
앞서 배운 Mysql Operator를 설치하고 살펴봅시다.
MySql Operator 설치하기
helm을 통해 간편하게 설치해보자. 왜냐? 간편하니깐!! helm이 있어서 무척 편합니다. 😃
helm에 대해서 알고 싶으신 분은 여기에 자세히 적어두었으니 확인해주세요.
우선 mysql operator repo를 추가해줍니다.
helm repo add mysql-operator https://mysql.github.io/mysql-operator/
helm repo listrepo가 잘 추가되었는지 확인합니다.

mysql-operator 네임스페이스에 Mysql operator를 설치합니다.
helm install mysql-operator mysql-operator/mysql-operator --namespace mysql-operator --create-namespacehelm을 통해 설치했으므로 deployment와 clusterIP 서비스 등이 생성됩니다.
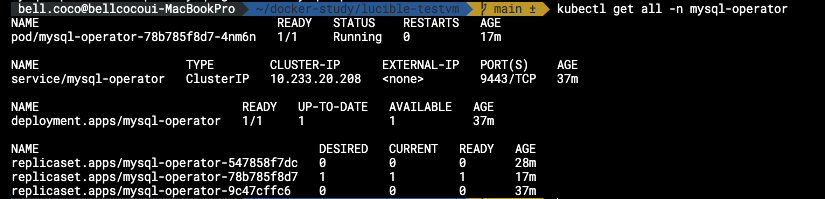
LENS IDE 사용하여 모니터링하기
저는 원격 k8s 대시보드를 통해 모니터링을 하기위해 LENS라는 IDE 를 사용하여 쿠버네티스 오브젝트와 현황을 모니터링합니다.
이를 사용하면 명령어를 일일히 작성하지 않아도 되고 현황을 ui를 통해 가시적으로 파악할 수 있어 용이합니다.
강추합니다!! 👍 LENS IDE 알아보기
LENS를 통한 모니터링 모습
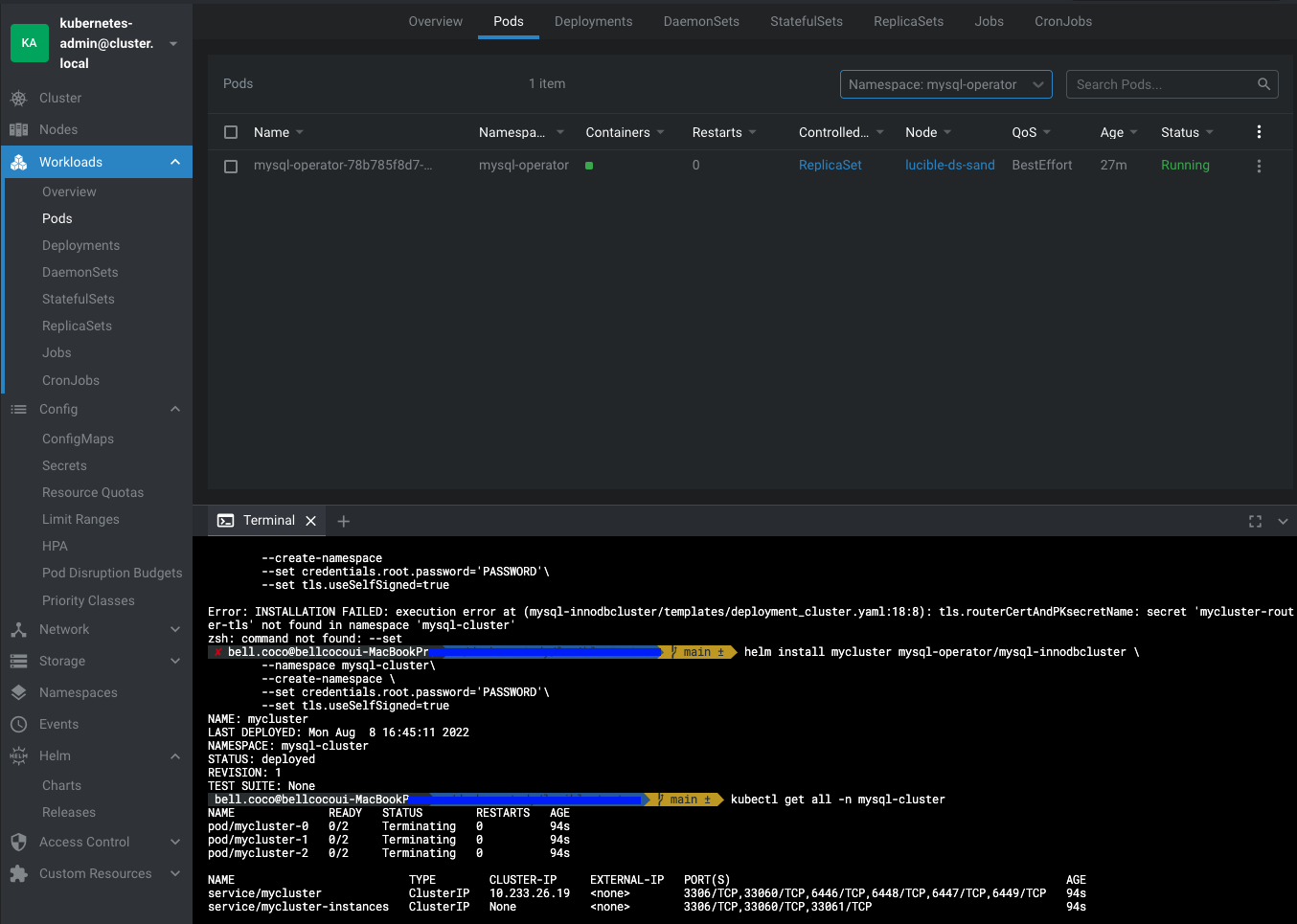
설치한 MySQL Operator를 사용해서 DB 클러스터를 생성해보겠습니다.
DB 클러스터는 InnoDBClusters라는 CRD로 생성할 수 있습니다.
설치하면서 설정을 set 명령어를 통해 동시에 진행할 수 있습니다.
helm install mycluster mysql-operator/mysql-innodbcluster \
--namespace mysql-cluster\
--create-namespace \
--set credentials.root.password='PASSWORD'\
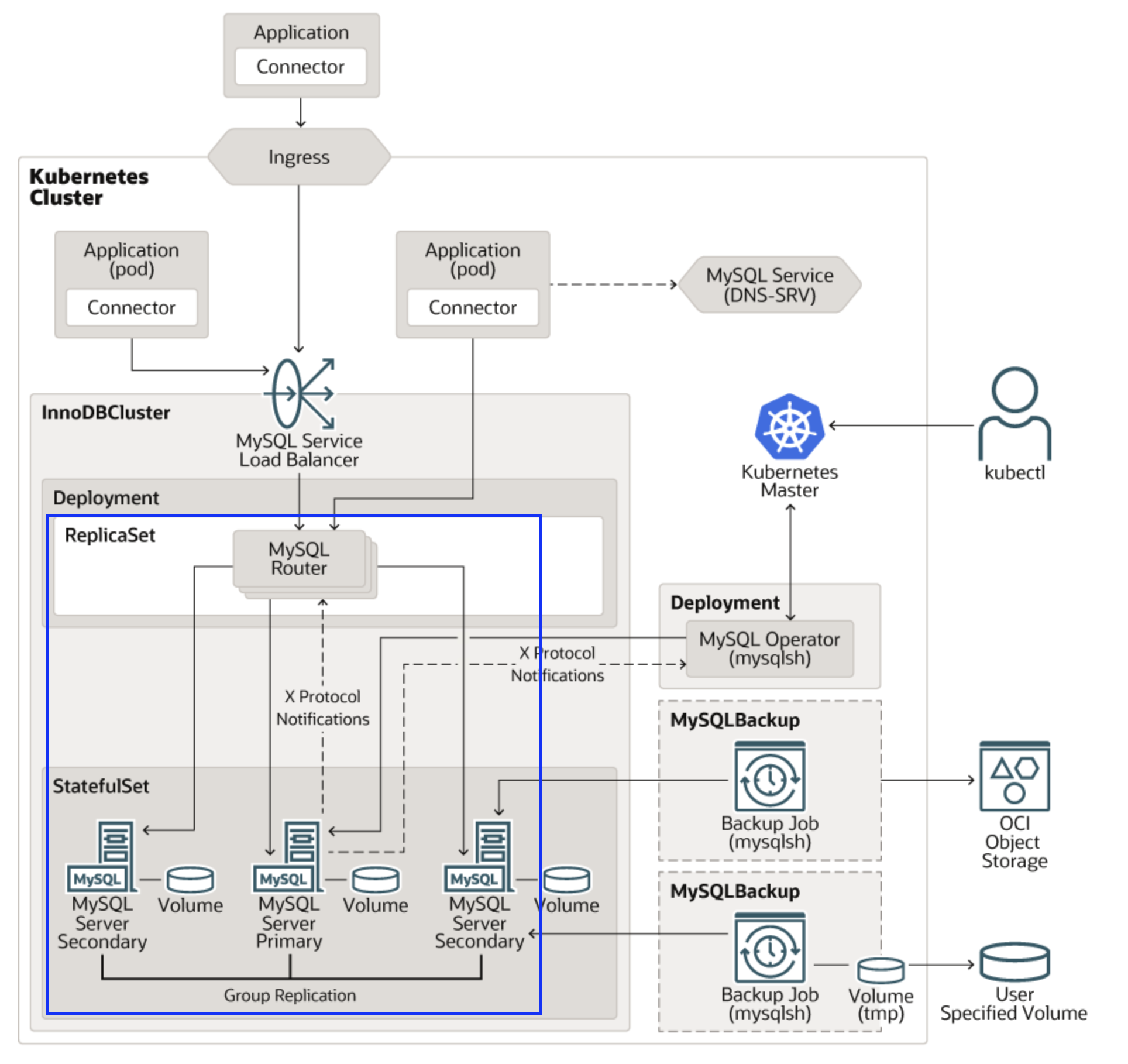
--set tls.useSelfSigned=true실행 후 보면 DB 클러스터 역할을 하는 Statefulset 1개, Headless Service 1개씩, 그리고 Mysql 라우터 역할을 하는 Deployment 하나를 생성되었습니다.
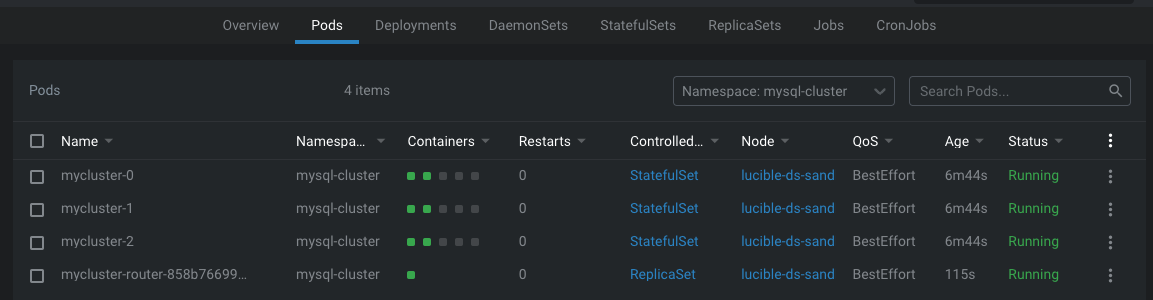

이 pod는 statefulset으로 실행됩니다.
실제 statefulset 소스를 살펴보면 replicaset이 3이어서 pods도 3개 구동 중인 것을 확인할 수 있습니다.
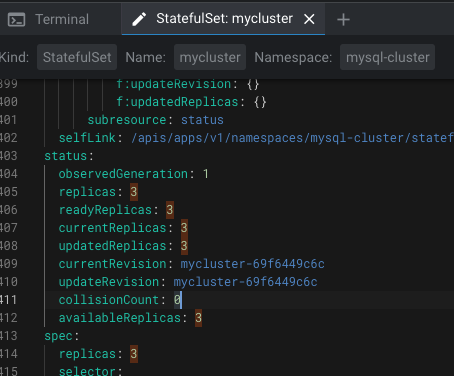
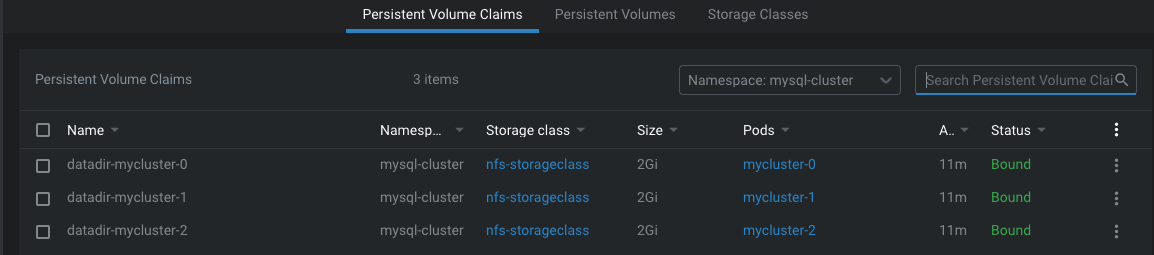
각각의 pod는 pvc를 통해 pv를 제공받고 DB 데이터를 저장합니다.
pod 개수만큼 pvc 생성됨.
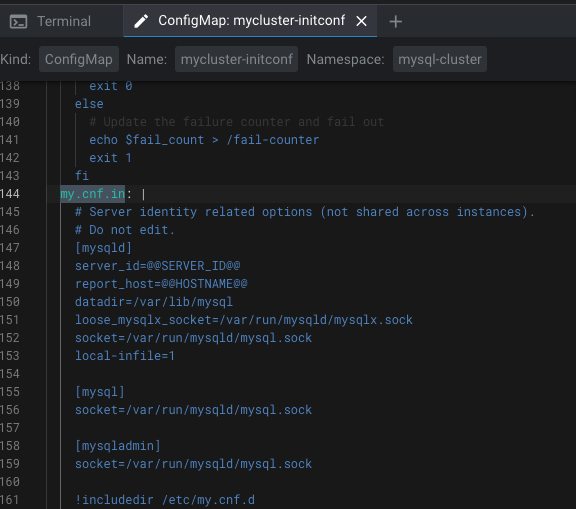
mycluster-initconf configmap이 생성되었습니다.
이 오브젝트 my.cnf.in 속성을 수정하여 mysql DB를 커스텀할 수 있습니다.

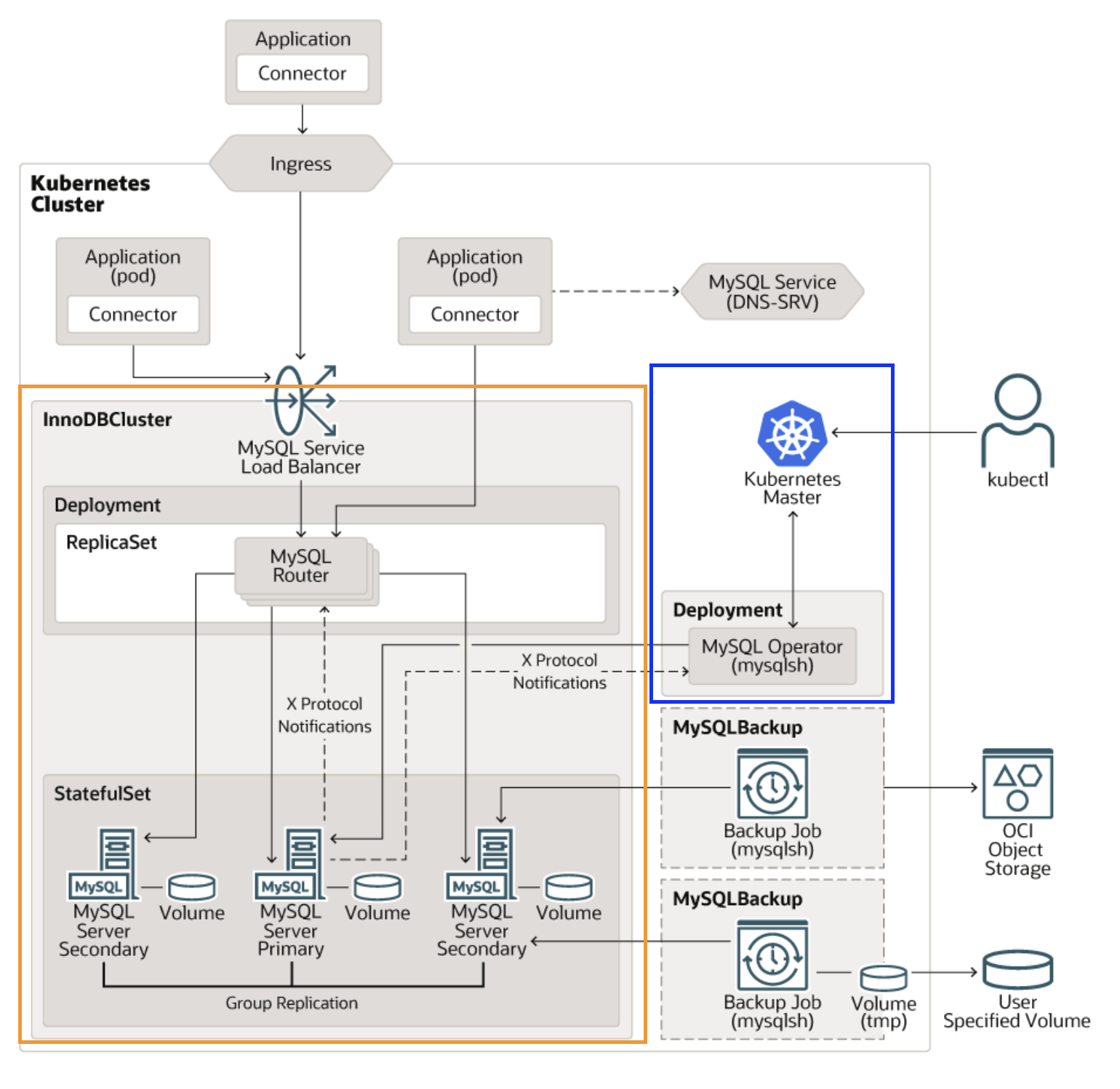
즉 우리는 지금까지 mysql-operator 네임스페이스에 파란부분 오브젝트를 세팅하였고
mysql-cluster 네임스페이스에 주황부분 오브젝트를 세팅하였습니다.
MySQL Operator 사용하기
쿠버네티스 환경에서 Mysql Operator를 구축했으니 DB에 접속해봅시다.
1. DB 접속하기
1. mysql-operator을 통한 Mysql shell 접속

접속된 것을 볼 수 있습니다.

mysql shell에서 mysql headless 서비스를 엔드포인트로 사용하는 \connect root@mycluster.mysql-cluster.svc.cluster.local:3306 과 같은 명령어를 사용하여 접속할 수 있습니다.
비밀번호를 적으라고 하는데 앞서 우리는 InnoDBCluster를 생성 시 비밀번호를 PASSWORD로 설정하였습니다.
\sql을 작성하면 sql mode로 변경할 수 있습니다.

2. port-forward를 통한 local 접속
mysql-operator Pod를 통해 간접 접속하지 않고도 port-forward를 사용해 Local 환경에서 바로 DB 인스턴스로 접속할 수 있습니다.
이를 사용하기 위해서는 MySQL이 로컬에 설치되어있어야합니다.
설치하지 않으신 분은 여기에 잘 정리해두었으니 설치에 참조하시기 바랍니다.
kubectl port-forward svc/mycluster 1090:3306 -n mysql-cluster# mysql이 설치된 위치로 이동
cd /usr/local/mysql/bin
./mysql -h 127.0.0.1 -uroot -pPASSWORD -P 1090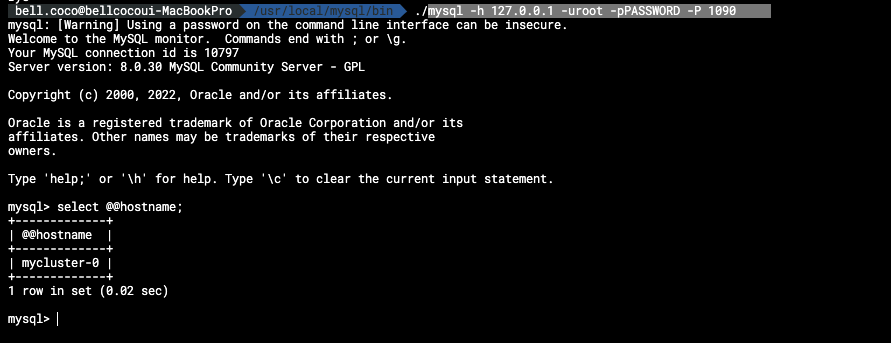
2. MySQL Router 부하분산 규칙
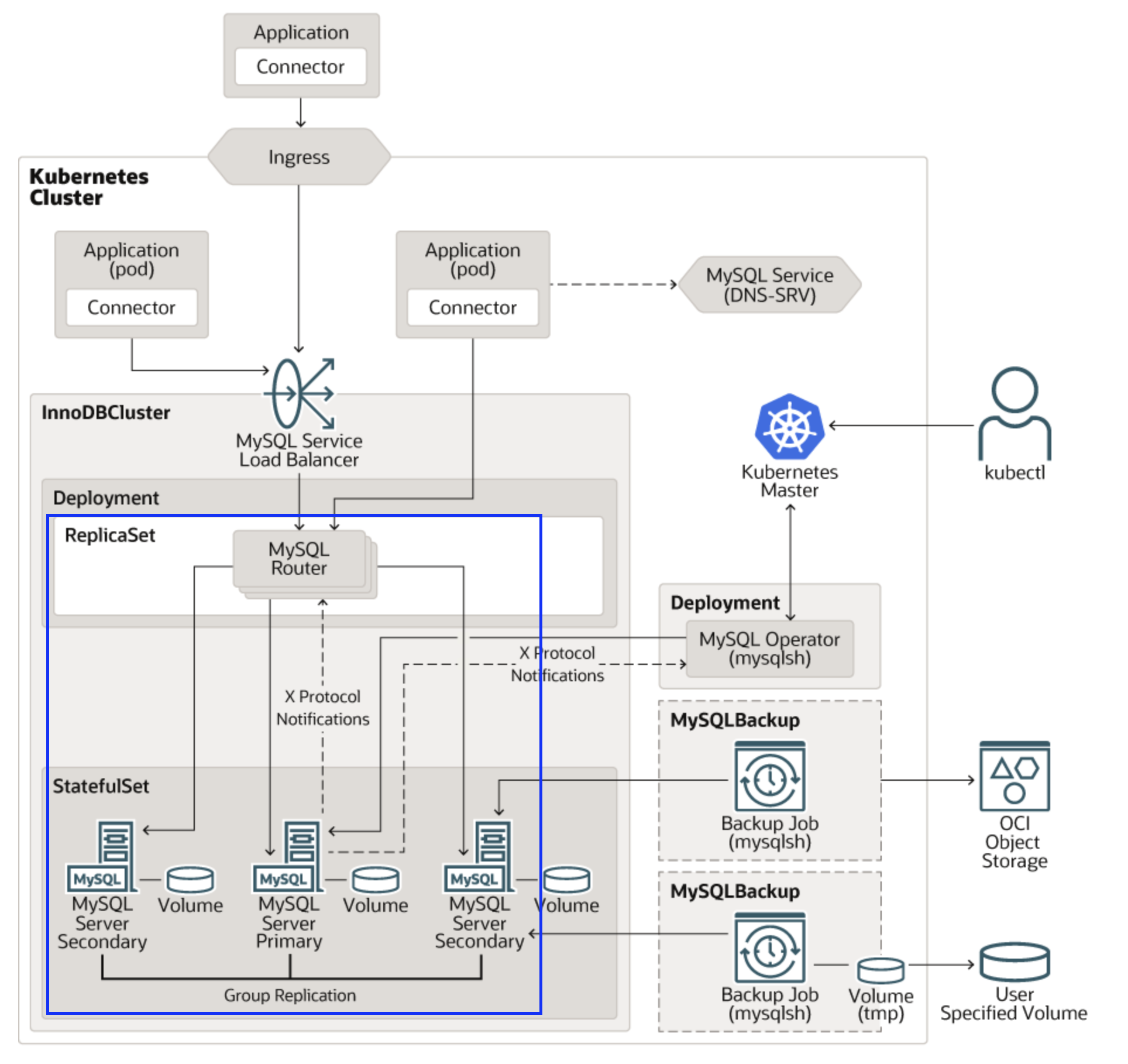
Mysql operator를 이용해서 설치한 InnoDBCluster는 여러 개의 DB 인스턴스로 이루어져있습니다.
이 여러개의 인스턴스에 연결을 부하 분산(Load Balancing) 가능합니다.
이 부하분산 역할을 하는 것이 MySQL Router입니다.
MySQL Router의 부하 분산 규칙은 접속 포트별로 다르며 Configuration 파일에 자세히 명시되어 있습니다.
mysql router pod에 접속하여 확인해 볼 수 있습니다.kubectl exec -n mysql-cluster mycluster-router-858b766998-9pghg -it -- /bin/bash bash-4.4$ cat /tmp/mysqlrouter/mysqlrouter.conf
port 정보가 6446~6449로 4개의 포트를 사용하여 할당하며 각 포트마다 사용하는 routing_strategy와 destinations가 모두 다릅니다.
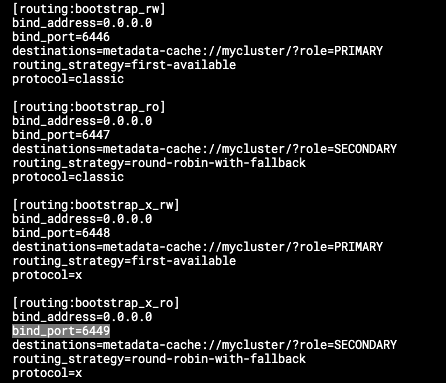
routing_strategy
- first-available
Destination 인스턴스로 접근하며, 실패 시 다음 인스턴스로 시도하는 것을 모든 인스턴스를 확인할 때까지 반복하는 전략
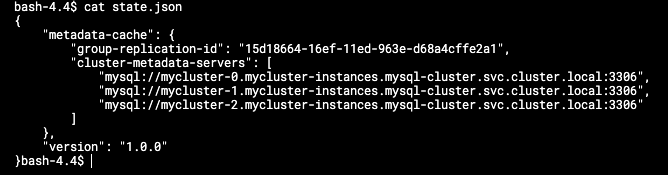
/tmp/mysqlrouter/data 디렉토리의 data.json 파일에는 mysql Router가 캐싱한 DB 인스턴스 정보가 기입되어 있습니다. Mysql 라우터는 이 정보를 기반으로 DB 인스턴스에게 부하를 분산합니다.
이곳에 보이는 인스턴스는 앞서 생성된 pod 정보들입니다.
3. Single-Primary mode vs Multi-Primary mode
1. Single-Primary mode
InnoDBCluster의 Replication Mode에는 하나의 Primary와 여러 개의 Secondary 인스턴스로 이루어짐.
기존에 존재하던 여러 개의 Replica들이 하나의 Primary를 참고해 지속적으로 복제를 수행하는 방식의 replication 모드
Write 작업은 Primary에, Read 작업은 Replica에 들어오게 되어 작업 부하를 분산
2. Multi-Primary mode
모든 구성원이 Primary로 동작하는 replication 모드
모든 구성원이 양방향으로 복제를 수행하기 때문에 Write 작업과 Read 작업을 고루 분산하게 됩니다.
Multi-Primary mode로 변경하기
SELECT group_replication_switch_to_multi_primary_mode();
변경 후 클러스터 멤버 상태 확인
select member_host, member_state, member_role, member_version from performance_schema.replication_group_members ;
모든 인스턴스의 역할이 Primary가 되어있습니다.
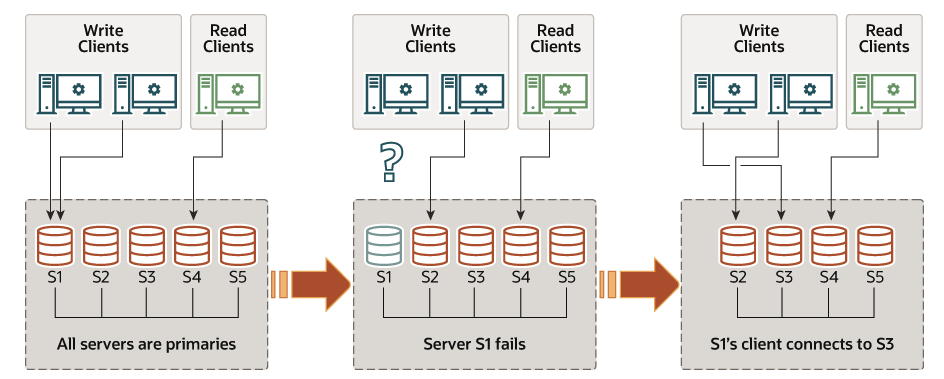


이전에는 /tmp/mysqlrouter/mysqlrouter.conf 에 정의된 분산 규칙(first-available)에 따라 지정된 Primary 인스턴스에만 접근했는데, 이제는 Multi-Primary Mode에서는 모든 인스턴스가 Primary이므로 모든 인스턴스에 고루 접근하게 된다.
4. Mysql Operator Failover 테스트
쿠버네티스 환경에서 운영되는 DB는 다양한 fail 상황에서 failover 할 수 있어야합니다.
1. POD Failure
MySQL Operator가 관리하는 InnoDBCluster의 인스턴스는 Statefulset으로 관리되고 Kubernetes의 Statefulset는 Pod가 중지되거나 삭제되면 이를 복구하는 기능이 있습니다.
의도적으로 DB POD를 삭제하여 Failover가 정상적으로 작동하는지 보겠습니다.
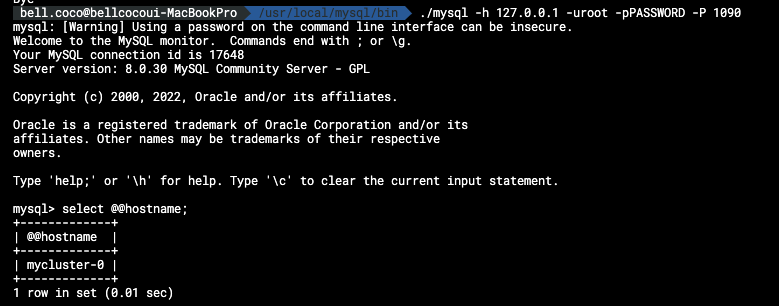
지금 보면 mycluster-0 으로 접속하죠 그래서 저 pod를 의도적으로 삭제하겠습니다.
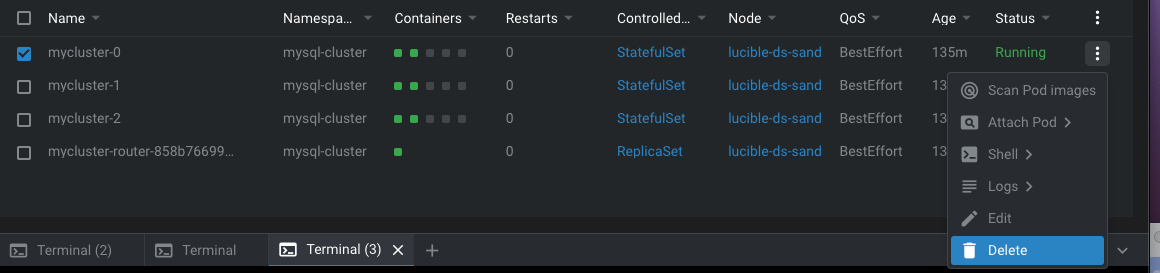
삭제 후 접속해보니 다른 pod 인스턴스로 접속된 것을 볼 수 있습니다.
이는 MySQL 라우터가 기존 DB POD의 접속 이상을 감지 후 자동으로 다른 호스트에 접속시킨 것입니다.
즉, DB POD의 Failover는 MySQL Router를 이용해서 진행되며 세션이 끊기지 않고 유지됩니다.
2. Router Pod Failure
중간 Proxy 역할을 하는 Mysql Router Pod의 failure입니다.
MySQL Router는 Deployment로 관리되는 Pod로 배포됩니다.
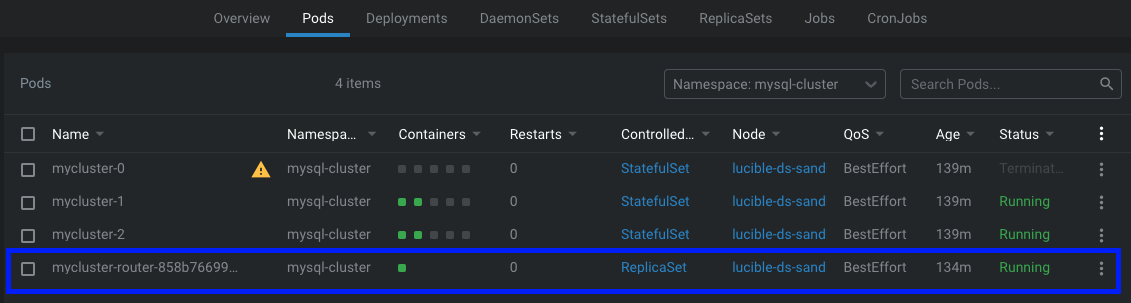
MySQL Router Pod 또한 삭제되거나 유실 시, Deploymen로 관리되는 pod여서 복구됩니다.
따라서, 강제로 삭제 후 접속해 보면 다음처럼 접속이 끊겼다는 문구가 나오고
다시 접속을 재개하는 것을 볼 수 있습니다.
이는 삭제된 후 다시 생성되어 진행되므로 접속이 재게 되는 것입니다.
즉, Router Pod Failure은 Deployment 관리로 인해 세션이 끊기지 않고 유지됩니다.
3. Node Failure
Kubernetes는 Node 단위로 Pod를 담기 때문에 Node의 Failure 상황이나 Node의 개수를 줄인다면 그 위의 Pod들은 모두 삭제되지만, 이러한 상황에서도 Kubernetes는 일반적인 Pod Failure 상황과 동일하게 다른 Node에서 Pod를 재생성하는 Failover를 수행하게 됩니다.
InnoDBCluster를 이루는 DB Pod 구성원 모두가 삭제된다면 DB 구성원이 남아있지 않게 되기 때문에 장시간의 Lost Connection을 겪게됩니다.
이럴 때를 대비해서 InnoDBCluster 구성요소에는 PodDistruptionBudget 오브젝트가 포함되어 있습니다.
PodDistruptionBudget(이하 PDB)는 한 번에 삭제될 수 있는 Pod의 개수를 제한할 수 있는 오브젝트
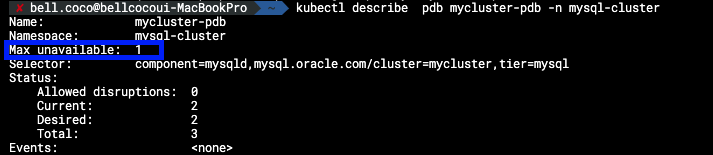
Max unavailable은 1로 한번에 pod는 최대 1개만 삭제될 수 있는 것입니다.
따라서, Node를 강제로 Drain하려고 해도 PDB에 의해 DB 클러스터가 안정적으로 유지되게 됩니다.
