 주어지고 주변 단어를 숨긴채 입력단어를 예측하는 방식으로 Word2Vec 모델의 학습이 진행된다
How Word2Vec Algorithm Works
- sentence : 'I study math.'
- Vocabulary : {'I','study','math'}
- Input : 'study' [0, 1, 0]
- Output : 'math' [0, 0, 1]
- sliding 기법:
- 한 단어를 중심으로 앞뒤로 나타난 단어각각과 입출력 단어 쌍을 구성하게 된다
- ex) 윈도우 사이즈 : 1
- 문장 : 'I study math'
- 첫번째 입출력 쌍 : (I, study)
- 두번째 입출력 쌍 : (study, I), (study, math)
- 세번째 입출력 쌍 : (math, study)
- 문장 : 'I study math'
- 이러한 방식으로 주어진 학습데이터에 대해서 각 문장별로 sliding window 기법을 적용하여 word2vec의 학습데이터를 구성할 수 있다
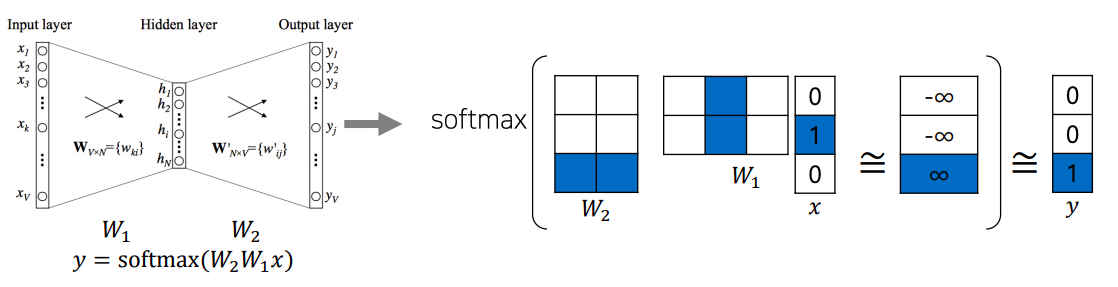
- E.g., 'study' vector: column in , 'math' vector : row in
- the 'study' vector in and the 'math' vector in should have a high inner-product value
- columns of and rows of represent each word
- 만들어진 많은 입출력 쌍 들에 대해 예측 task를 수행하는 two-layer neural net이다
- 구체적으로는 각 단어가 vocabulary size만큼에 해당하는 즉 위 예시로는 3차원의 one-hot vector로 나타나기 때문에 입력과 출력 label의 노드수는 모두 3개가 된다
- 그리고 입출력이 각각 입력 및 출력 단어에 해당하고
- 또한 가운데에 있는 hidden layer에 있는 노드 수는 사용자가 정하는 hyper-parameter 로써 word embedding을 수행하는 좌표공간의 차원수와 동일한 값으로 설정한다
Property of Word2Vec
- 학습된 word2vec은 단어들간의 의미론적 관계를 vector embedding의 결과에 학습한다
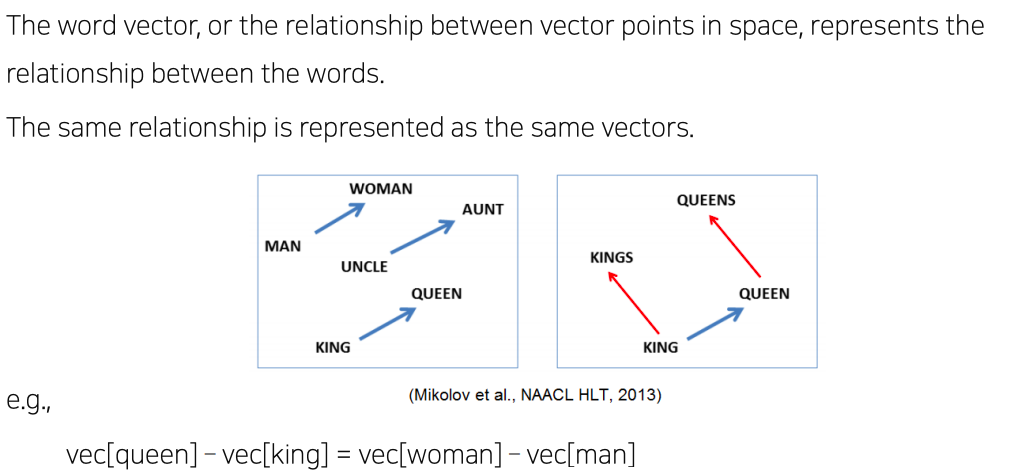
- word intrusion detection task
- 여러 단어들이 주어져있을때 이 중 나머지 단어와 그 의미가 가장 상이한 단어를 찾아내는 task
- ex) staple hammer saw drill
GloVe : Global Vectors for Word Representation
- rather than going through each pair of an input and an output words, it first computes the co-occurrence matrix, to avoid training on identical word pairs repetitively
- Afterwards, it performs matrix decomposition on this co-occurrent matrix
- word2vec과의 가장 큰 차이점 :
- 각 입력 및 출력 단어 쌍들에 대해서 학습데이터에서 두 단어가 한 윈도우내에서 총 몇번 동시에 등장했는지를 사전에 계산하고 그 값에 로그 값을 취한다
- 그 입력 단어의 embedding vector()와 출력 단어의 embedding vector() 간의 내적값에서 로그를 취해준 값의 빼준다
- GloVe모델의 학습 방법
- word2vec 의 경우에는 특정한 입출력쌍이 자주 등장하는 경우에는 여러번에 걸쳐서 학습 되므로써 내적값이 더 커지도록 하는 학습방식을 따랐다면
- GloVe 에서는 어떤 단어쌍이 동시에 등장한 횟수를 미리 계산하고 이에대한 로그값을 취한 값을 직접적인 두 단어간의 내적값의 ground truth로써 사용해서 학습을 진행하므로 중복되는 계산을 줄여줄 수 있다
- 따라서 학습이 상대적으로 더 빠르게 진행될수 있고 보다 더 적은 데이터에 대해서도 잘 동작한다
key takeaways
- Word2vec과 GloVe 모두 주어진 학습데이터(text data)에 기반해서 word embedding을 학습하는 알고리즘
CBOW(Continuous Bag-of-Words)
- 주변 단어들을 가지고 중심 단어를 예측하는 방식으로 학습
- 주변 단어들의 one-hot encoding 벡터를 각각 embedding layer에 projection하여 각각의 embedding 벡터를 얻고 이 embedding들을 element-wise한 덧셈으로 합친 뒤, 다시 linear transformation하여 예측하고자 하는 중심 단어의 one-hot encoding 벡터와 같은 사이즈의 벡터로 만든 뒤, 중심 단어의 one-hot encoding 벡터와의 loss를 계산
- 예) A cute puppy is walking in the park. & window size: 2
- Input(주변 단어): "A", "cute", "is", "walking"
- Output(중심 단어): "puppy"
Skip-gram
- 중심 단어를 가지고 주변 단어들을 예측하는 방식으로 학습
- 중심 단어의 one-hot encoding 벡터를 embedding layer에 projection하여 해당 단어의 embedding 벡터를 얻고 이 벡터를 다시 linear transformation하여 예측하고자 하는 각각의 주변 단어들과의 one-hot encoding 벡터와 같은 사이즈의 벡터로 만든 뒤, 그 주변 단어들의 one-hot encoding 벡터와의 loss를 각각 계산
- 예) A cute puppy is walking in the park. & window size: 2
- Input(중심 단어): "puppy"
- Output(주변 단어): "A", "cute", "is", "walking"

아기개발자