Ensemble 1편에서는 기본적인 Ensemble에 대해서 배워보았습니다.
이번 포스팅에서는 좀 더 심화된 Ensemble을 알아봅시다.
XGBoost
'XGBoost (Extreme Gradient Boosting)' 는 앙상블의 부스팅 기법의 한 종류입니다.
이전 모델의 오류를 순차적으로 보완해나가는 방식으로 모델을 형성하는데,
이전 모델에서의 실제값과 예측값의 오차(loss)를 훈련데이터 투입하고 gradient를 이용하여 오류를 보완하는 방식을 사용합니다.
from xgboost import XGBClassifier
# 객체 생성
model = XGBClassifier(파라미터들)
xgb_model = model.fit(x_train, y_train, early_stopping_rounds=100,
eval_metric='logloss',eval_set=[(X_val, y_val)])
# 예측하기
y_pre = xgb_model.predict(X_test)
y_pred_probs = xgb_model.predict_proba(X_test)[:,1]
# 특성 중요도 시각화
fig, ax = plt.subplots(figsize=(10,12))
plot_importance(xgb_model, ax=ax)XGBoost 장점
- 강력한 병렬 처리로 학습과 처리가 빠름
(Gradient Boosting Model 대비 빠른 것) - Greedy-algorithm을 이용, 자동 가지치기(Pruning)가 가능
과적합(Overfitting) 방지 - 자체 교차검증 알고리즘 탑재
- 결측치 자체 처리
- Early Stopping
100번으로 설정 시 100번 동안 성능이 좋아지지 않는다면 그 전에 생성된 최고로 좋은 모델을 선택 - CART (Classification And Regression Tree)기반으로 분류, 회귀 둘다 구현
XGB 파라미터
- n_estimatiors : 트리의 갯수, 높을 수록 정확도가 높아지나 시간이 오래 걸린다. (int)
- n_jobs : 병렬처리 여부, -1을 입력하면 컴퓨터에 존재하는 모든 코어를 사용한다.
- random_state : 결과를 고정시킴, Seed Number와 같은 개념 (int)
- max_depth : 생성할 DecisionTree의 깊이 (int)
가지치기를 적용할 수 있는 파라미터- learning_rate : 훈련양, 학습할 때 모델을 얼마나 업데이트 할 것인지 (float)
- colsample_bytree : 열 샘플링에 사용하는 비율 (float)
- subsample : 행 샘플링에 사용하는 비율 (float)
- reg_alpha : L1 정규화 계수 (float)
- reg_lambda : L2 정규화 계수 (float)
- booster : 부스팅 방법, 주로 gbtree를 이용
L1, L2에 대한 개념은 여기에 잘 정리해두었으니 참고해주세요.
LightGBM
XGBoost는 GBM보다는 빠르지만 여전히 학습시간이 오래 걸리고, 대용량 데이터로 학습 성능을 기대하려면 높은 병렬도로 학습을 진행해야 합니다... ㅠ
LightGBM의 장점
XGBoost보다 학습에 걸리는 시간이 훨씬 적다.
메모리 사용량도 상대적으로 적다.
XGBoost와 마찬가지로 대용량 데이터에 대한 뛰어난 성능 및 병렬컴퓨팅 기능을 제공하고 최근에는 추가로GPU까지 지원한다.
LightGBM의 강력한 특징은 "카테고리형 피쳐의 자동 변환이 가능하고 최적 분할이 된다"는 것이다.
범주형을 원핫 인코딩과 같은 수치형 변수 변환 과정을 거치지 않고 범주형 변수를 최적으로 변환하고 이에 따른 노드 분할 수행이 이루어진다는 것이다.
알겠지만 머신러닝은 문자열을 입력값으로 받지 않습니다. 따라서 문자열의 피쳐는 벡터화 등의 기법으로 벡터화하는 데 범주형 피쳐의 종류가 너무 많게되면... 어떻게 인코딩해야하나... 싶은데요.
이럴 때, LightGBM을 유용하게 사용할 수 있습니다.
LightGBM의 단점
적은(10,000건 이하)의 데이터 셋에 적용할 경우 과적합 발생 쉽다.
기존 GBM과의 차이점
기존의 트리 기반 알고리즘 : 균형트리 분할(Level Wise) 방식 사용
→ 오버피팅에 더 강하지만 균형을 맞추기 위한 시간이 필요하다.
LightGBM : 리프 중심 트리 분할(Leaf Wise) 방식 사용
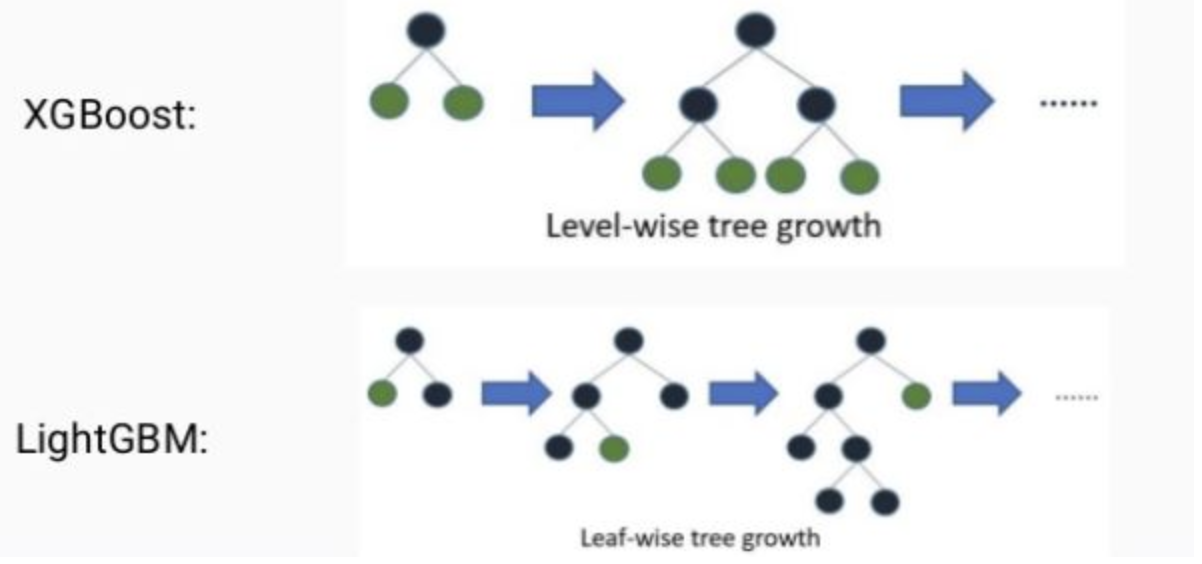
→ 트리의 균형을 맞추지 않고 최대 손실값(max delta loss)를 가지는 리프 노드를 지속적으로 분할하며 트리 깊이 확장하면서 트리의 깊이가 깊어지고 비대칭적 규칙 트리 생성한다.
→ 학습을 반복할 수록 균형트리분할방식보다 예측 오류 손실을 최소화할 수 있다.
Stacking
개별적인 여러 알고리즘 서로 결합해 예측 결과를 도출합니다. (배깅, 부스팅과 동일)
하지만 개별 알고리즘으로 예측한 데이터를 기반으로 다시 예측을 수행한다는 점에서 차이가 있습니다.
즉, 개별 알고리즘의 예측 결과 데이터세트를 최종적인 메타 데이터 세트로 만들어 별도의 ML 알고리즘으로 최종 학습을 수행하고, 다시 테스트 데이터를 기반으로 다시 최종 예측을 하는 방식입니다.
메타 모델
개별 모델의 예측된 데이터 세트를 다시 기반으로 학습하고 예측하는 방식
주로 캐글과 같은 대회에서 높은 순위를 차지하기 위해 조금이라도 성능 높여야할 떄 자주 사용된다고 합니다.
하지만 스태킹한다고 늘 성능이 향상되는 보장은 없습니다...
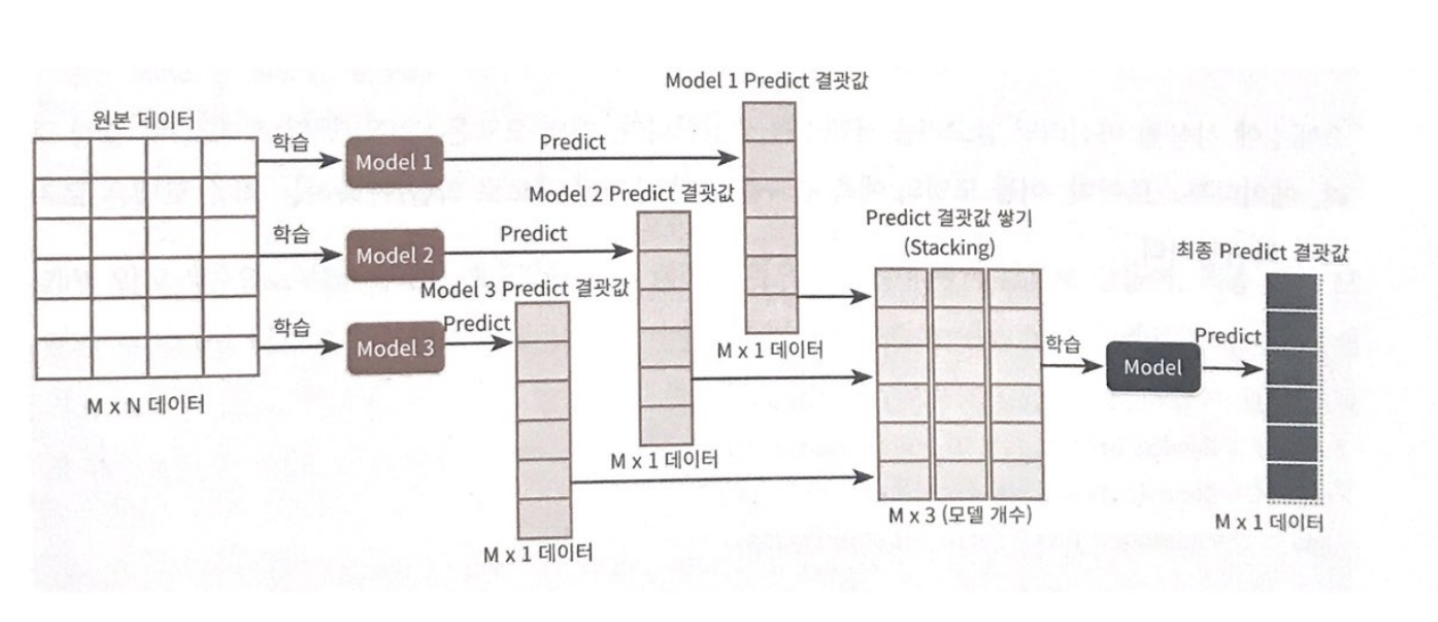
스태킹 앙상블 순서
모델별로 각각 학습 시킨 뒤 예측을 수행하면 각각 M개의 로우를 가진 1개의 레이블 값을 도출
-> 모델별로 도출된 예측 레이블 값을 다시 합해서(스태킹) 새로운 데이터 세트를 만듦
-> 스태킹 된 데이터 세트에 대해 최종 모델을 적용해 최종 예측
핵심은 "개별 모델이 예측한 학습 데이터의 예측값과 평가 데이터의 예측값을 합쳐 그것으로 training set을 만들어 메타 모델을 학습"시킨다 이빈다.
스태킹 학습 전체도
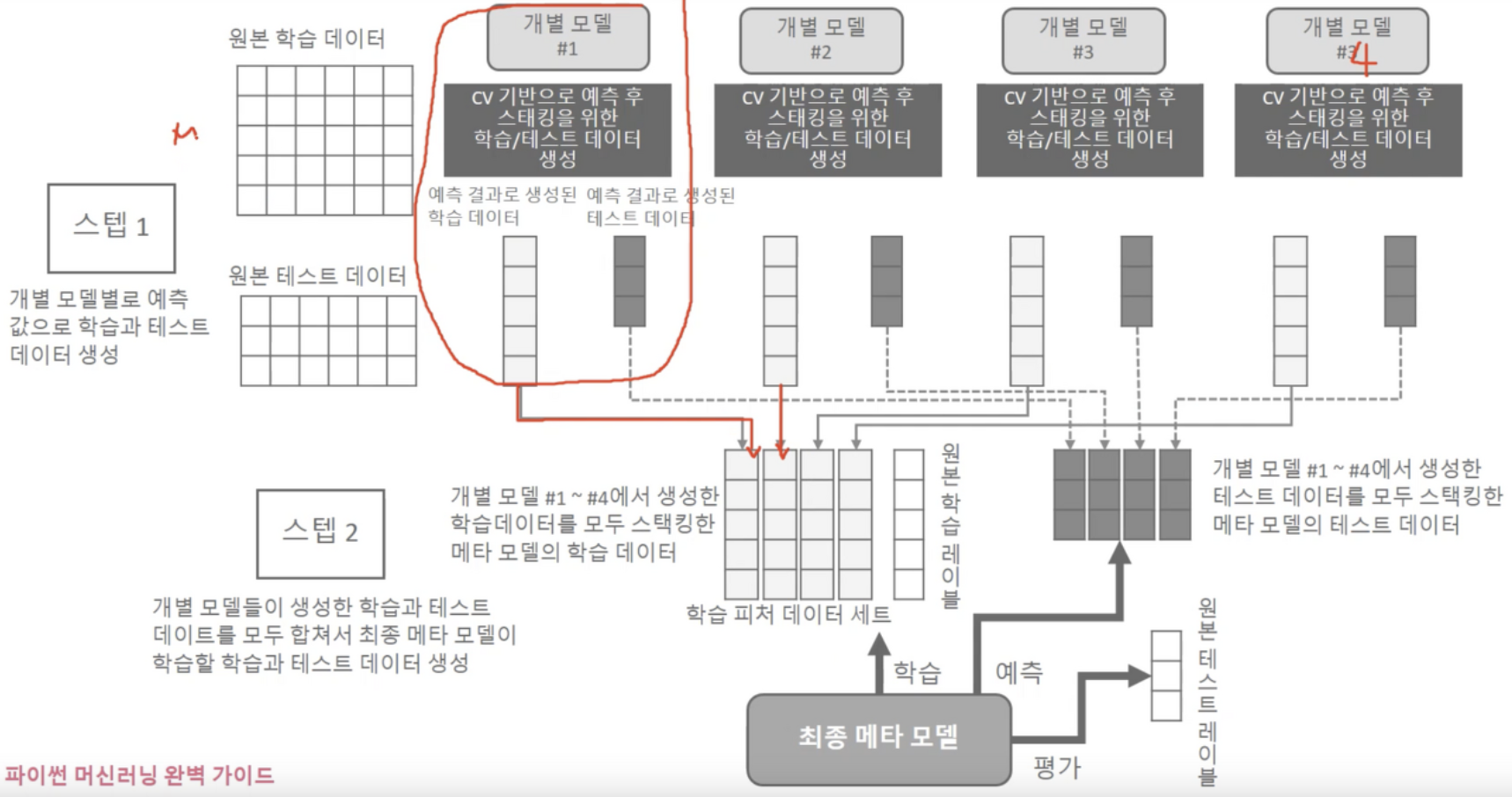
Scikit-learn을 이용해 Stacking을 구현
from sklearn.model_selection import KFold
from sklearn.metrics import accuracy_score
import warnings
warnings.filterwarnings(action='ignore')
# 개별모델 내부에서 CV 적용해 Stacking하는 함수 구현
def get_stacking_datasets(model, x_train_n, y_train_n, x_test_n, n_folds):
# CV하기 위해 K-fold 설정
kf = KFold(n_splits=n_folds, shuffle=False, random_state=42)
# 최종 메타 모델이 사용할 학습 데이터 반환을 위해서 넘파이 배열을 0으로 만들어서 초기화
train_fold_pred = np.zeros((x_train_n.shape[0], 1)) # 2차원으로
test_pred = np.zeros((x_test_n.shape[0], n_folds))
print(model.__class__.__name__, '모델 시작')
for folder_counter, (train_idx, valid_idx) in enumerate(kf.split(x_train_n)):
# 개별 모델 내부에서 학습하고 1개의 fold로 예측할 데이터 셋 추출
print(f" Fold 횟수 : {folder_counter+1}")
x_tr = x_train_n[train_idx]
y_tr = y_train_n[train_idx]
x_te = x_train_n[valid_idx]
# 개별 모델이 학습한 후 1개의 fold데이터셋으로 예측값 반환 후 최종 메타모델이 학습할 데이터셋에 첨가
model.fit(x_tr, y_tr)
train_fold_pred[valid_idx, :] = model.predict(x_te).reshape(-1,1)
# 개별 모델이 원본 데이터셋의 검증 데이터셋을 기반으로 예측 결과값 반환 후 최종 메타모델이 검증할 데이터셋에 첨가
test_pred[:, folder_counter] = model.predict(x_test_n)
# 개별모델안에서 테스트 데이터셋을 기반으로 예측한 결과값들 mean취해주고 2차원으로 바꾸어주기
test_pred_mean = np.mean(test_pred, axis=1).reshape(-1,1)
return train_fold_pred, test_pred_mean
knn_train, knn_test = get_stacking_datasets(knn_clf, x_train, y_train, x_test, 5)
rf_train, rf_test = get_stacking_datasets(rf_clf, x_train, y_train, x_test, 5)
ab_train, ab_test = get_stacking_datasets(ab_clf, x_train, y_train, x_test, 5)
dt_train, dt_test = get_stacking_datasets(dt_clf, x_train, y_train, x_test, 5)
# 개별모델이 생성한 학습/검증 데이터 최종 메타 모델이 학습/검증하도록 결합
stack_final_x_train = np.concatenate((knn_train, rf_train, ab_train, dt_train), axis=1)
stack_final_x_test = np.concatenate((knn_test, rf_test, ab_test, dt_test), axis=1)
# 최종 메타모델로 학습
# 최종 메타모델 학습시 label은 원본 데이터의 label(y값)
lr_final.fit(stack_final_x_train, y_train)
stack_final_pred = lr_final.predict(stack_final_x_test)
# 최종 메타모델 성능 평가(비교할 때 원본 데이터의 검증 데이터 label과 비교)
print(f"최종 메타모델 정확도 : {accuracy_score(y_test, stack_final_pred):.4f}")CatBoost
CatBoost는 GBM 알고리즘에 기반하여 만들어진 모델입니다. 2017년 논문으로 소개되었으며 현재까지 현업에서 활발하게 사용되고 있습니다.
Gradient Boosting
Gradient Boosting는 개념이 주어진 데이터의 일부를 학습시켜 만든 모델로 다른 데이터를 예측하여 발생한 잔차를 최소화하는 방향으로 학습한다 입니다.
여기서 사용하는 Gradient 라는 경사는 결국 미분, 변화량을 의미합니다. 이를 사용한다는 데 Gradient의 변화량과 잔차가 어떻게 동일한 것인지 먼저 이해해봅시다.
Loss Function을 수식을 미분하고 이항을 진행하면 잔차는 Loss fuction을 미분한 값에 음수를 붙인 값이 되고 따라서 Negative Gradient값이 되는 것입니다. 그래서 잔차를 쓰되 잔차는 Gradinet이기 때문에 모델의 이름이 GBM이 된 것입니다.
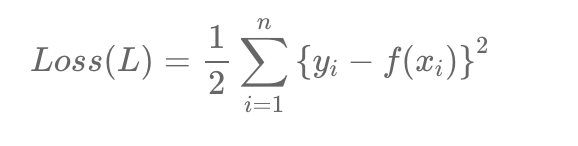
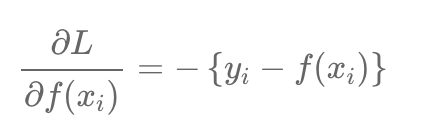
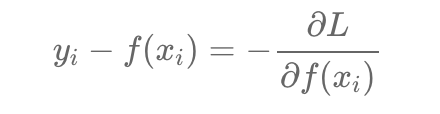
그래서 결국 잔차를 최소화하는 방향으로 학습을 진행한다는 것은 예측값을 활용하여 잔차 즉 모델이 제대로 학습되지 못한 부분 그래서 답이 틀리는 부분에 포커스를 맞춰 학습을 진행하여 더 완벽한 모델을 만든다는 것인데요.
하지만 여기서 말을 들으면서 예상하실 수 있겠지만 잔차에 포커싱을 맞춰 계속해서 학습을 진행시 자칫 과적합이 발생할 수 있으므로 주의해야합니다.
CatBoost 학습 방식
CatBoost 특징
앞서 배운 GBM의 단점인 과적합과 GBM계열 모델들의 학습 속도 문제를 CatBoost는 개선하였습니다.
그 해결 방식을 알아보면서 CatBoost 모델의 특징을 알아봅시다.
Symmetric Tree
XGBoost는 Level-wise, LightGBM은 Leaf-wise를 기반으로 트리 구조를 형성합니다.
CatBoost는 XGBoost처럼 Level-wise 트리구조를 쓰나 트리가 나눠지는 Feature들이 대칭으로 형성됩니다. 대칭 트리 형성 구조를 통해 예측 시간을 감소시키고 Boosting 계열 알고리즘의 느린 학습속도를 개선할 수 있었습니다.
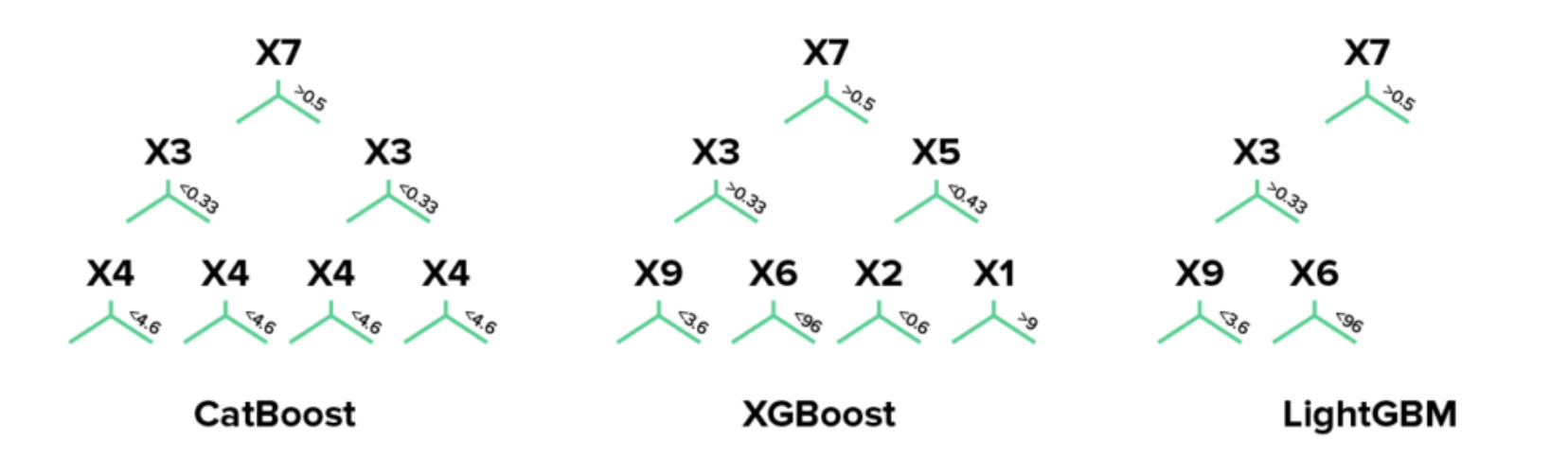
Ordered-Boosting
기존의 Boosting 모델들은 모든 훈련 데이터를 대상으로 잔차를 계산했습니다.
하지만, Catboost는 학습데이터의 일부만으로 잔차 계산을 한 뒤, 이 결과로 모델을 다시 만들게 된다. 예를 들어 학습데이터가 전체 10개의 row로 이루어져있을 경우 기존 모델들은 10행 컬럼을 모두 합산하여 평균낸 뒤 각 행별로 잔차를 계산한 뒤, 만들어진 모델에 대해 예측값을 내고 또 각각의 잔차를 구하여 잔차를 줄이는 방향으로 학습합니다..
하지만 Catboost모델은 학습데이터의 일부를 선택할 때 일종의 순서를 가지고 선택합니다.(10행 중 특정 2개만 학습, 그 뒤 4개 학습 등). 그래서 "Ordered Boosting" 이라고 부르는데요. 일종의 순서를 정의하는 기준이 논리적으로 정의되어있는 것은 아니고 Catboost는 순서도 사실 임의적인 것이기 때문에 데이터를 random하게 섞어주는 과정을 포함하고 있습니다. 또한 이는 Boosting모델이 오버피팅을 방지하기 위해 각각 지니고 있는 기법이라 볼 수 있다.
범주형 변수 처리
Catboost는 이름에서도 유추 가능하듯이 Cat, Category 즉 범주형 변수가 많은 데이터를 학습할 때 성능이 좋다고 합니다. Response encoding과 Categorical Feature Combination이라고 하여 두 방법이 범주형 변수를 효율적으로 처리하는데 큰 장점이 된다.
- Response encoding
범주형 변수를 인코딩하는 방법입니다.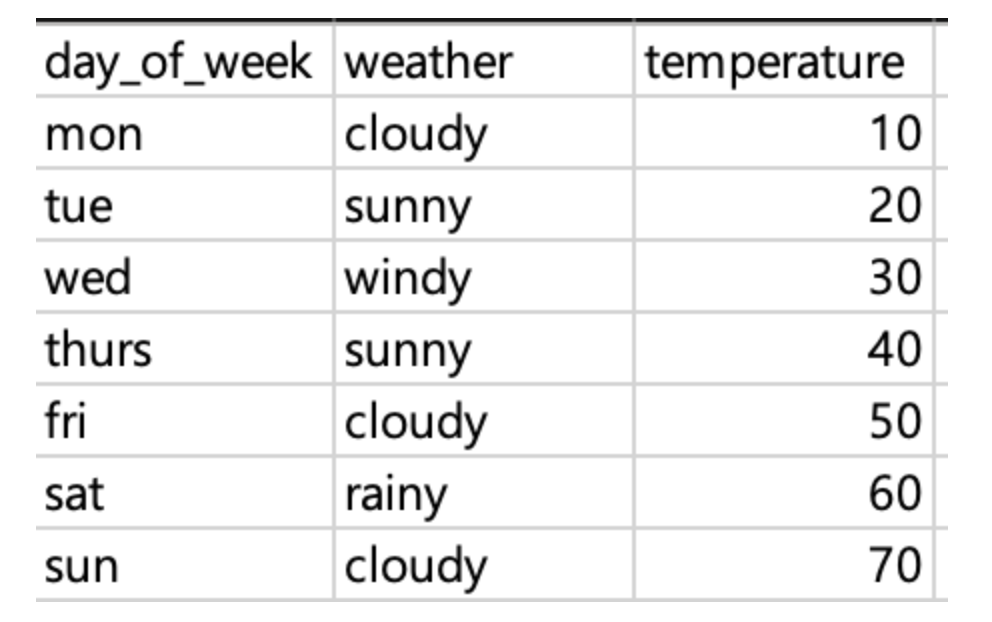
weather 컬럼은 범주형 변수인데, cloudy, sunny, windy, rainy 총 4가지의 값을 가지고 있다. 이 때 weather 컬럼을 response encoding에 따라 값을 변환하기 위해서 각 변주형 값의 temperature (=label) 컬럼의 값을 평균을 내어준다.
cloudy = (10+50+70)/3 = 33.33..
sunny = (20+40)/2 = 30
rainy = 60
windy = 30
하지만 이렇게 진행하면 label, 즉 target에 대한 정보를 일부 학습데이터에 노출시키는 것과 같습니다. 알겠지만 모델링을 할 때 학습데이터에서 target과 상관관계가 높거나 동일한 컬럼은 제외하고 만드는 것이 기본입니다. 따라서 Catboost는 위에서 언급된 Ordered Boosting개념을 섞어 Response Encoding을 진행합니다.
즉 앞서 봤듯 Catboost는 학습데이터 중 일부를 선택하여 학습시킵니다. 이 때 일부를 선택하는 'order'은 시간 순서에 따릅니다. 만약 데이터에 시계열 데이터가 없다면 임의로 시간을 정하여 순서를 정합니다(Random Permutation). 데이터의 시간 순으로 나열했을 때 과거 데이터만으로 response encoding을 진행하게 되는 것이다.
- Categorical Feature Combination
말 그대로 두 범주형 변수를 합쳐주는 것인데, label값을 기준으로 split을 할 때 두 범주형 변수가 서로 대체 가능하다면 이 둘을 합쳐줍니다.
예를 들어 우리나라 사람들의 민족 특성상 검은 머리와 검은 눈이 일반적인데, 이럴 경우 머리 컬럼과 눈색 컬럼을 합칠 수 있는 것입니다.
이렇게 두 컬럼을 합쳐 one-hot encoding 합니다.
Random Permutations
위의 response Encoding에서 살짝 봤지만 CatBoost는 주어진 전체 데이터를 임의적으로 일부 선택하여 학습한다고 했죠 이는 즉, N개의 Fold로 나누어서 각 Fold에 속한 데이터셋들에 Ordered Boosting을 적용하는 것과 같고 마치 K-fold Cross Validation 과정과 비슷합니다.
예를 들어, 100개의 데이터가 존재할 때, CatBoost는 4개의 Fold로 나누기로 했으면 주어진 데이터셋을 25개씩 나누고 각 25개의 데이터셋 마다 Ordered Boosting을 적용하게 된다.
이러한 방식은 부스팅 계열 알고리즘의 단점인 과적합 문제를 예방하는 데 도움이 된다.
수치형 변수 처리
수치형 변수는 다른 일반 트리 모델과 동일하게 처리합니다.
분기가 발생하면 Gain, 즉 정보의 획득량이 높은 방향대로 나뉘게 된다. 수치형 변수가 많게 되면 lightGBM 모델처럼 시간이 오래 걸린다. 따라서 범주형 변수가 많을 때 이 모델을 사용하기를 추천한다.
장점
- 시계열 데이터를 효율적으로 처리
- 속도가 빠름
실제 상용화되고 있는 서비스에 예측 기능을 삽입하고자 할 때 효과적이고 XGBoost보다 예측 속도가 8배 빠르다고 알려져있습니다. - imbalanced dataset도 class_weight 파라미터 조정을 통해 예측력을 높일 수도 있다.
그 외 Catboost는 오버피팅을 피하기 위해 내부적으로 여러 방법(random permutation, overfitting detector)을 갖추고 있어 속도 뿐만 아니라 예측력도 굉장히 높다.
한계점
- Sparse Matrix 즉, 결측치가 매우 많은 데이터셋에는 부적합한 모델입니다.
가령 추천시스템에 자주 사용되는 사용자-아이템 행렬 데이터를 살펴보면 보통 Sparse한 형태로 이루어져있는데 만약 이러한 데이터를 활용하려면 Sparse한 특성이 없도록 Embedding을 적용한다던지 등 데이터를 변형한 후 CatBoost에 활용하는 것이 적합합니다. - 수치형 변수가 매우 많은 데이터라면 LightGBM 보다 학습 속도가 오래 걸립니다.
소스
train_df = pd.read_csv('/kaggle/input/amazon-employee-access-challenge/train.csv')
test_df = pd.read_csv('/kaggle/input/amazon-employee-access-challenge/test.csv')
X = train_df.drop("ACTION", axis=1)
y = train_df["ACTION"]
cat_features = list(range(0, X.shape[1]))
from sklearn.model_selection import train_test_split
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=0)
from catboost import CatBoostClassifier
clf = CatBoostClassifier(
iterations=5,
learning_rate=0.1,
#loss_function='CrossEntropy'
)
clf.fit(X_train, y_train,
cat_features=cat_features,
eval_set=(X_val, y_val),
verbose=False
)
print('CatBoost model is fitted: ' + str(clf.is_fitted()))
print('CatBoost model parameters:')
print(clf.get_params())
from catboost import CatBoostClassifier
clf = CatBoostClassifier(
iterations=10,
# verbose=5,
)
clf.fit(
X_train, y_train,
cat_features=cat_features,
eval_set=(X_val, y_val),
)
from catboost import CatBoostClassifier
clf = CatBoostClassifier(
iterations=50,
random_seed=42,
learning_rate=0.5,
custom_loss=['AUC', 'Accuracy']
)
clf.fit(
X_train, y_train,
cat_features=cat_features,
eval_set=(X_val, y_val),
verbose=False,
plot=True
)모든 전체 소스는 해당 git에서 확인하실 수 있습니다.
참고자료 :
https://arxiv.org/pdf/1706.09516.pdf
https://www.kaggle.com/code/prashant111/catboost-classifier-in-python/notebook
https://julie-tech.tistory.com/119
https://techblog-history-younghunjo1.tistory.com/199
