셸 정렬
셸 정렬은 우선적으로 버블 정렬과 삽입 정렬에 대한 이야기가 필요하다.
버블 정렬이나 삽입 정렬이 수행되는 과정은 이웃하는 원소끼리의 자리 이동으로 원소들이 정렬된다.
버블 정렬이 오름차순으로 정렬하는 과정에서 작은 숫자가 배열의 앞부분으로 매우 느리게 이동한다.
그리고 삽입 정렬의 경우는 만일 배열의 마지막 원소가 가장 작은 숫자일 경우 그 숫자가 배열의 맨 앞으로 이동해야 하므로, 모든 다른 숫자들이 1칸씩 뒤로 이동해야한다.
셸 정렬은 이러한 단점을 보완하기 위해서 삽입 정렬을 이용하여 배열 뒷부분의 작은 숫자들을 앞부분으로 빠르게 이동시키고,
동시에 앞부분의 큰 숫자들은 뒷부분으로 이동시키고, 그리고 가장 마지막에는 삽입 정렬을 수행하는 알고리즘이다.

셸 정렬 아이디어
만약 아래와 같이 값이 저장된 배열이 존재한다고 하자.
30 60 90 10 40 80 40 20 10 60 50 30 40 90 80
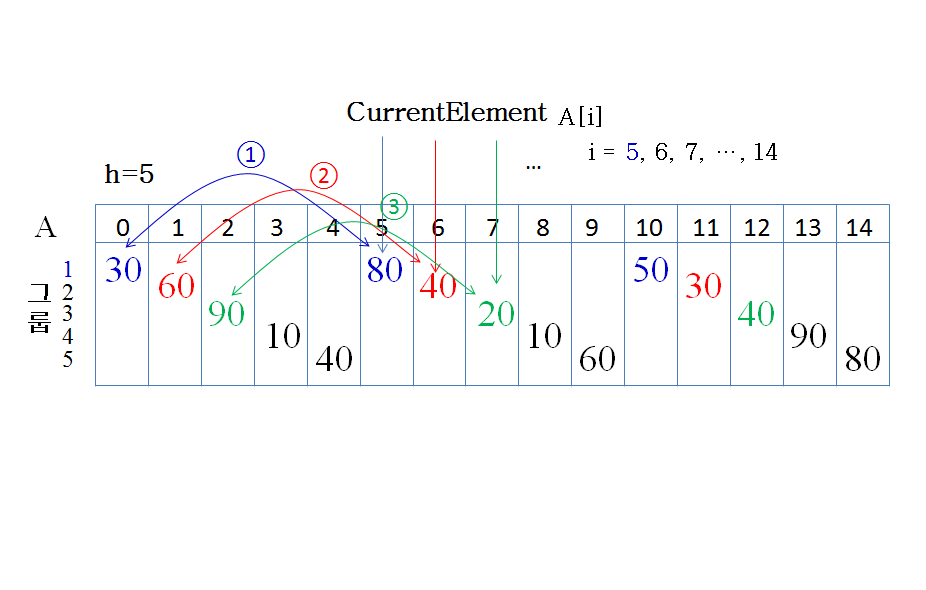
먼저 간격 (gap)이 5가 되는 숫자끼리 그룹을 만든다.

각 그룹 별로 삽입 정렬을 수행한 결과를 1줄에 나열해 보면 다음과 같다.
30 30 20 10 40 / 50 40 40 10 60 / 80 60 90 90 80
간격이 5인 그룹 별로 정렬한 결과
- 80과 90같은 큰 숫자가 뒷부분으로 이동하였고,
- 20과 30같은 작은 숫자가 앞부분으로 이동하였다.
그 다음엔 간격을 5보다 작게 하여, 예를 들어, 3으로 하여, 3개의 그룹으로 나누어 각 그룹별로 삽입 정렬을 수행한다.
- 이때에는 각 그룹에 5개의 숫자가 있다.
최종적으로 마지막에는 반드시 간격을 1로 놓고 수행해야 한다.
- 그 이유는, 다른 그룹에 속해 서로 비교되지 않은 숫자가 있을 수 있기 때문이다.
- 즉, 모든 원소를 1개의 그룹으로 여기는 것이고, 이는 삽입 정렬 그 자체이다.
- 삽입 정렬은 대강 정렬이 되어있는 상태에서 좋은 성능을 발휘한다.
// 수도코드
A[N]; // 크기가 N인 정렬되지 않은 배열
shell_Sort(A);
shell_Sort(A){
gap = [ g0 > g1 > ... > gk = 1 ]; // 큰 gap부터 차례로 저장된 gap배열, 마지막 gap은 반드시 1
for(g : gap){
for(i = 0; i < g; i++) { // gap 만큼 반복한다
insertion_Sort(i, gap); // 삽입 정렬
}
}
}
insertion_Sort(i, gap){
for(j = i + gap; j < N; j += gap){ // gap만큼 점프하며 삽입 정렬 수행
for(x = i; x < j; x += gap){
if(A[x] > A[j]){
swap(A, x, j);
}
}
}
}
swap(A, i, j){
temp = A[i];
A[i] = A[j];
A[j] = temp;
}

만약 gap의 5라서 5개의 그룹이 구분되면, 각 그룹별로 삽입 정렬을 수행한다.
이 과정으로 인해 앞에 있는 큰 수가 빠르게 뒤로 가고, 뒤에 있는 작은 수가 빠르게 앞으로 올 수 있게 된다.
gap을 차차 줄여가며, 최종적으로 gap을 1을 둔 삽입 정렬을 시행한다.
삽입 정렬은 이미 어느정도 정렬이 된 상태일수록 효율이 O(n) 에 가까워 진다.
시간복잡도
셸 정렬의 최악 경우의 시간복잡도는 O(n^2) 이며, 셸 정렬의 수행 속도는 간격 선정에 따라 좌우된다.
셸 정렬은 1959년에 발표될 정도로 역사가 오래된 정렬 알고리즘인 만큼, 이 알고리즘에 대한 많은 실험들이 진행되어왔다.
그 중 가장 유명한 gap 설정 방법인 히바드(Hibbard) 간격을 사용하면 O(n^(1.5)) 라고 한다.
히바드 간격은 시작 간격을 2^k - 1로 두고 k를 1씩 줄여서 2^k -1, ... , 15, 7, 3, 1로 간격을 설정하는 방법이다.
이 후 많은 실험을 통한 현재까지의 셸 정렬의 최적의 시간복잡도는 O(n^(1.25)) 으로 알려지고 있다.
아직까지는 가장 좋은 간격이 무엇인지 밝혀지지 않기 때문에, 셸 정렬의 시간 복잡도는 아직 풀리지 않은 문제 이다.
지금까지 알려진 가장 좋은 성능을 보인 간격은 Marcin Ciura이 밝혀낸 1750, 701, 301, 132, 57, 23, 10, 4, 1 이라고 한다.
마지막으로 정리하자면, 셸 정렬은 입력 크기가 매우 크지 않은 경우에 매우 좋은 성능을 보인다.
셸 정렬은 임베디드(Embedded) 시스템에서 주로 사용되는데, 셸 정렬의 특징인 간격에 따른 그룹 별 정렬 방식이 H/W로 정렬 알고리즘을 구현하는데 매우 적합하기 때문이라고 한다.
