전력량 예측
import pandas as pd
import tensorflow as tftrain_data = pd.read_csv("/content/drive/MyDrive/Lecture/삼성 디스플레이/2주차/1_DL_examples/DL 미니 프로젝트/3_Energy/energy_train_data.csv")
trian_labels = pd.read_csv("/content/drive/MyDrive/Lecture/삼성 디스플레이/2주차/1_DL_examples/DL 미니 프로젝트/3_Energy/energy_train_labels.csv")
test_data = pd.read_csv("/content/drive/MyDrive/Lecture/삼성 디스플레이/2주차/1_DL_examples/DL 미니 프로젝트/3_Energy/energy_test_data.csv")
test_labels = pd.read_csv("/content/drive/MyDrive/Lecture/삼성 디스플레이/2주차/1_DL_examples/DL 미니 프로젝트/3_Energy/energy_test_labels.csv")train = pd.concat([train_data, trian_labels], axis=1)
test = pd.concat([test_data, test_labels], axis=1)train = train.dropna()
test = test.dropna()train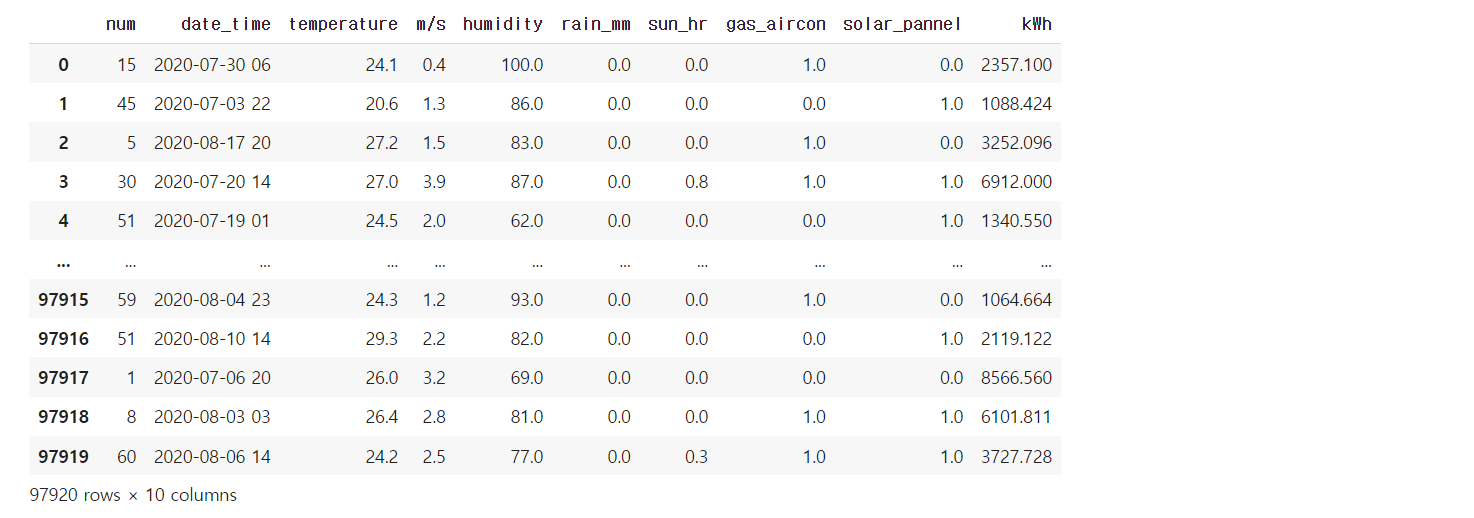
test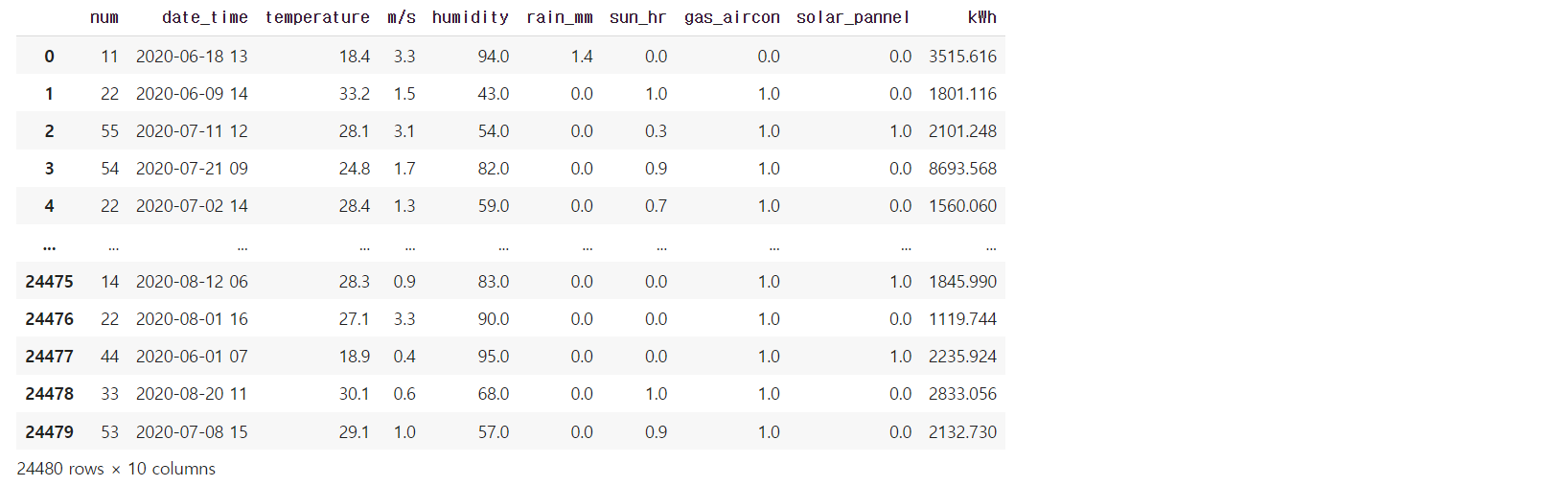
Make Dataset
def df_to_dataset(dataframe, label_name="kWh", shuffle=True, batch_size=4):
dataframe = dataframe.copy()
labels = dataframe.pop(label_name)
ds = tf.data.Dataset.from_tensor_slices((dict(dataframe), labels))
if shuffle:
ds = ds.shuffle(buffer_size=len(dataframe))
ds = ds.batch(batch_size)
return ds

AI, Information and Communication, Electronics, Computer Science, Bio, Algorithms