앙상블이란
앙상블(Ensemble)은 분류(Classification)를 위한 ML 모델을 만들 때 여러 개의 작은 모델들을 만들고 이들을 더해서 성능을 높이는 방법입니다.
보통 모델을 학습하다보면 모델이 오버피팅되거나 언더피팅되는 경우가 있습니다.
이는 분류 문제에서 너무 과하게 학습용 데이터에 최적화되어 생기는 문제입니다.
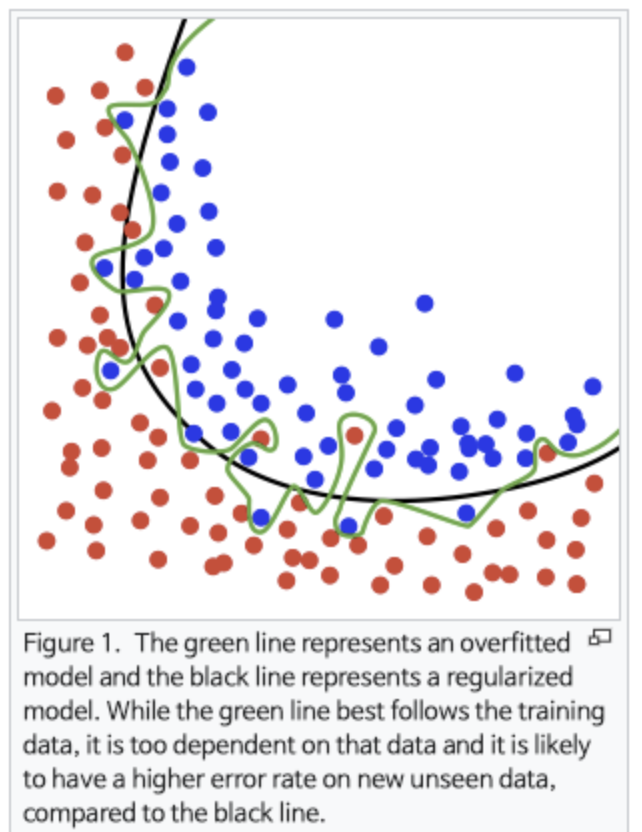
이러한 경우 여러 모델을 조합하는 앙상블을 통해 해결할 수 있습니다.
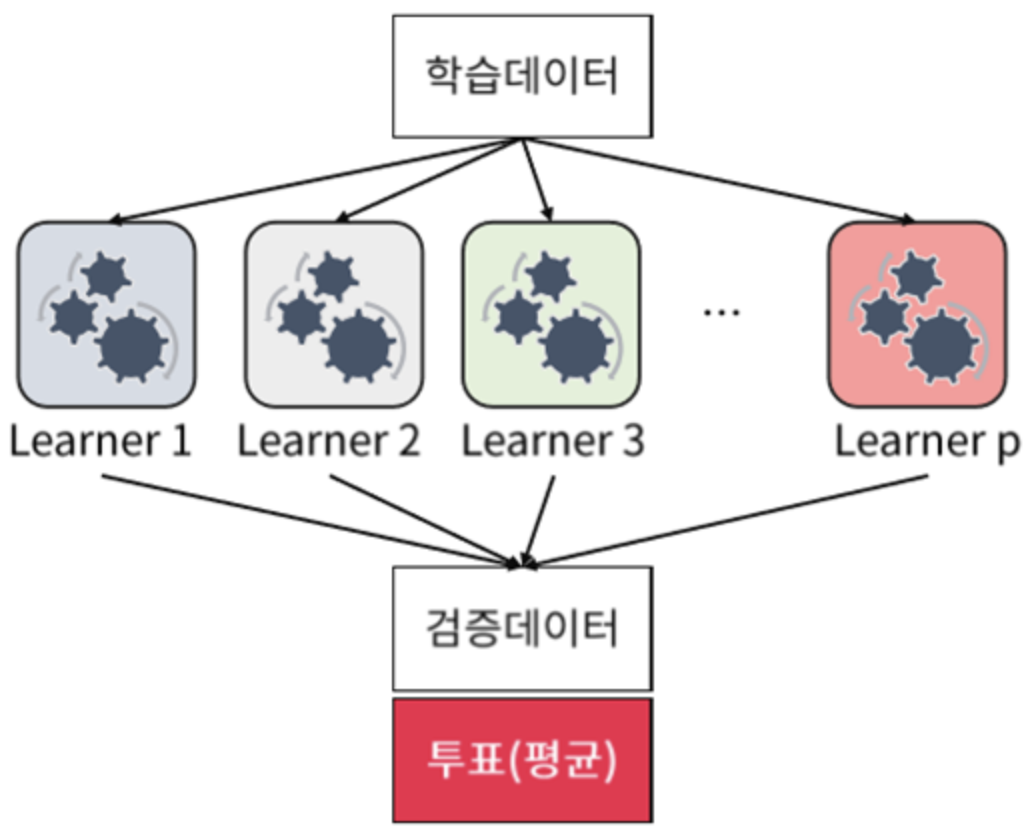
여러 개의 분류기를 결합하여 보다 정확한 성능의 모델을 만드는 것입니다.
기본 앙상블 방법
앙상블의 유형은 전통적으로 보팅(Voting), 배깅(Bagging), 부스팅(Boosting)의 세 가지로 나눌 수 있으며, 이외에도 스태킹을 포함한 다양한 기법들이 있습니다.
1. Voting
Voting은 서로 다른 알고리즘을 가진 분류기 결합으로 다른 ML 알고리즘이 같은 데이터 세트에 대해 학습하고 예측한 결과를 가지고 보팅을 통해 최종 예측 결과 선정
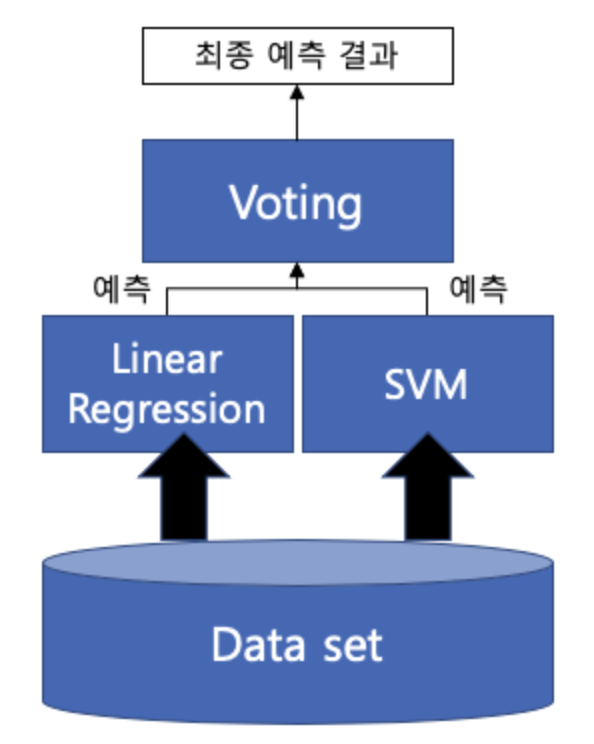
Voting 종류
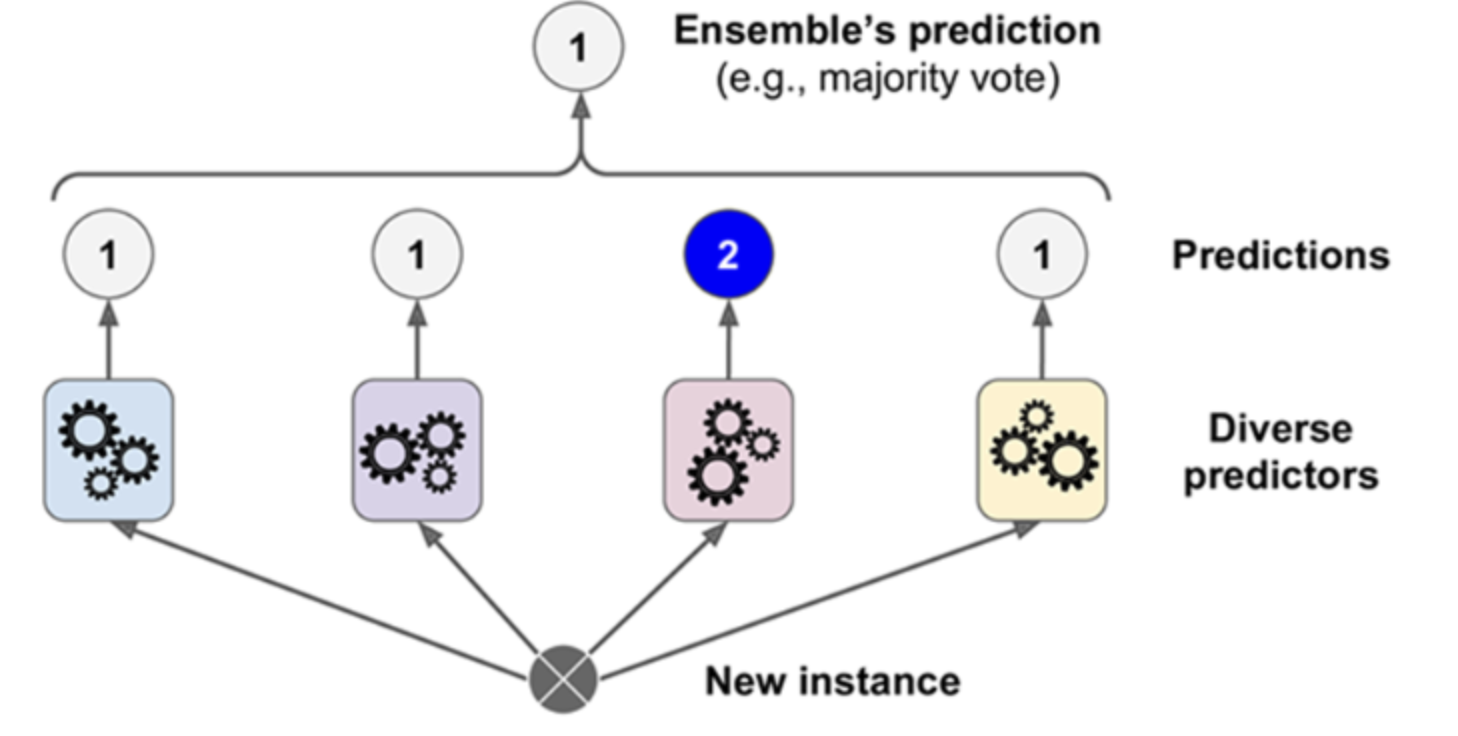
1) 하드 보팅
쉽게 말해 다수결 원칙이다.
예측한 결과값들 중 다수의 분류기가 결정한 예측값을 최종 보팅 결과값으로 선정
2) 소프트 보팅
분류기들의 레이블 값 결정 확률을 모두 더하고 이를 평균해서 이들 중 확률이 가장 높은 레이블 값을 최종 보팅 결과값으로 선정
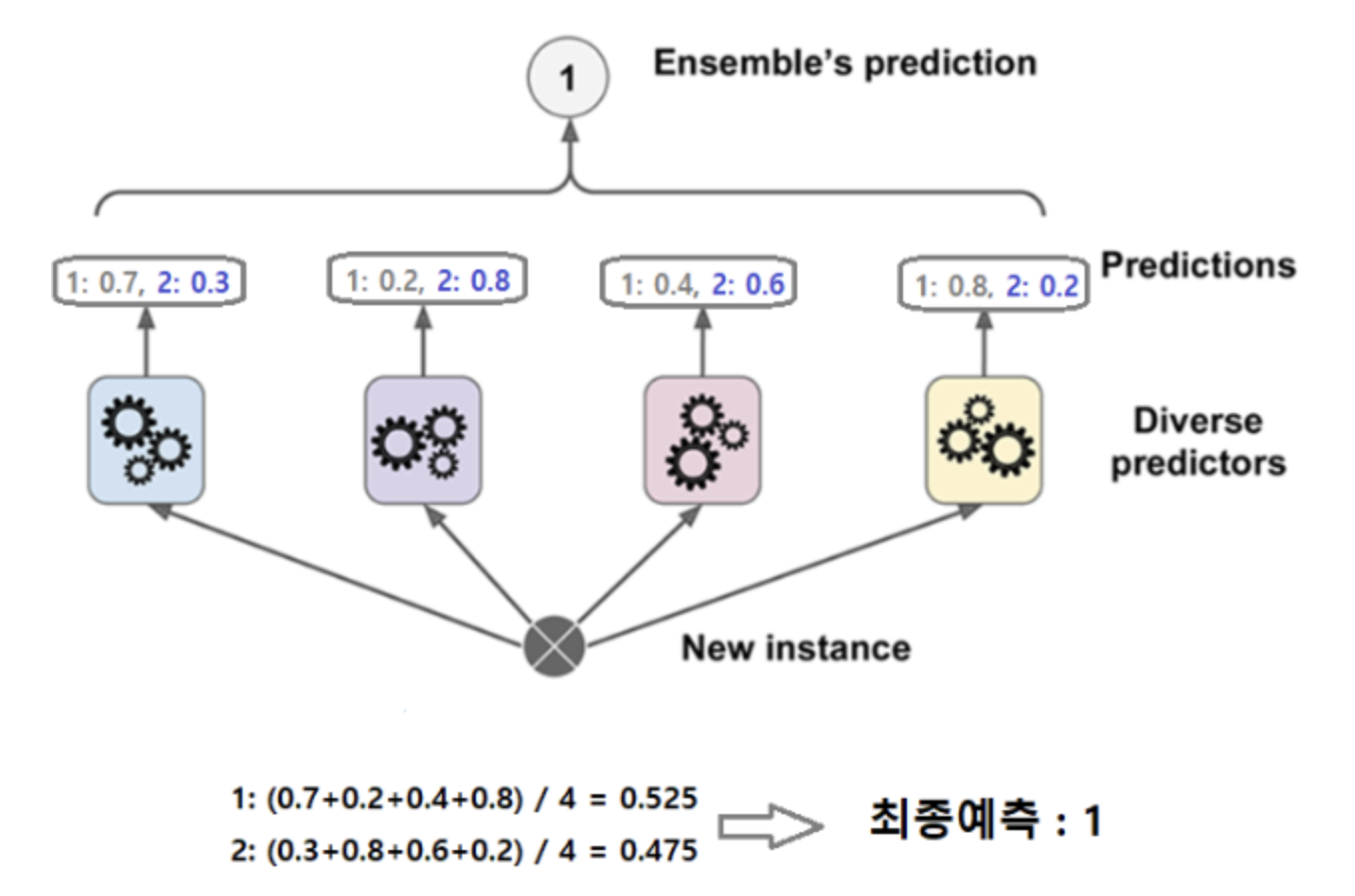
일반적으로 하드 보팅보다는 소프트 보팅이 예측 성능이 좋아서 더 많이 사용됩니다.
매개 변수
- estimators: 앙상블할 모델들 설정, 튜플의 리스트로 묶어서 전달
- votion: voting 방식 (hard / soft)
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
# 각각의 모델
log_clf = LogisticRegression(solver = 'liblinear')
rnd_clf = RandomForestClassifier(n_estimators=10)
svm_clf = SVC(gamma='auto')
# 모델들을 튜플 리스트에 넣고 voting 기 생성 (hard보팅, default: soft)
voting_clf = VotingClassifier(estimators=[('lr',log_clf),
('rf',rnd_clf),
('svc',svm_clf)],
voting='hard')
voting_clf.fit(X_train, y_train)
# 평가
from sklearn.metrics import accuracy_score
for clf in (log_clf, rnd_clf, svm_clf, voting_clf):
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(clf.__class__.__name__, accuracy_score(y_test,y_pred))LogisticRegression 0.864
RandomForestClassifier 0.888
SVC 0.888
VotingClassifier 0.896
결과, 투표기반 앙상블 분류기(VotingClassifier)가 다른 개별 분류기보다 성능이 조금 더 높다.
2. Bagging
Bagging은 앞서 배운 voting과 달리 각각의 분류기가 모두 같은 유형의 알고리즘 기반이지만, 데이터 샘플링을 서로 다르게 가져가면서 학습을 수행해 Voting을 수행하는 것입니다.. (대표적인 Bagging: Random Forest)
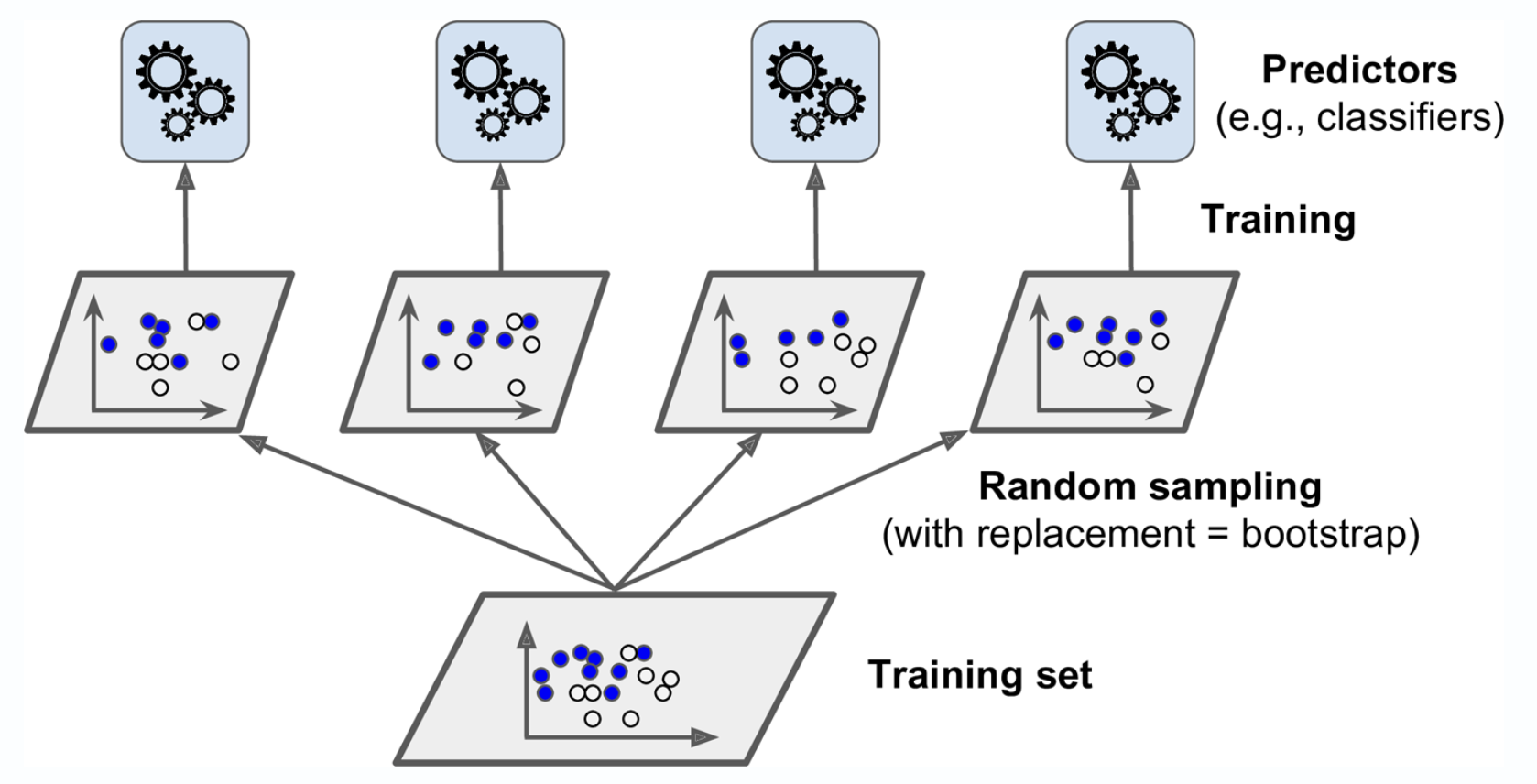
위 그림처럼 모든 예측기들이 훈련을 마치면 앙상블은 예측을 모야 새로운 샘플레 대한 예측을 만듭니다.
데이터 샘플링을 만드는 방식에서 중복을 허용하면 "배깅" 중복을 허용하지 않으묜 "페이스팅"이라고 합니다.
- 분류 : 통계값 최빈값
- 회귀 : 평균
개별 예측기들은 원본 train set으로 훈련시킨 것보다 훨씬 편향되어 있지만, 수집함수를 통과하면 편향과 분산이 모두 감소하게됩니다.
사이킷런은 배깅을 위해 BaggingClassifier, BaggingRegressor를 제공합니다.
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 결정트리 분류기 500개의 앙상블 훈련
bag_clf = BaggingClassifier(DecisionTreeClassifier(),
n_estimators=500,
max_samples=100,
bootstrap=True,
n_jobs=-1)
bag_clf.fit(X_train, y_train)
y_pred = bag_clf.predict(X_test)
print(bag_clf.__class__.__name__,accuracy_score(y_test, y_pred))
# 결정트리 분류기 1개 학습
tree_clf = DecisionTreeClassifier(random_state=42)
tree_clf.fit(X_train, y_train)
y_pred_tree = tree_clf.predict(X_test)
print(tree_clf.__class__.__name__,accuracy_score(y_test, y_pred_tree))BaggingClassifier 0.912
DecisionTreeClassifier 0.856
매개변수
- n_estimator : 앙상블에 사용할 분류기의 수
- max_sample : 무작위로 뽑을 샘플의 수(0~1사이의 수로 지정하면 비율이 되어, 훈련세트에 곱한 값만큼 샘플링)
- boot_strap : True(중복허용, 배깅), False(중복허용 X, 페이스팅)
- n_jobs : 사용할 CPU 수(-1로 지정하면 가용한 모든코어 사용)
BaggingClassifier는 분류기들이 결정트리처럼 범주에 속할 확률(predict_proba)을 추정할 수 있으면 자동으로 간접 투표 방식을 사용합니다.
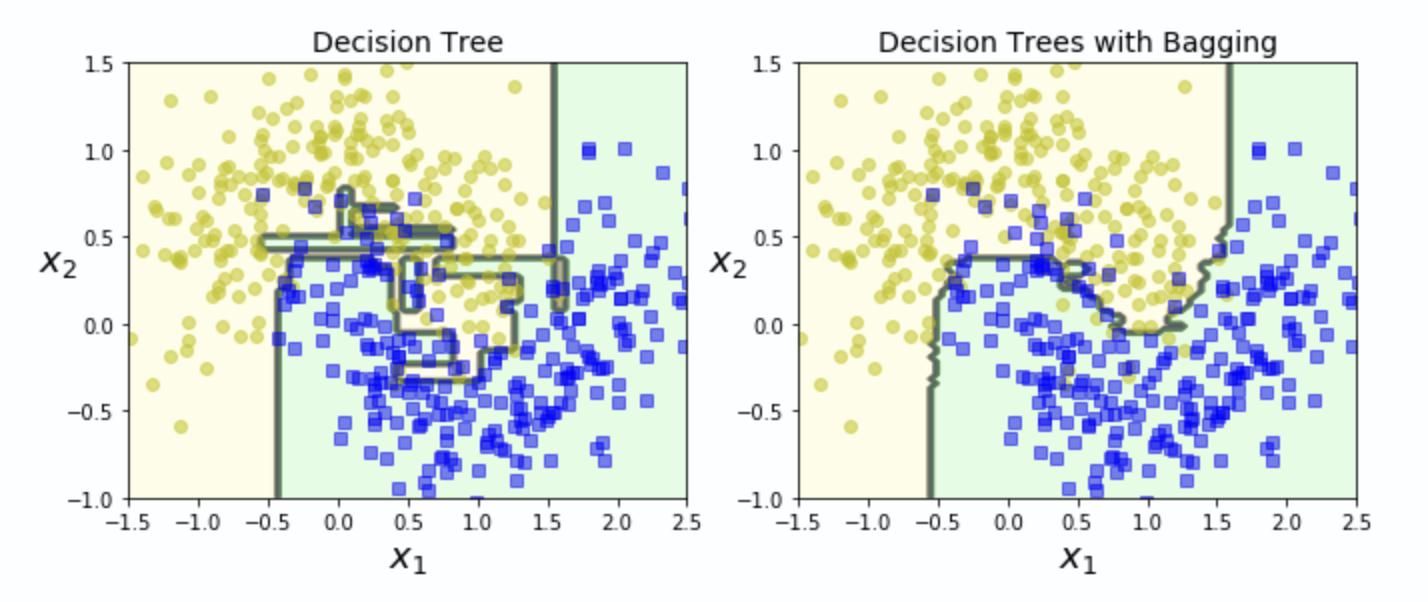
시각적으로 두 분류기(앙상블, 결정트리)의 결정경계를 비교해보면 앙상블의 예측이 더 일반화가 잘 이루어짐을 알 수 있습니다.
부트스트래핑(중복을 허용한 샘플링)은 각 예측기가 학습하는 서브셋에 다양성을 증가시키므로 배깅이 페이스팅보다 편향이 조금더 높지만 이는 예측기간의 상관관계를 줄여 앙상블의 분산을 감소시킵니다.
3. Boosting
여러 개의 분류기가 순차적으로 학습을 수행하되, 앞에서 학습한 분류기가 예측이 틀린 데이터에 대해서 올바르게 예측할 수 있도록 다음 분류기에게 가중치(weight)를 부여하면서 학습과 예측 진행
예측 성능이 뛰어나 앙상블 학습을 주도
대표적인 Boosting 모듈: Gradient Boost, XGBoost(eXtra Gradient Boost), LightGBM(Light Gradient Boost)
Bootstrapping
1) 데이터 샘플링
Bootstrapping 분할 방식은 개별 분류기에서 데이터를 샘플링해서 추출하는 방식으로 여러 개의 데이터 세트를 중첩되게 분리하는 것입니다.
교차 검증이 데이터 세트간의 중첩을 허용하지 않는 것과 달리 Bagging은 중첩을 허용합니다. (복원 추출)
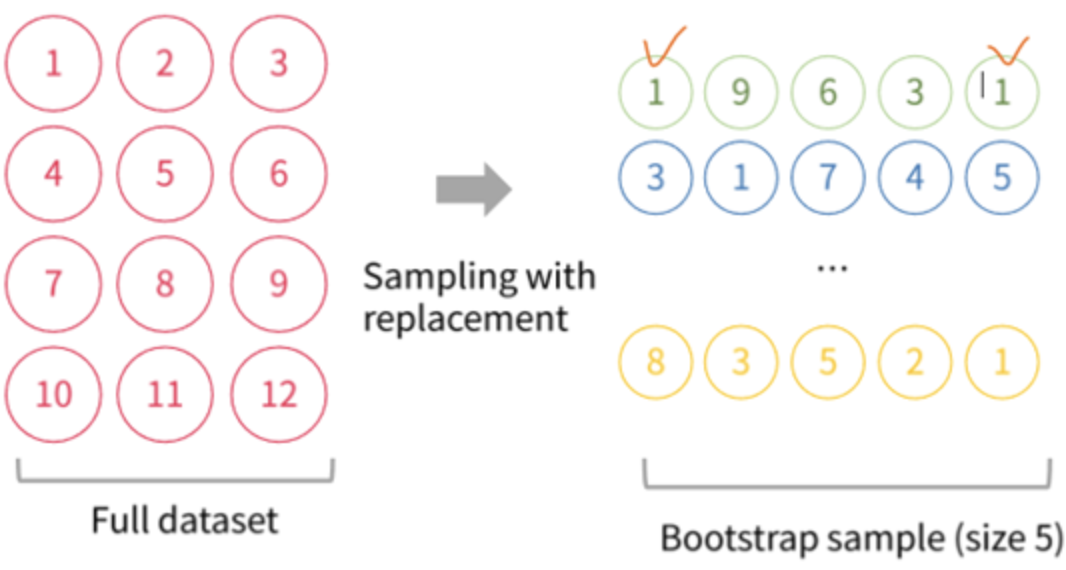
2) 지정한 사이즈만큼 Bootstrap을 실행 하고 나온 여러 개의 데이터 셋으로 예측한 결과의 평균을 예측 결과 도출해냅니다.
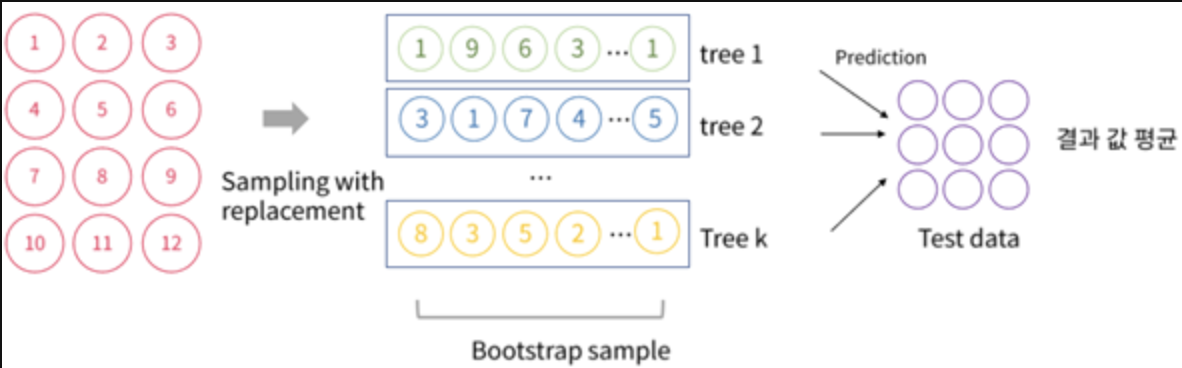
3) 각 분류기 개수만큼 데이터 샘플링을 하고 그 개별 예측을 평균(보팅)하여 최종 예측 결과 선정
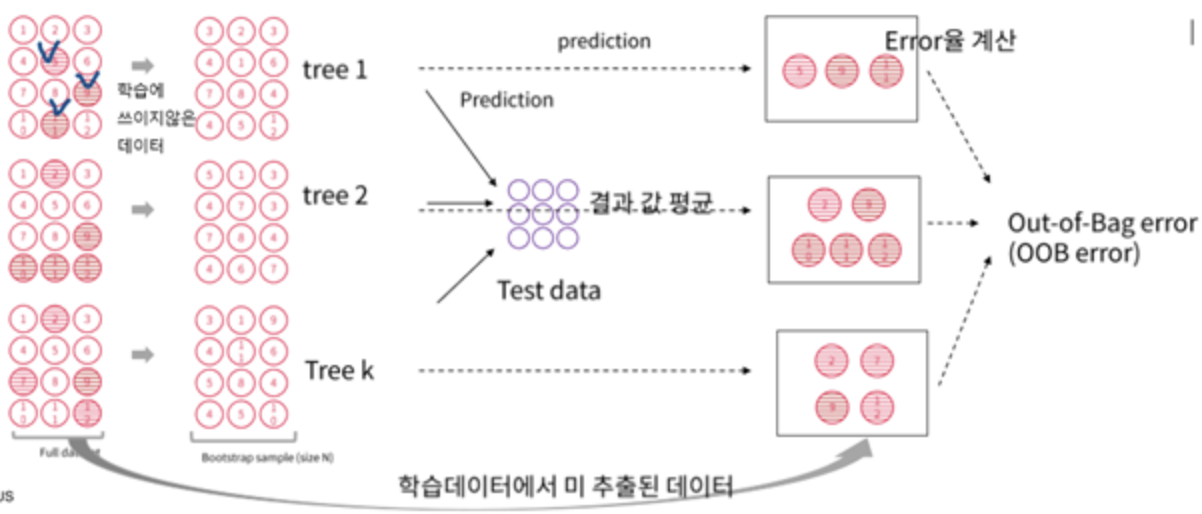
OOB
샘플링을 하다보면 어떤 샘플은 여러번 샘플링되고 어떤 것은 전혀 사용되지 않을 수도 있습ㄴ디ㅏ.
예측기가 훈련되는 동안 이 oob샘플을 사용하지 않으므로 모델은 해당 샘플을 전혀모릅니다.
즉 이 oob 데이터를 사용해서 검증 세트나 교차검증을 사용하지 않고 이를 이용해 평가에 사용할 수 있는 것이죠!.
궁극적으로 앙상블의 평가는 각 예측기의 oob평가를 평균하여 얻습니다.
사이킷런에서 BaggingClassifier의 oob_score=True로 지정하면 훈련을 마치고 oob평가를 수행합니다.
bag_clf = BaggingClassifier(DecisionTreeClassifier(),
n_estimators=500,
bootstrap=True,
n_jobs=-1,
oob_score=True)
bag_clf.fit(X_train, y_train)
bag_clf.oob_score_ # 500개 결정트리 분류기의 oob점수를 평균한 값0.9013333333333333
이는 테스트 데이터셋을 사용하지 않고 훈련데이터에서 사용되지 않은 것을 이용한 것으로, 실제 테스트 데이터셋의 결과와 비교시 비슷한 정확도를 보입니다.
from sklearn.metrics import accuracy_score
y_pred = bag_clf.predict(X_test)
accuracy_score(y_test, y_pred)0.904
oob평가를 통해 얻은 결정 함수의 값(범주에 속할 확률)은 oobdecision_function에서 확인할 수 있습니다.
bag_clf.oob_decision_function_[:10]첫 번째 훈련 샘플이 양성 범주에 속할 확률을 64.06%, 음성 범주에 속할 확률을 35.93%로 추정
array([[0.359375 , 0.640625 ],
[0.32941176, 0.67058824],
[1. , 0. ],
[0. , 1. ],
[0. , 1. ],
[0.08994709, 0.91005291],
[0.35384615, 0.64615385],
[0.02162162, 0.97837838],
[0.98823529, 0.01176471],
[0.97354497, 0.02645503]])
Bagging vs Tree
- Tree
쉽고 직관적인 분류 기준을 가지고 있지만, Low Bias(정답과 예측값의 거리), High Variance(모델별 예측값 간의 거리) => overfitting 발생- Bagging
위와 같은 문제를 해결하기 위해 모델, 예측한 값의 평균을 사용하여 bias를 유지하고 Variance를 감소, 학습데이터의 noise에 강건해짐, 모형해석의 어려움(단점)
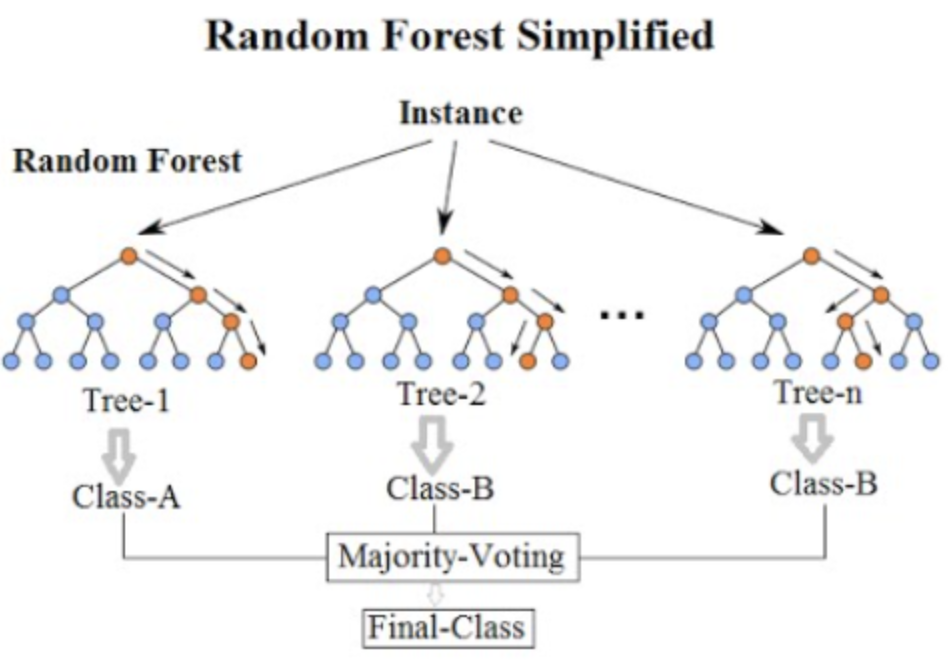
Random Forest
랜덤 포레스트는 Bagging의 대표적인 알고리즘입니다.
여러 개의 결정 트리 분류기가 전체 데이터에서 bagging 방식으로 각자의 데이터를 샘플링합니다.
그리고 개별적으로 학습 수행 후 최종적으로 모든 분류기가 voting을 통해 예측 결정하게됩니다.
랜덤포레스트는 트리의 노드를 분할할 때 전체 변수 중에서 최선의 변수를 찾는 대신, 무작위로 선택한 변수 후보 중에서 최적의 변수를 찾는 식으로 무작위성을 더 주입한 형식입니다.
이는 결국 트리를 더욱 다양하게 만들고 편향을 손해 보는 대신 분산을 낮추어 전체적으로 더 훌륭한 모델을 만든다.
Bagging Model의 분산은 각 트리들의 분산과 그들의 공분산으로 이루어져있습니다.

즉, 공분산이 0이면 두 변수는 독립적인 것이고, 모델의 분산을 줄여 일반적으로 Bagging보다 성능이 좋습니다. 또한 랜덤 포레스트의 Subset 데이터는 Bootstrapping 방식으로 데이터가 임의로 만들어지며
Random Forest는 기본 Bagging과 다르게 데이터뿐만 아니라, 변수도 random하게 뽑아서 다양한 모델 만들어냅니다.
장점:
1. 앙상블 알고리즘 중 비교적 빠른 수행 속도를 가지고 있음
2. 다양한 영역에서 높은 예측 성능
3. 결정 트리의 쉽고 직관적인 장점 그대로 가지고 있음
단점:
1. 하이퍼 파라미터가 너무 많다
2. 시간이 많이 소모된다
3. 예측 성능이 크게 향상되는 경우가 많지 않다
트리 기반 자체의 하이퍼 파라미터가 원래 많고, 배깅, 부스팅, 학습, 정규화를 위한 하이퍼 파라미터까지 추가되므로 많을 수 밖에 없습니다...
from sklearn.ensemble import RandomForestClassifier
rnd_clf = RandomForestClassifier(n_estimators=500, max_leaf_nodes=16, n_jobs=-1)
rnd_clf.fit(X_train, y_train)
y_pred_rf = rnd_clf.predict(X_test)파라미터 종류
- n_estimators: 결정 트리의 개수 지정
- max_features: 결정트리에 max_features 파라미터와 같음(최적의 분할을 위해 고려할 최대 피처갯수). 기본이 sqrt(전체 피처갯수)
- max_depth(트리의 최대 깊이 규정)
- min_samples_leaf(말단 노드가 되기 위한 최소한의 샘플 데이터 수): 과적합 개선
앞에서 언급했듯이 랜덤 포레스트의 핵심은 트리를 더욱 무작위하게 만들기 위해, 일반적인 결정트리모델처럼 최적의 임계값을 찾는 대신 후보 변수를 사용해 무작위로 분할해 그 중 최상의 분할을 선택하는 것입니다.
이러한 원리를 더 극단적으로 사용한 것을 익스트림 랜덤트리 앙상블, 줄여서 엑스트라 트리(Extra-Trees) 라고 부른다.
사이킷런에서는 이 두가지 모델을 모두 제공한다.
ExtraTreesClassifier와 RandomForesetClassifier이며 Regressor도 같은 API를 제공한다
변수의 중요도
랜덤포레스트의 또 다른 장점 중 하나가 변수의 상대적 중요도를 측정할 수 있다는 것이다.
어떤 변수를 사용한 노드가 (전체 트리에 대해)평균적으로 불순도를 얼마나 감소시키는지 확인하여 중요도를 측정한다.
이는 결국 가중치평균이며 각 노드의 가중치는 연관된 훈련 샘플 수와 같다.
중요도 = (현재 노드의 샘플 비율 X 불순도) - (왼쪽 자식 노드의 샘플 비율 X 불순도) - (오른쪽 자식노드의 샘플 비율 X 불순도)
전체 중요도의 합으로 나누어 정규화
여기서 샘필 비율이란, 전체 샘플 수에 대한 해당 노드의 샘플 수
마지막으로 랜덤포레스트의 변수 중요도는, 각 결정트리의 변수 중요도의 합 / 트리 수 이다.
사이킷런은 훈련 후 변수마다 자동으로 이 중요도를 계산하고 전체 합이 1이 되도록 정규화를 한다.
이는 featureimportances에 저장되어 있습니다.
from sklearn.datasets import load_iris
iris = load_iris()
rnd_clf = RandomForestClassifier(n_estimators=500,n_jobs=-1)
rnd_clf.fit(iris["data"], iris["target"])
for name, score in zip(iris["feature_names"], rnd_clf.feature_importances_):
print(name, score)sepal length (cm) 0.09193700831457226
sepal width (cm) 0.02303133424063586
petal length (cm) 0.4503310122507622
petal width (cm) 0.43470064519402973
GBM
부스팅 알고리즘을 적용한 모델로 순차적으로 학습-예측하면서 잘못 예측한 데이터에 가중치 부여를 하고, 오류를 개선해 나가면서 학습하는 방식입니다.
GBM은 가중치 업데이트를 경사하강법을 사용하는 것이 큰 특징입니다.
즉, 손실함수를 최소화하는 방향성을 가지고 가중치를 업데이트하는 것입니다.
보통 GBM이 랜덤 포레스트 보다는 예측 성능이 뛰어나지만 수행시간 문제는 GBM이 극복해야할 중요한 과제 중 하나입니다...
파라미터 종류
- n_estimators: 결정트리갯수/ max_depth:. Max_features: 위와 같이
- loss: 경사 하강법에서 사용할 비용 함수 지정
- learning_rate: weak learner가 순차적으로 오류값을 보정해 나가는데 적용하는 계수. 범위는 0과 1사이 , 기본값은 0.1, 너무 작은 값: 예측성능은 높아지지만 속도 느림. 너무 큰 값: 예측성능이 떨어지지만 속도는 빠름/
- subsample: 학 습에 사용하는 데이터 샘플링 비율 (ex. 0.5 면 학습데이터 50%)
장점:
과적합에도 강한 뛰어난 예측 성능을 가진 알고리즘
단점:
수행시간이 오래걸림
source
모든 소스코드는 해당 git 에 있습니다.
