Spaceship Titanic with DL
배경
-
우주의 미스터리를 풀기 위해 데이터 과학 기술이 필요한 2912년에 오신 것을 환영합니다. 4광년 떨어진 곳에서 전송을 받았는데 상태가 좋지 않습니다.
-
우주선 타이타닉은 한 달 전에 발사된 성간 여객선이었습니다. 약 13,000명의 승객을 태운 이 선박은 우리 태양계에서 가까운 별을 도는 새로 거주 가능한 세 개의 외계 행성으로 이민자들을 수송하는 첫 항해를 시작했습니다.
-
첫 번째 목적지인 55 Cancri E로 가는 도중 Alpha Centauri를 돌던 중 부주의한 우주선 Titanic이 먼지 구름 속에 숨겨진 시공간 변칙과 충돌했습니다. 안타깝게도 1000년 전의 이름과 비슷한 운명을 맞이했습니다. 배는 온전했지만 승객의 거의 절반이 다른 차원으로 이동했습니다!
데이터 정보
-
PassengerId
- 각 승객의 고유 ID. 각 Id는 승객이 함께 여행하는 그룹을 나타내고 그룹 내의 번호를 나타내는 형식을 취합니다 . 그룹의 사람들은 종종 가족 구성원이지만 항상 그런 것은 아닙니다.
-
HomePlanet
-
승객이 출발한 행성으로, 일반적으로 승객이 거주하는 행성입니다.
-
CryoSleep
- 승객이 항해 기간 동안 냉동 수면 선택했는지 여부를 나타냅니다. cryosleep의 승객은 객실에 갇혀 있습니다.
-
Cabin
- 승객이 머무르는 캐빈 번호. 형식을 취합니다 deck/num/side. 여기 에서 Port 또는 Starboard 가 side될 수 있습니다.
-
Destination
- 승객이 내릴 행성.
-
Age
- 승객의 나이.
-
VIP
- 승객이 항해 중 특별 VIP 서비스 비용을 지불했는지 여부.
-
RoomService, FoodCourt, ShoppingMall, Spa, VRDeck
- 승객이 Spaceship Titanic 의 다양한 고급 편의 시설 각각에 대해 청구한 금액입니다.
-
Name
- 승객의 성과 이름.
-
Transported
- 승객이 다른 차원으로 이동했는지 여부. 정답 데이터입니다.
import library
import pandas as pd
import tensorflow as tfData Load
Read CSV files wit pandas
train_data = pd.read_csv("/content/drive/MyDrive/Lecture/양재AI_NLP_basic_to_LLMs/2주차/DL_exercise/DL 미니 프로젝트/2_Spaceship_Titanic/spaceship_titanic_train_data.csv")
train_labels = pd.read_csv("/content/drive/MyDrive/Lecture/양재AI_NLP_basic_to_LLMs/2주차/DL_exercise/DL 미니 프로젝트/2_Spaceship_Titanic/spaceship_titanic_train_labels.csv")
test_data = pd.read_csv("/content/drive/MyDrive/Lecture/양재AI_NLP_basic_to_LLMs/2주차/DL_exercise/DL 미니 프로젝트/2_Spaceship_Titanic/spaceship_titanic_test_data.csv")
test_labels = pd.read_csv("/content/drive/MyDrive/Lecture/양재AI_NLP_basic_to_LLMs/2주차/DL_exercise/DL 미니 프로젝트/2_Spaceship_Titanic/spaceship_titanic_test_labels.csv")
train = pd.concat([train_data, train_labels], axis=1)
test = pd.concat([test_data, test_labels], axis=1)Preprocessing
- 결측치 제거 후 데이터 로더에 연결
train = train.fillna(method='bfill')
test = test.fillna(method='bfill')train.dtypesPassengerId object
HomePlanet object
CryoSleep bool
Cabin object
Destination object
Age float64
VIP bool
RoomService float64
FoodCourt float64
ShoppingMall float64
Spa float64
VRDeck float64
Name object
Transported bool
dtype: object# 일부 dtype은 tensor로 변경 불가
train['HomePlanet'] = train['HomePlanet'].astype('category')
train['CryoSleep'] = train['CryoSleep'].map({True: 1, False: 0})
train['VIP'] = train['VIP'].map({True: 1, False: 0})
train['Transported'] = train['Transported'].map({True: 1, False: 0})
test['HomePlanet'] = test['HomePlanet'].astype('category')
test['CryoSleep'] = test['CryoSleep'].map({True: 1, False: 0})
test['VIP'] = test['VIP'].map({True: 1, False: 0})
test['Transported'] = test['Transported'].map({True: 1, False: 0})train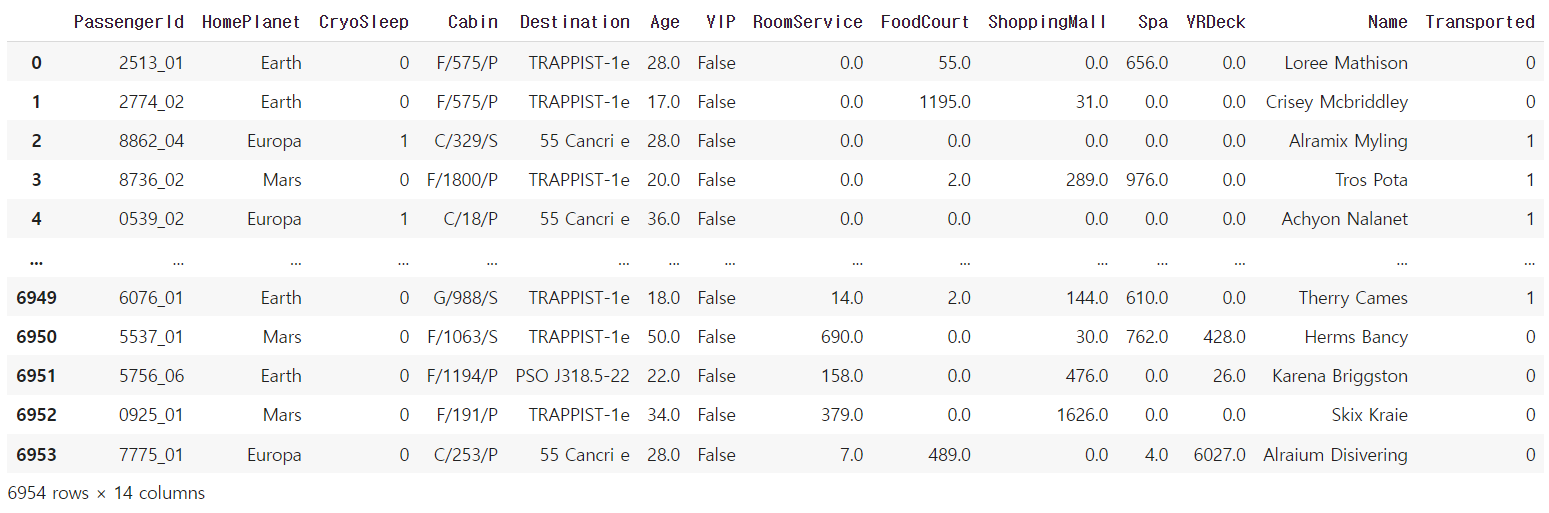
test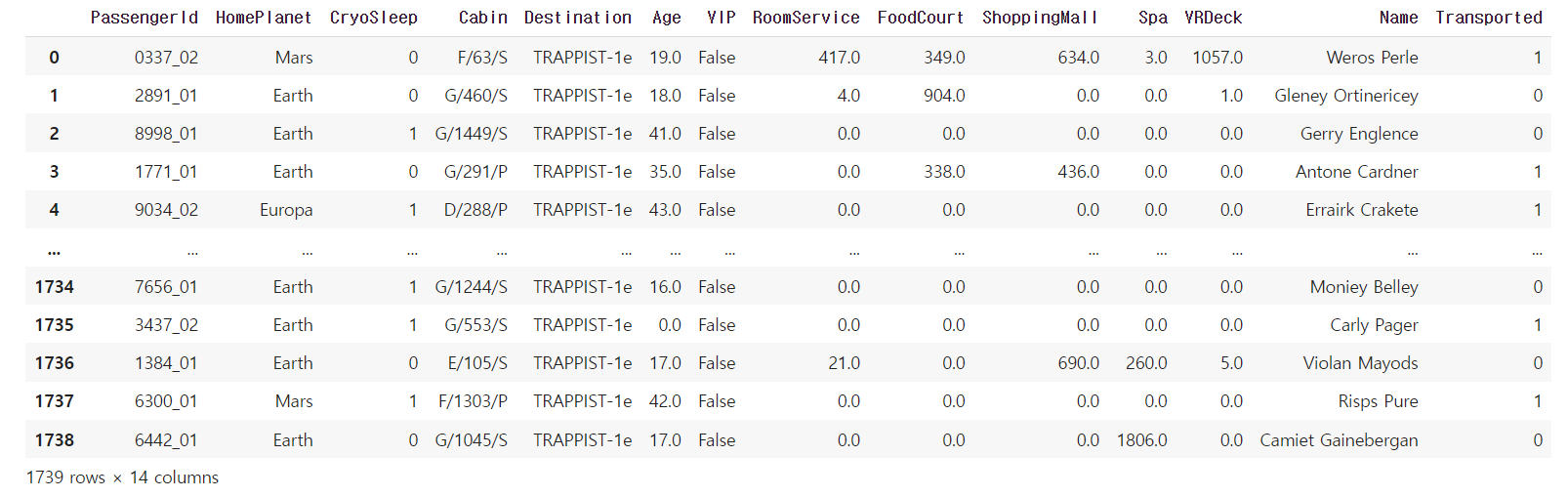
Data Loader
batch_size = 4
def df_to_dataset(dataframe, label_name="Transported", shuffle=True, batch_size=batch_size):
dataframe = dataframe.copy()
labels = dataframe.pop(label_name)
ds = tf.data.Dataset.from_tensor_slices((dict(dataframe), labels))
if shuffle:
ds = ds.shuffle(buffer_size=len(dataframe))
ds = ds.repeat()
ds = ds.batch(batch_size)
return ds
train_ds = df_to_dataset(train)
train_ds#_BatchDataset element_spec=({'PassengerId': TensorSpec(shape=(None,), dtype=tf.string, name=None), 'HomePlanet': TensorSpec(shape=(None,), dtype=tf.string, name=None), 'CryoSleep': TensorSpec(shape=(None,), dtype=tf.int64, name=None), 'Cabin': TensorSpec(shape=(None,), dtype=tf.string, name=None), 'Destination': TensorSpec(shape=(None,), dtype=tf.string, name=None), 'Age': TensorSpec(shape=(None,), dtype=tf.float64, name=None), 'VIP': TensorSpec(shape=(None,), dtype=tf.string, name=None), 'RoomService': TensorSpec(shape=(None,), dtype=tf.float64, name=None), 'FoodCourt': TensorSpec(shape=(None,), dtype=tf.float64, name=None), 'ShoppingMall': TensorSpec(shape=(None,), dtype=tf.float64, name=None), 'Spa': TensorSpec(shape=(None,), dtype=tf.float64, name=None), 'VRDeck': TensorSpec(shape=(None,), dtype=tf.float64, name=None), 'Name': TensorSpec(shape=(None,), dtype=tf.string, name=None)}, TensorSpec(shape=(None,), dtype=tf.int64, name=None))>test_ds = df_to_dataset(test, shuffle=False)
test_ds#_BatchDataset element_spec=({'PassengerId': TensorSpec(shape=(None,), dtype=tf.string, name=None), 'HomePlanet': TensorSpec(shape=(None,), dtype=tf.string, name=None), 'CryoSleep': TensorSpec(shape=(None,), dtype=tf.int64, name=None), 'Cabin': TensorSpec(shape=(None,), dtype=tf.string, name=None), 'Destination': TensorSpec(shape=(None,), dtype=tf.string, name=None), 'Age': TensorSpec(shape=(None,), dtype=tf.float64, name=None), 'VIP': TensorSpec(shape=(None,), dtype=tf.string, name=None), 'RoomService': TensorSpec(shape=(None,), dtype=tf.float64, name=None), 'FoodCourt': TensorSpec(shape=(None,), dtype=tf.float64, name=None), 'ShoppingMall': TensorSpec(shape=(None,), dtype=tf.float64, name=None), 'Spa': TensorSpec(shape=(None,), dtype=tf.float64, name=None), 'VRDeck': TensorSpec(shape=(None,), dtype=tf.float64, name=None), 'Name': TensorSpec(shape=(None,), dtype=tf.string, name=None)}, TensorSpec(shape=(None,), dtype=tf.int64, name=None))>for t, l in train_ds:
print(t, l)
break
for t, l in test_ds:
print(t, l)
break#OUTPUT
{'PassengerId': <tf.Tensor: shape=(4,), dtype=string, numpy=array([b'5722_01', b'0453_01', b'8383_06', b'5220_01'], dtype=object)>, 'HomePlanet': <tf.Tensor: shape=(4,), dtype=string, numpy=array([b'Earth', b'Europa', b'Earth', b'Mars'], dtype=object)>, 'CryoSleep': <tf.Tensor: shape=(4,), dtype=int64, numpy=array([0, 1, 0, 0])>, 'Cabin': <tf.Tensor: shape=(4,), dtype=string, numpy=array([b'G/928/S', b'B/14/S', b'G/1368/P', b'D/165/P'], dtype=object)>, 'Destination': <tf.Tensor: shape=(4,), dtype=string, numpy=
array([b'TRAPPIST-1e', b'TRAPPIST-1e', b'TRAPPIST-1e', b'TRAPPIST-1e'],
dtype=object)>, 'Age': <tf.Tensor: shape=(4,), dtype=float64, numpy=array([44., 19., 57., 21.])>, 'VIP': <tf.Tensor: shape=(4,), dtype=string, numpy=array([b'False', b'False', b'False', b'False'], dtype=object)>, 'RoomService': <tf.Tensor: shape=(4,), dtype=float64, numpy=array([ 69., 0., 0., 2206.])>, 'FoodCourt': <tf.Tensor: shape=(4,), dtype=float64, numpy=array([ 0., 0., 839., 0.])>, 'ShoppingMall': <tf.Tensor: shape=(4,), dtype=float64, numpy=array([ 17., 0., 1., 353.])>, 'Spa': <tf.Tensor: shape=(4,), dtype=float64, numpy=array([176., 0., 0., 0.])>, 'VRDeck': <tf.Tensor: shape=(4,), dtype=float64, numpy=array([2.105e+03, 0.000e+00, 2.000e+00, 1.900e+01])>, 'Name': <tf.Tensor: shape=(4,), dtype=string, numpy=
array([b'Joyces Ington', b'Aldun Taptiritty', b'Jorgie Gibbsonton',
b'Jackok Cooki'], dtype=object)>} tf.Tensor([0 1 1 0], shape=(4,), dtype=int64)
{'PassengerId': <tf.Tensor: shape=(4,), dtype=string, numpy=array([b'0337_02', b'2891_01', b'8998_01', b'1771_01'], dtype=object)>, 'HomePlanet': <tf.Tensor: shape=(4,), dtype=string, numpy=array([b'Mars', b'Earth', b'Earth', b'Earth'], dtype=object)>, 'CryoSleep': <tf.Tensor: shape=(4,), dtype=int64, numpy=array([0, 0, 1, 0])>, 'Cabin': <tf.Tensor: shape=(4,), dtype=string, numpy=array([b'F/63/S', b'G/460/S', b'G/1449/S', b'G/291/P'], dtype=object)>, 'Destination': <tf.Tensor: shape=(4,), dtype=string, numpy=
array([b'TRAPPIST-1e', b'TRAPPIST-1e', b'TRAPPIST-1e', b'TRAPPIST-1e'],
dtype=object)>, 'Age': <tf.Tensor: shape=(4,), dtype=float64, numpy=array([19., 18., 41., 35.])>, 'VIP': <tf.Tensor: shape=(4,), dtype=string, numpy=array([b'False', b'False', b'False', b'False'], dtype=object)>, 'RoomService': <tf.Tensor: shape=(4,), dtype=float64, numpy=array([417., 4., 0., 0.])>, 'FoodCourt': <tf.Tensor: shape=(4,), dtype=float64, numpy=array([349., 904., 0., 338.])>, 'ShoppingMall': <tf.Tensor: shape=(4,), dtype=float64, numpy=array([634., 0., 0., 436.])>, 'Spa': <tf.Tensor: shape=(4,), dtype=float64, numpy=array([3., 0., 0., 0.])>, 'VRDeck': <tf.Tensor: shape=(4,), dtype=float64, numpy=array([1.057e+03, 1.000e+00, 0.000e+00, 0.000e+00])>, 'Name': <tf.Tensor: shape=(4,), dtype=string, numpy=
array([b'Weros Perle', b'Gleney Ortinericey', b'Gerry Englence',
b'Antone Cardner'], dtype=object)>} tf.Tensor([1 0 0 1], shape=(4,), dtype=int64)list(set(train['VIP']))#'True', 'False']Preprocessing with layers
inputs = {
'CryoSleep': tf.keras.Input(shape=(), dtype='int64'),
'HomePlanet': tf.keras.Input(shape=(), dtype='string'),
'RoomService': tf.keras.Input(shape=(), dtype='float64'),
'VIP': tf.keras.Input(shape=(), dtype='string'),
'Cabin': tf.keras.Input(shape=(), dtype='string')
}
split_text = tf.strings.split(inputs['Cabin'], sep="/")
# Convert index to one-hot; e.g. [2] -> [0,1].
type_output = tf.keras.layers.CategoryEncoding(num_tokens=2, output_mode='one_hot')(inputs['CryoSleep'])
print(type_output.shape)
dense_type = tf.keras.layers.Dense(2, activation='relu')(type_output)
print(dense_type.shape)
vip = tf.keras.layers.StringLookup(vocabulary=["True", "False"], num_oov_indices=0, output_mode='one_hot')(inputs['VIP'])
print(vip.shape)
# Convert size strings to indices; e.g. ['small'] -> [1].
size_output = tf.keras.layers.StringLookup(vocabulary=list(set(train['HomePlanet'])))(inputs['HomePlanet'])
size_output = tf.keras.layers.Reshape([-1])(size_output)
# print(size_output.shape)
dense_size = tf.keras.layers.Dense(2, activation='relu')(size_output)
# print(dense_size.shape)
# Normalize the numeric inputs; e.g. [2.0] -> [0.0].
weight_output = tf.keras.layers.Normalization(
axis=None, mean=2.0, variance=1.0)(inputs['RoomService'])
weight_output = tf.keras.layers.Reshape([-1])(weight_output)
# print(weight_output.shape)
dense_weight = tf.keras.layers.Dense(2, activation='relu')(weight_output)
# print(dense_weight.shape)
x = tf.concat([dense_type, dense_size, dense_weight], -1) # batch, 특징 (여기로 합쳐라)
x = tf.keras.layers.Dense(4, activation='relu')(x)
x = tf.keras.layers.Dense(4, activation='relu')(x)
outputs = tf.keras.layers.Dense(1)(x) # Sigmoid, BCE loss
# outputs = {
# 'CryoSleep': type_output,
# 'HomePlanet': size_output,
# 'RoomService': weight_output,
# 'VIP': vip,
# 's': split_text
# }
preprocessing_model = tf.keras.Model(inputs, outputs)#(None, 2)
#(None, 2)
#/usr/local/lib/python3.10/dist-packages/numpy/core/numeric.py:2463: #FutureWarning: elementwise comparison failed; returning scalar instead, #but in the future will perform elementwise comparison
# return bool(asarray(a1 == a2).all())
#(None, 2)Input and preprocessing Layers
String Look Up
tf.strings.split(train['Cabin'], "/")[:,-1:].numpy()array([[b'P'],
[b'P'],
[b'S'],
...,
[b'P'],
[b'P'],
[b'P']], dtype=object)inputs = {
'Cabin': tf.keras.Input(shape=(), dtype='string')
}
# 캐빈 데이터를 분할합니다
cabin_split = tf.strings.split(inputs['Cabin'], "/")
# 마지막 요소만 선택합니다
cabin_last = cabin_split.to_tensor()[:, -1]
# StringLookup 레이어를 사용하여 one-hot 인코딩을 수행합니다
cabin_output = tf.keras.layers.StringLookup(vocabulary=["S", "P"], num_oov_indices=1, output_mode='one_hot')(cabin_last)
outputs = {
'Cabin': cabin_output
}
model = tf.keras.Model(inputs, outputs)for t, l in train_ds:
pred = model(t)
print(pred['Cabin'])
breaktf.Tensor(
[[0. 1. 0.]
[0. 1. 0.]
[0. 1. 0.]
[0. 0. 1.]], shape=(4, 3), dtype=float32)
/usr/local/lib/python3.10/dist-packages/keras/src/engine/functional.py:642: UserWarning: Input dict contained keys ['PassengerId', 'HomePlanet', 'CryoSleep', 'Destination', 'Age', 'VIP', 'RoomService', 'FoodCourt', 'ShoppingMall', 'Spa', 'VRDeck', 'Name'] which did not match any model input. They will be ignored by the model.
inputs = self._flatten_to_reference_inputs(inputs)s = "F/575/P"
tf.strings.split(s, sep="/")#<tf.Tensor: shape=(3,), dtype=string, numpy=array([b'F', b'575', b'P'], dtype=object)>list(set(train['HomePlanet']))#['Mars', 'Earth', 'Europa']string_lookup_layer = tf.keras.layers.StringLookup(
vocabulary=list(set(train['HomePlanet'])),
num_oov_indices=0,
output_mode='one_hot')
"""
int 0, 1, 2 (idx)
one_hot [1, 0, 0]
multi_hot [1, 0, 1] (다중입력)
"""
string_lookup_layer(list(train['HomePlanet'].to_numpy()))#<tf.Tensor: shape=(6954, 3), dtype=float32, numpy=
#array([[0., 1., 0.],
# [0., 1., 0.],
# [0., 0., 1.],
# ...,
# [0., 1., 0.],
# [1., 0., 0.],
# [0., 0., 1.]], dtype=float32)>Category Encoding
train['CryoSleep']0 0
1 0
2 1
3 0
4 1
..
6949 0
6950 0
6951 0
6952 0
6953 0
Name: CryoSleep, Length: 6954, dtype: int64one_hot_layer = tf.keras.layers.CategoryEncoding(
num_tokens=2, output_mode='one_hot')
one_hot_layer(list(train['CryoSleep'].to_numpy()))<tf.Tensor: shape=(6954, 2), dtype=float32, numpy=
array([[1., 0.],
[1., 0.],
[0., 1.],
...,
[1., 0.],
[1., 0.],
[1., 0.]], dtype=float32)>Normalization
normalization_layer = tf.keras.layers.Normalization(mean=1.0, variance=10.0)
# 각 입력 값에서 mean 값을 뺍니다. 예를 들어, 입력이 [1., 2., 3.]라면, 결과는 [-2., -1., 0.]이 됩니다.
# 다음으로, 이 결과를 variance의 제곱근 값, 즉 sqrt(2.)로 나눕니다. 따라서 결과는 [-2/sqrt(2), -1/sqrt(2), 0]가 됩니다. (정규화 과정)
print(normalization_layer(train['RoomService'][:5]).numpy())
print(train['RoomService'][:5].to_numpy())#[-0.31622776 -0.31622776 -0.31622776 -0.31622776 -0.31622776]
#[0. 0. 0. 0. 0.]Model Train
preprocessing_model.compile(optimizer=tf.keras.optimizers.Adam(1e-4),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])max_epochs = 150
history = preprocessing_model.fit(train_ds,
epochs=max_epochs,
steps_per_epoch=len(train) // batch_size,
validation_data=test_ds,
validation_steps=len(test) // batch_size)1738/1738 [==============================] - 6s 3ms/step - loss: 0.5712 - accuracy: 0.7172 - val_loss: 0.5622 - val_accuracy: 0.7247
Epoch 144/150
1738/1738 [==============================] - 5s 3ms/step - loss: 0.5745 - accuracy: 0.7145 - val_loss: 0.5625 - val_accuracy: 0.7247
Epoch 145/150
1738/1738 [==============================] - 5s 3ms/step - loss: 0.5732 - accuracy: 0.7158 - val_loss: 0.5622 - val_accuracy: 0.7247
Epoch 146/150
1738/1738 [==============================] - 7s 4ms/step - loss: 0.5716 - accuracy: 0.7168 - val_loss: 0.5623 - val_accuracy: 0.7247
Epoch 147/150
1738/1738 [==============================] - 5s 3ms/step - loss: 0.5734 - accuracy: 0.7155 - val_loss: 0.5628 - val_accuracy: 0.7247
Epoch 148/150
1738/1738 [==============================] - 5s 3ms/step - loss: 0.5690 - accuracy: 0.7185 - val_loss: 0.5622 - val_accuracy: 0.7247
Epoch 149/150
1738/1738 [==============================] - 6s 3ms/step - loss: 0.5718 - accuracy: 0.7184 - val_loss: 0.5621 - val_accuracy: 0.7247
Epoch 150/150
1738/1738 [==============================] - 5s 3ms/step - loss: 0.5727 - accuracy: 0.7142 - val_loss: 0.5621 - val_accuracy: 0.7247
AI, Information and Communication, Electronics, Computer Science, Bio, Algorithms