1. 분류
- SQL 쿼리문은 역할에 따라 3가지로 분류
쿼리 (Query)
- "질의문"
- 검색할 때 입력하는 검색어 = 일종의 '쿼리'
검색을 할 때, 기존에 존재하는 데이터를 검색어로 필터링하므로, 쿼리는 저장되어 있는 데이터를 필터하기 위한 질의문으로도 볼 수 있다.
1) DDL (Data Definition Language, 데이터 정의어)
참고: SQL - DDL (CREATE, ALTER, DROP, TRUNCATE, COMMENT, RENAME)
2) DML (Data Manipulation Language, 데이터 조작어)
참고: SQL - DML (SELECT, INSERT, UPDATE, DELETE, MERGE, CALL, EXPLAIN PLAN, LOCK TABLE)
3) DCL (Data Control Language, 데이터 제어어)
참고: SQL - DCL (GRANT, REVOKE, DENY)
4) TCL
참고: SQL - TCL (COMMIT, ROLLBACK, SAVEPOINT, SET TRANSACTION)
2. 중요도 순서
-
DML(DB 조회, 관리) -
DDL(DB의 테이블의 스키마(설계 수준) 수정) -
DCL(DBA(DataBase Administration, 데이터베이스 관리자)가 주로 사용. 일반 개발자는 사용할 일이 드묾)
3) 구현
(1) 테이블 자동 등록
-
MAJOR 테이블
1) 생성//주특기의 종류, 담당 튜터의 정보를 저장하는 MAJOR 테이블 CREATE TABLE IF NOT EXISTS MAJOR ( major_code varchar(100) primary key comment '주특기코드', //ROW를 구분하기 위해, major_code에 primary key를 적용시킴 major_name varchar(100) not null comment '주특기명', tutor_name varchar(100) not null comment '튜터' )2) 추가 (저장)
MAJOR 테이블에 데이터 저장INSERT INTO MAJOR VALUES('m1', '스프링', '남병관'); INSERT INTO MAJOR VALUES('m2', '노드', '강승현'); ... INSERT INTO MAJOR VALUES('m8', '엥귤러', '한현아'); -
STUDENT 테이블
1) 생성//수강생 정보를 저장하는 STUDENT 테이블 CREATE TABLE IF NOT EXISTS STUDENT ( student_code varchar(100) primary key comment '수강생코드', //ROW를 구분하기위해, student_code에 primary key를 걸었음 name varchar(100) not null comment '이름', //이름은 null값을 허용함 birth varchar(8) null comment '생년월일', gender varchar(1) not null comment '성별', phone varchar(11) null comment '전화번호', //전화번호는 null값을 허용함 major_code varchar(100) not null comment '주특기코드', foreign key(major_code) references major(major_code) //수강생이 수강하는 주특기를 관리하기 위해 major_code에 foreign key를 추가 )2) 추가 (저장)
STUDENT 테이블에 데이터 저장INSERT INTO STUDENT VALUES('s1', '최원빈', '20220331', 'M', '01000000001', 'm1'); //INSERT는 VALUES 뒤에 순서대로 값을 넣어주면, 모든 칼럼의 값을 넣을 수 있음 INSERT INTO STUDENT VALUES('s2', '강준규', '20220501', 'M', '01000000002', 'm1'); INSERT INTO STUDENT VALUES('s3', '김영철', '20220711', 'M', '01000000003', 'm1'); ... INSERT INTO STUDENT VALUES('s10', '심선아', '20220504', 'F', '01000000010', 'm8'); INSERT INTO STUDENT VALUES('s11', '변정섭', '20220222', 'M', '01000000020', 'm2'); INSERT INTO STUDENT(student_code, name, gender, major_code) VALUES('s12', '권오빈', 'M', 'm3'); //예외) STUDENT 테이블 생성 시, 이름, 전화번호에 NULL값을 허용했어서 값을 넣어줄 필요가 없을 수도 있음 INSERT INTO STUDENT VALUES('s13', '김가은', '20220121', 'F', '01000000030', 'm1'); //--> 이때는 VALUES 앞에 값을 넣어줄 칼럼명을 명시해야함 INSERT INTO STUDENT(student_code, name, gender, major_code) VALUES('s14', '김동현', 'M', 'm4'); INSERT INTO STUDENT VALUES('s15', '박은진', '20221101', 'F', '01000000040', 'm1'); INSERT INTO STUDENT(student_code, name, birth, gender, phone, major_code) VALUES('s16', '정영호', '20221105', 'M', '01000000050', 'm5'); INSERT INTO STUDENT(student_code, name, gender, major_code) VALUES('s17', '박가현', 'F', 'm7'); INSERT INTO STUDENT(student_code, name, birth, gender, phone, major_code) VALUES('s18', '박용태', '20220508', 'M', '01000000060', 'm6'); INSERT INTO STUDENT VALUES('s19', '김예지', '20220505', 'F', '01000000070', 'm2'); INSERT INTO STUDENT VALUES('s20', '윤지용', '20220909', 'M', '01000000080', 'm3'); INSERT INTO STUDENT VALUES('s21', '손윤주', '20220303', 'F', '01000000090', 'm6'); -
EXAM 테이블
1) 생성//수강생의 성적을 주차별로 관리하는 EXAM 테이블 CREATE TABLE IF NOT EXISTS EXAM ( student_code varchar(100) not null comment '수강생코드', exam_seq int not null comment '시험주차', score decimal(10,2) not null comment '시험점수', result varchar(1) not null comment '합불' )2) 수정
EXAM 테이블에 PK, FK를 설정ALTER TABLE EXAM ADD PRIMARY KEY(student_code, exam_seq); ALTER TABLE EXAM ADD CONSTRAINT exam_fk_student_code FOREIGN KEY(student_code) REFERENCES STUDENT(student_code);3) 추가 (저장)
EXAM 테이블에 데이터 저장INSERT INTO EXAM VALUES('s1', 1, 8.5, 'P'); INSERT INTO EXAM VALUES('s1', 2, 9.5, 'P'); INSERT INTO EXAM VALUES('s1', 3, 3.5, 'F'); INSERT INTO EXAM VALUES('s2', 1, 8.2, 'P'); INSERT INTO EXAM VALUES('s2', 2, 9.5, 'P'); ... INSERT INTO EXAM VALUES('s21', 1, 9.5, 'P'); INSERT INTO EXAM VALUES('s21', 2, 8.8, 'P'); INSERT INTO EXAM VALUES('s21', 3, 8.2, 'P');
(2) 수정(UPDATE), 삭제(DELETE)
INSERT INTO STUDENT VALUES('s0', '수강생', '20220331', 'M', '01000000005', 'm1');
//STUDENT 테이블에서 수강생의 major_code를 m1 --> m2 로 바꿈(UPDATE)
UPDATE STUDENT SET major_code= 'm2' where student_code= 's0';
//UPDATE가 잘 적용됐는지 확인
//DELETE가 잘 적용됐는지 확인
SELECT * FROM STUDENT WHERE STUDENT_CODE = 's0'
//STUDENT 테이블에서 수강생 s0를 삭제(DELETE)
DELETE FROM STUDENT WHERE student_code = 's0';(3) 조회(SELECT)
//STUDENT 테이블 전체의 데이터와 칼럼들을 가져올 수 있음
SELECT * FROM STUDENT;
//WHERE 조건문을 사용하면, 특정 수강생의 정보를 가져올 수 있음
SELECT * FROM STUDENT WHERE STUDENT_CODE = 's1';
//특정 수강생의 특정 칼럼을 가져올 수 있음
SELECT name, major_code FROM STUDENT WHERE student_code = 's1'; (4) JOIN
//STUDENT 테이블과 MAJOR 테이블을 JOIN해서, 모든 컬럼을 볼 수 있음
//STUDENT의 이름, STUDENT의 major_code, MAJOR의 major_name를 필드값으로 선택하고, JOIN으로 값을 매칭시킴
SELECT s.name, s.major_code, m.major_name FROM STUDENT s JOIN MAJOR m ON s.major_code = m.major_code;
//JOIN을 하지 않고도, 위의 코드와 같은 결과값을 도출할 수 있음
//FROM 뒤에 원하는 테이블을 2개(STUDENT 테이블, MAJOR 테이블) 두고, WHERE 조건문을 사용해서, 기준이 되는 컬럼(s.major_code)과 같다(=)고 표시
SELECT s.name, s.major_code, m.major_name FROM STUDENT s, MAJOR m WHERE s.major_code = m.major_code;4) 추가 예시
(1) NOT NULL, PK, FK
//수강생을 관리하는 MANAGER 테이블
CREATE TABLE IF NOT EXISTS MANAGER
//comment를 사용해서 컬럼과 테이블에 설명을 추가
//컬럼: id, name, student_code
(
id bigint primary key comment 'PK', //bigint 타입(정수형 타입), PK
name varchar(100) not null comment '매니저명', //최소 2자 이상, varchar 타입(문자열 타입. 문자열의 최대 길이를 지정), not null
student_code varchar(100) not null comment '수강생코드', //STUDENT 테이블을 참조하는 FK이며, not null
//ALTER을 사용하지 않고, CREAT문에서 바로 설정 가능
//manager_fk_student_code: CONSTRAINT의 이름, student_code: 컬럼명, student: 참조한 테이블, student_code: 참조한 테이블의 컬럼명
CONSTRAINT manager_fk_student_code foreign key(student_code) references student(student_code) //FK(Foreign Key)는 CONSTRAINT 이름을 ‘manager_fk_student_code’ 로 지정
)NOT NULL
해당 필드는 NULL 값을 저장할 수 없게 된다.
참고: JPA 연관관계 (+ ERD) - 정의 - 기본 키(PK, Primary Key), 외래 키(FK, Foreign Key)
(2) AUTO_INCREMENT
ALTER TABLE MANAGER ALTER COLUMN id bigint auto_increment; //ALTER, MODIFY를 이용하여 MANAGER 테이블의 id 컬럼에 AUTO_INCREMENT 기능을 부여AUTO_INCREMENT
- MySQL의 int(int,bigint,smallint 등) 자료형 컬럼에 기본키(PK)가 설정된 컬럼에 대해서 자동 증가 번호 기능
- INSERT할때, ID값을 추가하지 않았는데, ID값이 자동으로 1씩 증가하면서 늘어난 게 붙어있음
- 레코드 추가 시 자동으로 고유한(unique) 숫자가 부여됨
UNIQUE
- 해당 필드는 서로 다른 값을 가져야만 합니다
- 사용 형태: 필드이름 필드타입 UNIQUE,
(3) INSERT
// INSERT를 이용하여 수강생 s1, s2, s3, s4, s5를 관리하는 managerA와 s6, s7, s8, s9를 관리하는 managerB를 추가하세요.(AUTO_INCREMENT 기능을 활용)
INSERT INTO MANAGER(name, student_code) VALUES('managerA', 's1');
INSERT INTO MANAGER(name, student_code) VALUES('managerA', 's2');
INSERT INTO MANAGER(name, student_code) VALUES('managerA', 's3');
INSERT INTO MANAGER(name, student_code) VALUES('managerA', 's4');
INSERT INTO MANAGER(name, student_code) VALUES('managerA', 's5');
INSERT INTO MANAGER(name, student_code) VALUES('managerB', 's6');
INSERT INTO MANAGER(name, student_code) VALUES('managerB', 's7');
INSERT INTO MANAGER(name, student_code) VALUES('managerB', 's8');
INSERT INTO MANAGER(name, student_code) VALUES('managerB', 's9');
SELECT * FROM MANAGER; //잘 추가됐는지 확인(4) JOIN
- 기본 JOIN
SELECT 필드이름1, 필드이름2, ...
FROM 테이블이름1
옵션 JOIN 테이블이름2 ON 테이블이름1.필드이름 = 테이블이름2.필드이름
// 예시
// JOIN을 사용하여 managerA가 관리하는 수강생들의 이름과 시험 주차 별 성적을 가져오세요.
SELECT s.name, e.exam_seq, e.score
// MANAGER, STUDENT, EXAM 모두 JOIN 했음
FROM MANAGER m JOIN STUDENT S on m.student_code = s.student_code
JOIN EXAM e on m.student_code = e.student_code WHERE m.name = 'managerA';
select STUDENT_CODE, EXAM_SEQ, SCORE from EXAM where STUDENT_CODE in ('s1', 's2', 's3', 's4', 's5')
//SELECT와 FROM을 행을 나눠서 쓸 수도 있네- 서로 다른 테이블에서 가져온 레코드들을 공통된 필드를 기준으로 합쳐준다.
- 나누어진 테이블을 하나로 합치기 위해 DB 가 제공하는 기능
- ON 이라는 키워드를 통해, 기준이 되는 컬럼을 선택하여 2개의 테이블을 합침
- JOIN을 할 때에는 적어도 하나의 컬럼을 서로 공유하고 있어야 하기 때문에,
테이블에 외래키가 설정 되어 있다면 해당 컬럼을 통해 JOIN을 하면 해당 조건을 충족할 수 있습니다.
(단, JOIN을 하기 위해 외래키를 설정하는 것이 항상 좋은 선택은 아닐 수 있음)
- INNER
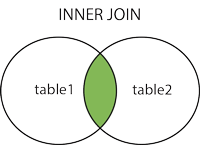
// Orders, Customers 테이블 양쪽 모두에 동일한 CustomerID 필드 값을 가지는 레코드들을 모두 가져온다.
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate
FROM Orders
INNER JOIN Customers
ON Orders.CustomerID=Customers.CustomerID; // Orders 테이블의 CustomerID 필드는 Customers 테이블의 CustomerID 필드를 참조- 두 테이블 모두에 기준 필드의 값이 있는 레코드만 가져온다.
- LEFT
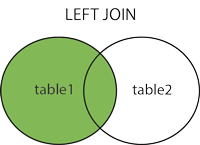
-
왼쪽 테이블(테이블이름1)에 있는 모든 레코드를 가져오고,
기준 필드의 값과 매치되는 레코드들을 오른쪽 테이블(테이블이름2)에서 가져온다. -
왼쪽 테이블의 기준 필드 값과 매치되는 값이 오른쪽 테이블에 없으면 null 값을 가져온다
- RIGHT
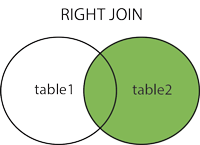
-
오른쪽 테이블(테이블이름2)에 있는 모든 레코드를 가져오고,
기준 필드의 값과 매치되는 레코드들을 왼쪽 테이블(테이블이름1)에서 가져온다. -
오른쪽 테이블의 기준 필드 값과 매치되는 값이 왼쪽 테이블에 없으면 null 값을 가져온다.
- FULL OUTER
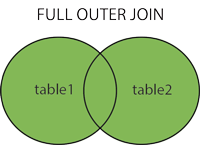
- 기준 필드의 값과 매치되는 레코드가 어느 한쪽 테이블에라도 있으면 해당 레코드를 해당 테이블에서 가져온다.
(주의! 결과 테이블이 매우 커질 수 있다.)
- Self JOIN
테이블을 자기 스스로와 결합시킨다.
SELECT 필드이름1, 필드이름2, ...
FROM 테이블이름 예명1, 테이블이름 예명2
WHERE 조건;
// Customers 테이블에서 City 필드의 값이 같은 레코드들을 가져온다.
SELECT A.CustomerName AS CustomerName1, B.CustomerName AS CustomerName2
FROM Customers A, Customers B
WHERE A.CustomerID <> B.CustomerID AND A.City=B.City
ORDER BY A.City;(5) UNION
- 기본 UNION
- 두 개 이상의 SELECT 문으로 얻어진 결과 테이블을 합칠 때 사용
- 조건
- 필드 개수 : UNION 이 적용되는 각각의 SELECT 문은 동일한 개수의 필드를 가져와야한다.
- 데이터 타입 : 필드들은 같은 데이터 타입을 가져야한다.
- 필드 순서 : 각각의 SELECT 문은 같은 순서로 필드들을 가져와야한다.
SELECT 필드이름1, 필드이름2, ...
FROM 테이블이름1
UNION
SELECT 필드이름1, 필드이름2, ...
FROM 테이블이름2;
/* Customers 테이블과 Suppliers 테이블의 모든 레코드를 합친 뒤,
Customers 테이블의 레코드는 Customer 를, Suppliers 테이블의 레코드는 Supplier 를 값으로 가지는
Type 필드와 ContactName, City, Country 필드를 가져와 결과 테이블을 구성 */
SELECT 'Supplier' AS type, ContactName, City, Country
FROM Suppliers
UNION
Select 'Customer', ContactName, City, Country
From Customers;- UNION ALL
UNION : 두 테이블을 합칠 때, 고유한 값만을 남긴다.
UNION ALL : 두 테이블을 합칠 때, 중복되는 값을 남긴다.
SELECT 필드이름1, 필드이름2, ...
FROM 테이블이름1
UNION ALL
SELECT 필드이름1, 필드이름2, ...
FROM 테이블이름2;
// Customers 과 Suppliers 테이블의 모든 레코드들의 City 필드 값을 보여준다.
SELECT City
FROM Customers
UNION ALL
SELECT City
FROM Suppliers(5) CASCADE
// STUDENT 테이블에서 s1 수강생을 삭제했을 때 EXAM에 있는 s1수강생의 시험성적과 MANAGER의 managerA가 관리하는 수강생 목록에 자동으로 삭제될 수 있도록 하세요.
// ALTER, DROP, MODIFY, CASCADE 를 사용하여 EXAM, MANAGER 테이블을 수정
//1. 이 코드를 먼저 실행시켜서, 기존에 설정된 CONSTRAINT를 drop한다
ALTER TABLE EXAM DROP CONSTRAINT exam_fk_student_code; //DROP: 테이블에서 기본 키, 외래 키 또는 검사 제약 조건을 삭제
//2. ON DELETE CASCADE를 건 CONSTRAINT를 설정
ALTER TABLE EXAM ADD CONSTRAINT exam_fk_student_code FOREIGN KEY(student_code) REFERENCES STUDENT(student_code) ON DELETE CASCADE;
ALTER TABLE MANAGER DROP CONSTRAINT manager_fk_student_code;
ALTER TABLE MANAGER ADD CONSTRAINT manager_fk_student_code FOREIGN KEY(student_code) REFERENCES STUDENT(student_code) ON DELETE CASCADE;
DELETE FROM STUDENT WHERE student_code = 's1'; //DELETE문을 실행하면, CASCADE를 걸어주지 않아서 constraint violation 오류 발생(= 연관된 데이터가 있어서 지울 수 없다!)
//CASCADE: 부모의 영속성 상태가 전이되는 것(부모 엔티티가 영속화될때 자식 엔티티도 같이 영속화되고, 부모 엔티티가 삭제 될때 자식 엔티티도 삭제되는 등...)
//CONSTRAINT: 제약조건
SELECT * FROM STUDENT; //확인해보면, s1수강생이 보이지 않음
SELECT * FROM EXAM WHERE STUDENT_CODE = 's1'; //연관된 데이터는 이제 보이지 않음
SELECT STUDENT_CODE FROM MANAGER WHERE NAME = 'managerA'; //s1 수강생 사라져서 이제 안 보임
//필요한 데이터를 이렇게 SQL을 매번 작성하지 않아도 됨 --> ORM에 의해 자동으로 SQL을 생성하여 데이터 조작이 가능해짐
//JPA: Spring에서 ORM을 구현해주는 기술CASCADE
FOREIGN KEY 로 연관된 데이터를 삭제,변경
참고: JPA (Java Persistence API) - 영속성 전이 (Cascade)
(6) WHERE
SELECT 필드이름1, 필드이름2 ...
FROM 테이블이름
WHERE 조건;
SELECT *
FROM Customers
WHERE Country='Mexico';WHERE 은 SELECT 뿐만 아니라 다른 명령어에도 사용 가능
① AND / OR / NOT
// AND
SELECT 필드이름1, 필드이름2, ...
FROM 테이블이름
WHERE 조건1 AND 조건2 AND 조건3 ...;
SELECT *
FROM Customers
WHERE Country='Germany' AND City='Berlin';
// OR
SELECT 필드이름1, 필드이름2, ...
FROM 테이블이름
WHERE 조건1 OR 조건2 OR 조건3 ...;
// NOT
SELECT *
FROM Customers
WHERE NOT Country='Mexico';
// AND / OR / NOT 모두 섞어 사용한 경우
// Customers 테이블에서 City 가 London 이거나, Country 가 Mexico 이면서 PostalCode 가 05021 이 아닌 레코드들을 모두 가져온다.
SELECT *
FROM Customers
WHERE City='London' OR (Country='Mexico' AND NOT PostalCode='05021');AND
AND 로 구분된 여러개의 조건이 모두 참인 데이터를 가져온다.
OR
OR 로 구분된 여러개의 조건 中 최소 하나 이상이 참인 데이터를 가져온다.
NOT
주어진 조건에 일치하지 않는 레코드를 가져온다.
② LIKE
SELECT 필드이름1, 필드이름2, ...
FROM 테이블이름
WHERE 필드이름 LIKE 패턴;
// Customers 테이블에서 CustomerName 필드가 "a" 로 시작하는 레코드를 모두 찾는다.
SELECT *
FROM Customers
WHERE CustomerName LIKE 'a%';
WHERE CustomerName LIKE '%a' // "a" 로 끝나는 값을 찾음
WHERE CustomerName LIKE '%or%' // "or" 이 포함된 값을 찾음
WHERE CustomerName LIKE '_r%' // 두번째 글자가 "r" 인 값을 찾음
WHERE CustomerName LIKE 'a_%_%' // "a" 로 시작하는 세글자 이상의 값을 찾음
WHERE ContactName LIKE 'a%o' // "a" 로 시작하고 "o" 로 끝나는 값을 찾음
WHERE ContactName LIKE '[bsp]%' // "b", "s", "p" 중 하나로 시작하는 값을 찾음
WHERE ContactName LIKE '%[!a-c]' // "a", "b", "c" 중 하나로 끝나지 않는 값을 찾음LIKE 는 2가지 와일드카드 를 사용
%
없거나, 하나 또는 여러개의 문자열
_
문자열 하나
③ IN
// 값을 직접 입력할 경우
SELECT 필드이름1, 필드이름2, ...
FROM 테이블이름
WHERE 필드이름 IN (값1, 값2, ...);
// 값을 다른 SELECT 문의 결과 테이블에서 가져올 수도 있다.
SELECT 필드이름1, 필드이름2, ...
FROM 테이블이름
WHERE 필드이름 IN (SELECT문);
SELECT * FROM Customers
WHERE Country IN ('Germany', 'Sweden', 'UK');IN
WHERE 의 조건에 여러개의 값을 특정할 때 사용
= 여러개의 OR 을 사용하는 것과 같다.
④ BETWEEN
SELECT 필드이름1, 필드이름2, ...
FROM 테이블이름
WHERE 필드이름 BETWEEN 시작범위 AND 끝범위;
SELECT *
FROM Products
WHERE Price BETWEEN 10 AND 20;
// Products 테이블의 ProductName 필드를 기준으로 오름차순 정렬하였을 때 ProductName 필드 값이 Chang 인 레코드와 Chef Anton's Cajun Seasoning 인 레코드 사이의 레코드를 모두 가져온다.
SELECT *
FROM Products
WHERE ProductName BETWEEN "Chang" AND "Chef Anton's Cajun Seasoning"
ORDER BY ProductName;BETWEEN
주어진 범위 내의 값을 찾아 가져온다.
(범위 : 문자열, 숫자, 날짜 형태로 주어질 수 있다. → 범위의 시작값과 끝값을 검색에 포함한다.)
⑤ EXISTS
SELECT 필드이름1, 필드이름2, ...
FROM 테이블이름
WHERE EXISTS
(SELECT 필드이름1, 필드이름2, ... FROM 테이블이름 WHERE 조건); # 서브쿼리
// Suppliers 테이블의 SupplierID 필드의 값과 같은 값을 가지면서 Price 필드 값이 22 이하인 Products 테이블의 레코드가 있으면 TURE 를 리턴하고, 해당 레코드의 SupplierID 와 같은 값을 가지는 Suppliers 테이블의 레코드의 SupplierName 필드 값을 가져온다.
쉽게 말해서 가격이 22 이하인 제품을 제공하는 제공자 목록을 가져오는 것이다.
SELECT SupplierName
FROM Suppliers
WHERE EXISTS
(SELECT ProductName
FROM Products
WHERE SupplierID=Suppliers.SupplierID AND Price > 22);EXISTS
서브쿼리(SELECT문)의 결과 테이블에 레코드가 있는지 없는지를 테스트할 때 사용
→ 서브쿼리가 조건에 맞는 레코드를 하나 이상 가져올 경우 TRUE 를, 아닌 경우 FALSE 를 리턴
참고: [DB 이론] SQL이란?
참고: SQL이란?
참고: 11. SQL이란 무엇인가
참고: [SQL] DBMS와 SQL이란
참고: undefined / ORM, sql vs no sql
참고: SQL이란 무엇일까
참고: [SQL] SELECT
참고: [SQL] WHERE
참고: [SQL] SELECT를 꾸며주는 옵션 모음
참고: [SQL] INSERT INTO
참고: [SQL] UPDATE
참고: [SQL] DELETE
참고: [SQL] JOIN, UNION
