import tensorflow as tf
from tensorflow.keras import layers
import numpy as np
import matplotlib.pyplot as plt
from IPython.display import clear_output
import os
import time
tf.__version__#2.15.0Data preprocessing
# Load training and eval data from tf.keras
(train_data, train_labels), (test_data, test_labels) = \
tf.keras.datasets.mnist.load_data()
train_data = train_data / 255.
train_data = train_data.reshape([-1, 28, 28, 1])
train_data = train_data.astype(np.float32)
train_labels = train_labels.astype(np.int32)
test_data = test_data / 255.
test_data = test_data.reshape([-1, 28, 28, 1])
test_data = test_data.astype(np.float32)
test_labels = test_labels.astype(np.int32)#Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-#datasets/mnist.npz
#11490434/11490434 [==============================] - 0s 0us/stepindex = 219
print("label = {}".format(train_labels[index]))
plt.imshow(train_data[index][...,0])
plt.colorbar()
#plt.gca().grid(False)
plt.show()
def one_hot_label(image, label):
label = tf.one_hot(label, depth=10)
return image, labelMake a dataset
batch_size = 32
max_epochs = 10
# for train
N = len(train_data)
train_dataset = tf.data.Dataset.from_tensor_slices((train_data, train_labels))
train_dataset = train_dataset.shuffle(buffer_size=10000)
train_dataset = train_dataset.map(one_hot_label)
train_dataset = train_dataset.batch(batch_size=batch_size)
print(train_dataset)
# for test
test_dataset = tf.data.Dataset.from_tensor_slices((test_data, test_labels))
test_dataset = test_dataset.map(one_hot_label)
test_dataset = test_dataset.batch(batch_size=batch_size)
print(test_dataset)#<_BatchDataset element_spec=(TensorSpec(shape=(None, 28, 28, 1), dtype=tf.float32, name=None), TensorSpec(shape=(None, 10), dtype=tf.float32, name=None))>
#<_BatchDataset element_spec=(TensorSpec(shape=(None, 28, 28, 1), dtype=tf.float32, name=None), TensorSpec(shape=(None, 10), dtype=tf.float32, name=None))>Make a model
class Conv(tf.keras.Model):
def __init__(self, num_filters, kernel_size):
super(Conv, self).__init__()
self.conv_1 = layers.Conv2D(num_filters, kernel_size, padding='same')
self.conv_2 = layers.Conv2D(num_filters, kernel_size, padding='same')
self.bn_1 = layers.BatchNormalization()
def call(self, inputs, training=True): # flag 표시
x = self.conv_1(inputs)
x = self.bn_1(x, training=training)
x = layers.ReLU()(x)
x = self.conv_2(x)
x = layers.ReLU()(x)
x = layers.MaxPooling2D()(x)
return x
class Conv_model(tf.keras.Model):
def __init__(self):
super(Conv_model, self).__init__()
self.conv_1 = Conv(16, 3) # 레이어 추가 구성 방법 conv-conv-pooling
self.conv_2 = Conv(32, 3)
self.dense_1 = layers.Dense(64, activation='relu')
self.dense_2 = layers.Dense(64, activation='relu')
self.outputs = layers.Dense(10, activation='softmax')
def call(self, inputs, training=True):
x = self.conv_1(inputs)
x = self.conv_2(x)
x = layers.Flatten()(x)
x = self.dense_1(x)
x = self.dense_2(x)
x = self.outputs(x)
return x
model = Conv_model()# without training, just inference a model in eager execution:
for images, labels in train_dataset.take(1):
predictions = model(images[0:1], training=False)
print("Predictions: ", predictions.numpy())#Predictions: [[0.09250367 0.09722731 0.10706629 0.09343273 0.09928532 #0.10239314
# 0.10158375 0.09787221 0.10616878 0.10246678]]model.summary()Model: "conv_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv (Conv) multiple 2544
conv_1 (Conv) multiple 14016
dense (Dense) multiple 100416
dense_1 (Dense) multiple 4160
dense_2 (Dense) multiple 650
=================================================================
Total params: 121786 (475.73 KB)
Trainable params: 121690 (475.35 KB)
Non-trainable params: 96 (384.00 Byte)
_________________________________________________________________Training
loss_object = tf.keras.losses.CategoricalCrossentropy()
acc_object = tf.keras.metrics.CategoricalAccuracy()# use Adam optimizer
optimizer = tf.keras.optimizers.Adam(1e-4)
# record loss and accuracy for every epoch
mean_loss = tf.keras.metrics.Mean("loss")
mean_accuracy = tf.keras.metrics.Mean("accuracy")
# save loss and accuracy history for plot
loss_history = []
accuracy_history = [(0, 0.0)]print("start training!")
global_step = tf.Variable(0, trainable=False)
num_batches_per_epoch = int(N / batch_size)
for epoch in range(max_epochs):
for step, (images, labels) in enumerate(train_dataset):
start_time = time.time()
with tf.GradientTape() as tape:
predictions = model(images, training=True)
loss_value = loss_object(labels, predictions)
acc_value = acc_object(labels, predictions)
grads = tape.gradient(loss_value, model.trainable_variables)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
global_step.assign_add(1)
mean_loss(loss_value)
mean_accuracy(acc_value)
loss_history.append((global_step.numpy(), mean_loss.result().numpy()))
if global_step.numpy() % 10 == 0:
clear_output(wait=True)
epochs = epoch + step / float(num_batches_per_epoch)
duration = time.time() - start_time
examples_per_sec = batch_size / float(duration)
print("epochs: {:.2f}, step: {}, loss: {:.3g}, accuracy: {:.4g}% ({:.2f} examples/sec; {:.4f} sec/batch)".format(
epochs, global_step.numpy(), loss_value.numpy(), acc_value.numpy()*100, examples_per_sec, duration))
# save mean accuracy for plot
accuracy_history.append((global_step.numpy(), mean_accuracy.result().numpy()))
# clear the history
mean_accuracy.reset_states()
print("training done!")#epochs: 10.00, step: 18750, loss: 0.0239, accuracy: 98.32% (667.71 examples/sec; 0.0479 sec/batch)
#training done!History
plt.plot(*zip(*loss_history), label='loss')
plt.xlabel('Number of steps')
plt.ylabel('Loss value [cross entropy]')
plt.legend()
plt.show()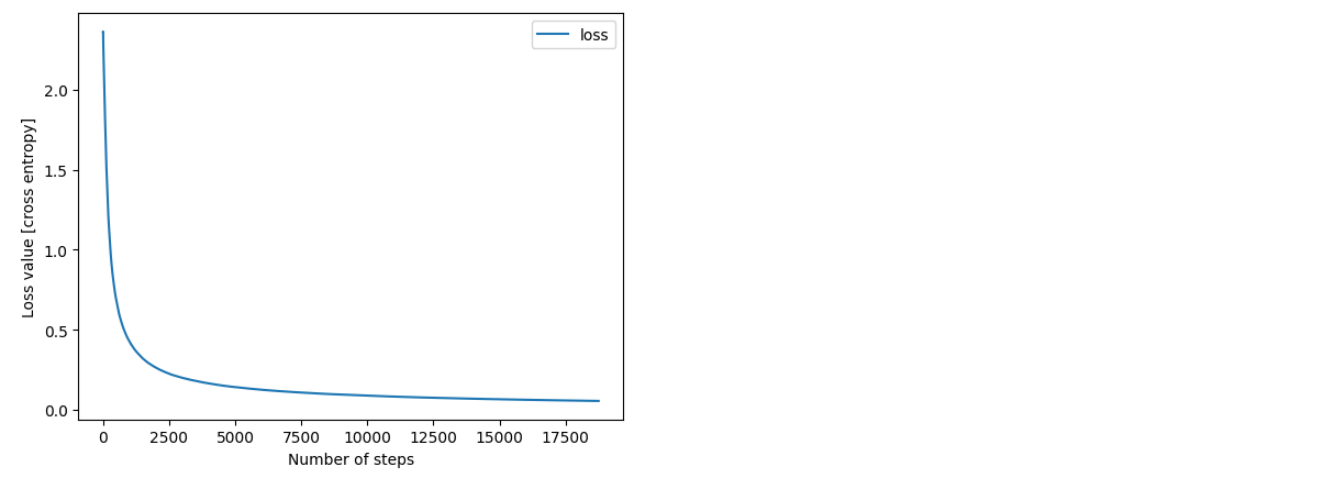
plt.plot(*zip(*accuracy_history), label='accuracy')
plt.xlabel('Number of steps')
plt.ylabel('Accuracy value')
plt.legend()
plt.show()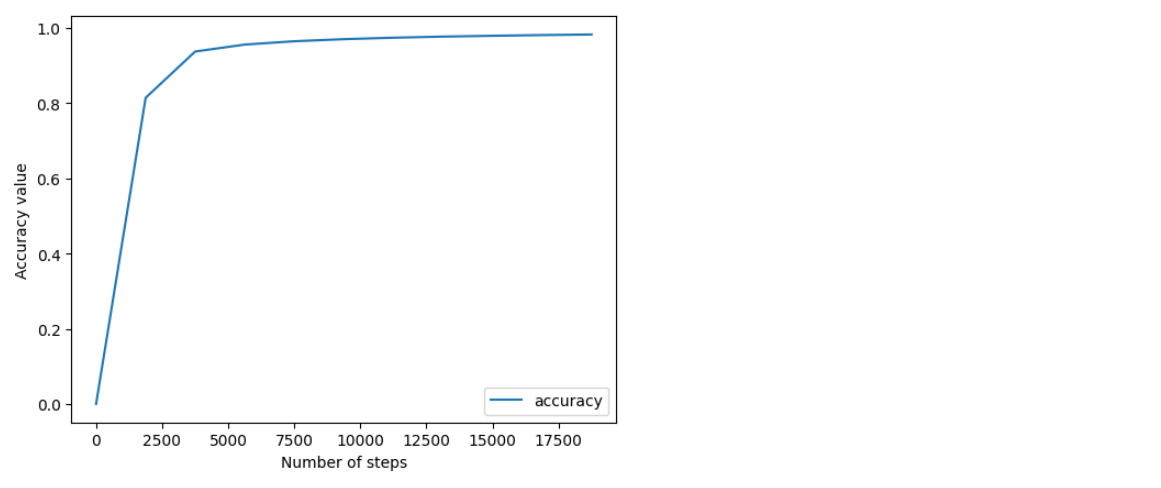
결과 확인
np.random.seed(219)
test_batch_size = 16
batch_index = np.random.choice(len(test_data), size=test_batch_size, replace=False)
batch_xs = test_data[batch_index]
batch_ys = test_labels[batch_index]
y_pred_ = model(batch_xs, training=False)
fig = plt.figure(figsize=(16, 10))
for i, (px, py) in enumerate(zip(batch_xs, y_pred_)):
p = fig.add_subplot(4, 8, i+1)
if np.argmax(py) == batch_ys[i]:
p.set_title("y_pred: {}".format(np.argmax(py)), color='blue')
else:
p.set_title("y_pred: {}".format(np.argmax(py)), color='red')
p.imshow(px.reshape(28, 28))
p.axis('off')

AI, Information and Communication, Electronics, Computer Science, Bio, Algorithms