import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.callbacks import ReduceLROnPlateau
import numpy as np
import matplotlib.pyplot as plt
from IPython.display import clear_output
import os
import sys
import time
import shutil
import PIL
tf.__version__#2.15.0이미지넷에 사용됐던 CNN layers를 사용해보자
Usage VGG16
def VGG16(include_top=True, weights='imagenet', input_tensor=None, input_shape=None, pooling=None, classes=1000, **kwargs): """Instantiates the VGG16 architecture. Optionally loads weights pre-trained on ImageNet. Note that the data format convention used by the model is the one specified in your Keras config at `~/.keras/keras.json`. # Arguments include_top: whether to include the 3 fully-connected layers at the top of the network. weights: one of `None` (random initialization), 'imagenet' (pre-training on ImageNet), or the path to the weights file to be loaded. input_tensor: optional Keras tensor (i.e. output of `layers.Input()`) to use as image input for the model. input_shape: optional shape tuple, only to be specified if `include_top` is False (otherwise the input shape has to be `(224, 224, 3)` (with `channels_last` data format) or `(3, 224, 224)` (with `channels_first` data format). It should have exactly 3 input channels, and width and height should be no smaller than 32. E.g. `(200, 200, 3)` would be one valid value. pooling: Optional pooling mode for feature extraction when `include_top` is `False`. - `None` means that the output of the model will be the 4D tensor output of the last convolutional block. - `avg` means that global average pooling will be applied to the output of the last convolutional block, and thus the output of the model will be a 2D tensor. - `max` means that global max pooling will be applied. classes: optional number of classes to classify images into, only to be specified if `include_top` is True, and if no `weights` argument is specified. # Returns A Keras model instance. # Raises ValueError: in case of invalid argument for `weights`, or invalid input shape. """
conv_base = tf.keras.applications.VGG16(weights='imagenet',
include_top=False,
input_shape=(150, 150, 3)) #224, 224, 3
conv_base.trainable = False#Downloading data from #https://storage.googleapis.com/tensorflow/keras-applications/vgg16/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5
#58889256/58889256 [==============================] - 1s 0us/stepconv_base.summary()Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 150, 150, 3)] 0
block1_conv1 (Conv2D) (None, 150, 150, 64) 1792
block1_conv2 (Conv2D) (None, 150, 150, 64) 36928
block1_pool (MaxPooling2D) (None, 75, 75, 64) 0
block2_conv1 (Conv2D) (None, 75, 75, 128) 73856
block2_conv2 (Conv2D) (None, 75, 75, 128) 147584
block2_pool (MaxPooling2D) (None, 37, 37, 128) 0
block3_conv1 (Conv2D) (None, 37, 37, 256) 295168
block3_conv2 (Conv2D) (None, 37, 37, 256) 590080
block3_conv3 (Conv2D) (None, 37, 37, 256) 590080
block3_pool (MaxPooling2D) (None, 18, 18, 256) 0
block4_conv1 (Conv2D) (None, 18, 18, 512) 1180160
block4_conv2 (Conv2D) (None, 18, 18, 512) 2359808
block4_conv3 (Conv2D) (None, 18, 18, 512) 2359808
block4_pool (MaxPooling2D) (None, 9, 9, 512) 0
block5_conv1 (Conv2D) (None, 9, 9, 512) 2359808
block5_conv2 (Conv2D) (None, 9, 9, 512) 2359808
block5_conv3 (Conv2D) (None, 9, 9, 512) 2359808
block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
=================================================================
Total params: 14714688 (56.13 MB)
Trainable params: 0 (0.00 Byte)
Non-trainable params: 14714688 (56.13 MB)
_________________________________________________________________VGG를 이용한 모델 구성
model = tf.keras.Sequential()
model.add(conv_base)
model.add(layers.Flatten())
model.add(layers.Dense(256, activation='relu'))
model.add(layers.Dense(5, activation='softmax'))
model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
vgg16 (Functional) (None, 4, 4, 512) 14714688
flatten (Flatten) (None, 8192) 0
dense (Dense) (None, 256) 2097408
dense_1 (Dense) (None, 5) 1285
=================================================================
Total params: 16813381 (64.14 MB)
Trainable params: 2098693 (8.01 MB)
Non-trainable params: 14714688 (56.13 MB)
_________________________________________________________________- 학습할 파라미터를 지정해준다
# assign conv1_1 and dense1 weight to compare itself after training some steps
for var in model.variables:
#print(var.name)
if var.name == 'block1_conv1/kernel:0':
conv1_1_w = var
if var.name == 'dense/kernel:0':
dense_w = varprint(conv1_1_w)
print(dense_w)<tf.Variable 'block1_conv1/kernel:0' shape=(3, 3, 3, 64) dtype=float32, numpy=
array([[[[ 4.29470569e-01, 1.17273867e-01, 3.40129584e-02, ...,
-1.32241577e-01, -5.33475243e-02, 7.57738389e-03],
[ 5.50379455e-01, 2.08774377e-02, 9.88311544e-02, ...,
-8.48205537e-02, -5.11389151e-02, 3.74943428e-02],
[ 4.80015397e-01, -1.72696680e-01, 3.75577137e-02, ...,
-1.27135560e-01, -5.02991639e-02, 3.48965675e-02]],
[[ 3.73466998e-01, 1.62062630e-01, 1.70863140e-03, ...,
-1.48207128e-01, -2.35300660e-01, -6.30356818e-02],
[ 4.40074533e-01, 4.73412387e-02, 5.13819456e-02, ...,
-9.88498852e-02, -2.96195745e-01, -7.04357103e-02],
[ 4.08547401e-01, -1.70375049e-01, -4.96297423e-03, ...,
-1.22360572e-01, -2.76450396e-01, -3.90796512e-02]],
[[-6.13601133e-02, 1.35693997e-01, -1.15694344e-01, ...,
-1.40158370e-01, -3.77666801e-01, -3.00509870e-01],
[-8.13870355e-02, 4.18543853e-02, -1.01763301e-01, ...,
-9.43124294e-02, -5.05662560e-01, -3.83694321e-01],
[-6.51455522e-02, -1.54351532e-01, -1.38038069e-01, ...,
-1.29404560e-01, -4.62243795e-01, -3.23985279e-01]]],
[[[ 2.74769872e-01, 1.48350164e-01, 1.61559835e-01, ...,
-1.14316158e-01, 3.65494519e-01, 3.39938998e-01],
[ 3.45739067e-01, 3.10493708e-02, 2.40750551e-01, ...,
-6.93419054e-02, 4.37116861e-01, 4.13171440e-01],
[ 3.10477257e-01, -1.87601492e-01, 1.66595340e-01, ...,
-9.88388434e-02, 4.04058546e-01, 3.92561197e-01]],
[[ 3.86807770e-02, 2.02298447e-01, 1.56414255e-01, ...,
-5.20089604e-02, 2.57149011e-01, 3.71682674e-01],
[ 4.06322069e-02, 6.58102185e-02, 2.20311403e-01, ...,
-3.78979952e-03, 2.69412428e-01, 4.09505904e-01],
[ 5.02023660e-02, -1.77571565e-01, 1.51188180e-01, ...,
-1.40649760e-02, 2.59300828e-01, 4.23764467e-01]],
[[-3.67223352e-01, 1.61688417e-01, -8.99365395e-02, ...,
-1.45945460e-01, -2.71823555e-01, -2.39718184e-01],
[-4.53501314e-01, 4.62574959e-02, -6.67438358e-02, ...,
-1.03502415e-01, -3.45792353e-01, -2.92486250e-01],
[-4.03383434e-01, -1.74399972e-01, -1.09849639e-01, ...,
-1.25688612e-01, -3.14026326e-01, -2.32839763e-01]]],
[[[-5.74681684e-02, 1.29344285e-01, 1.29030216e-02, ...,
-1.41449392e-01, 2.41099641e-01, 4.55602147e-02],
[-5.86349145e-02, 3.16787697e-02, 7.59588331e-02, ...,
-1.05017252e-01, 3.39550197e-01, 9.86374393e-02],
[-5.08716851e-02, -1.66002661e-01, 1.56279504e-02, ...,
-1.49742723e-01, 3.06801915e-01, 8.82701725e-02]],
[[-2.62249678e-01, 1.71572417e-01, 5.44555223e-05, ...,
-1.22728683e-01, 2.44687453e-01, 5.32913655e-02],
[-3.30669671e-01, 5.47101051e-02, 4.86797579e-02, ...,
-8.29023942e-02, 2.95466095e-01, 7.44469985e-02],
[-2.85227507e-01, -1.66666731e-01, -7.96697661e-03, ...,
-1.09780088e-01, 2.79203743e-01, 9.46525261e-02]],
[[-3.50096762e-01, 1.38710454e-01, -1.25339806e-01, ...,
-1.53092295e-01, -1.39917329e-01, -2.65075237e-01],
[-4.85030204e-01, 4.23195846e-02, -1.12076312e-01, ...,
-1.18306056e-01, -1.67058021e-01, -3.22241962e-01],
[-4.18516338e-01, -1.57048807e-01, -1.49133086e-01, ...,
-1.56839803e-01, -1.42874300e-01, -2.69694626e-01]]]],
dtype=float32)>
<tf.Variable 'dense/kernel:0' shape=(8192, 256) dtype=float32, numpy=
array([[-0.01825942, -0.01089548, -0.01827931, ..., 0.01217642,
0.02104451, 0.02571083],
[ 0.02347707, -0.02053702, 0.00575858, ..., -0.01172319,
-0.00517421, 0.02240798],
[-0.01211199, 0.01029826, 0.01574237, ..., -0.00506912,
-0.0087126 , 0.00250893],
...,
[ 0.01723271, -0.00554627, -0.02466685, ..., -0.00836672,
-0.00086973, -0.00560887],
[ 0.0224471 , -0.00484353, -0.00065107, ..., 0.00981319,
-0.00723724, 0.00493208],
[ 0.01304039, 0.00330737, 0.00299323, ..., -0.00509469,
0.0249224 , -0.01431333]], dtype=float32)>모델 학습 파라미터 지정
- 이미 학습된 CNN layer의 파라미터는 학습이 되지않도록 설정해야한다.
# Freeze vgg16 conv base part (means that trainable option is False)
for layer in model.layers:
if layer.name == 'vgg16':
layer.trainable = False
print("variable name: {}, trainable: {}".format(layer.name, layer.trainable))variable name: vgg16, trainable: False
variable name: flatten, trainable: True
variable name: dense, trainable: True
variable name: dense_1, trainable: True테스트용 데이터셋 다운로드
- 꽃 이미지 데이터셋
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file('flower_photos', origin=dataset_url, untar=True)
data_dir = pathlib.Path(data_dir)#Downloading data from #https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz
#228813984/228813984 [==============================] - 3s 0us/stepimage_count = len(list(data_dir.glob('*/*.jpg')))
print(image_count)#3670roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[0]))
tulips = list(data_dir.glob('tulips/*'))
PIL.Image.open(str(tulips[0]))
batch_size = 32
img_height = 150
img_width = 150
max_epochs = 10 train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)#Found 3670 files belonging to 5 classes.
#Using 2936 files for training. val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)#Found 3670 files belonging to 5 classes.
#Using 734 files for validation.
class_names = train_ds.class_names
print(class_names)['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
데이터 전처리 파트
- 모델 데이터에 맞도록 데이터를 0~1 사이 값으로 Normalization
AUTOTUNE = tf.data.experimental.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)normalization_layer = layers.experimental.preprocessing.Rescaling(1./255)
normalized_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(normalized_ds))
first_image = image_batch[0]
# Notice the pixels values are now in `[0,1]`.
print(np.min(first_image), np.max(first_image))#0.0 1.0모델 학습
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False), # from_logits 마지막 레이어의 activation 여부
metrics=['accuracy'])keras callback 함수
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.2,
patience=5, min_lr=0.001)
early_stopping = tf.keras.callbacks.EarlyStopping(monitor='val_accuracy', patience=3)history = model.fit(
train_ds,
validation_data=val_ds,
callbacks=[reduce_lr, early_stopping],
epochs=max_epochs
)Epoch 1/10
92/92 [==============================] - 26s 213ms/step - loss: 3.8655 - accuracy: 0.6945 - val_loss: 0.7988 - val_accuracy: 0.7316 - lr: 0.0010
Epoch 2/10
92/92 [==============================] - 8s 82ms/step - loss: 0.3244 - accuracy: 0.8944 - val_loss: 0.7850 - val_accuracy: 0.8011 - lr: 0.0010
Epoch 3/10
92/92 [==============================] - 8s 82ms/step - loss: 0.0967 - accuracy: 0.9676 - val_loss: 0.9738 - val_accuracy: 0.7943 - lr: 0.0010
Epoch 4/10
92/92 [==============================] - 8s 83ms/step - loss: 0.0410 - accuracy: 0.9857 - val_loss: 0.9290 - val_accuracy: 0.8079 - lr: 0.0010
Epoch 5/10
92/92 [==============================] - 8s 83ms/step - loss: 0.0134 - accuracy: 0.9956 - val_loss: 0.9703 - val_accuracy: 0.8093 - lr: 0.0010
Epoch 6/10
92/92 [==============================] - 8s 84ms/step - loss: 0.0083 - accuracy: 0.9980 - val_loss: 0.9819 - val_accuracy: 0.8106 - lr: 0.0010
Epoch 7/10
92/92 [==============================] - 8s 85ms/step - loss: 0.0049 - accuracy: 0.9986 - val_loss: 0.9677 - val_accuracy: 0.8188 - lr: 0.0010
Epoch 8/10
92/92 [==============================] - 8s 84ms/step - loss: 0.0031 - accuracy: 0.9990 - val_loss: 0.9921 - val_accuracy: 0.8147 - lr: 0.0010
Epoch 9/10
92/92 [==============================] - 8s 84ms/step - loss: 0.0022 - accuracy: 0.9997 - val_loss: 1.0182 - val_accuracy: 0.8161 - lr: 0.0010
Epoch 10/10
92/92 [==============================] - 8s 84ms/step - loss: 0.0015 - accuracy: 0.9997 - val_loss: 1.0547 - val_accuracy: 0.8161 - lr: 0.0010print(history.history.keys())
len_res = len(history.history['accuracy'])
print(len_res)#dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy', 'lr'])
#10# Compare weights between before and after training some steps
for var in model.variables:
#print(var.name)
if var.name == 'block1_conv1/kernel:0':
conv1_1_w_1 = var
if var.name == 'dense/kernel:0':
dense_w_1 = varacc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss=history.history['loss']
val_loss=history.history['val_loss']
epochs_range = range(len_res)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()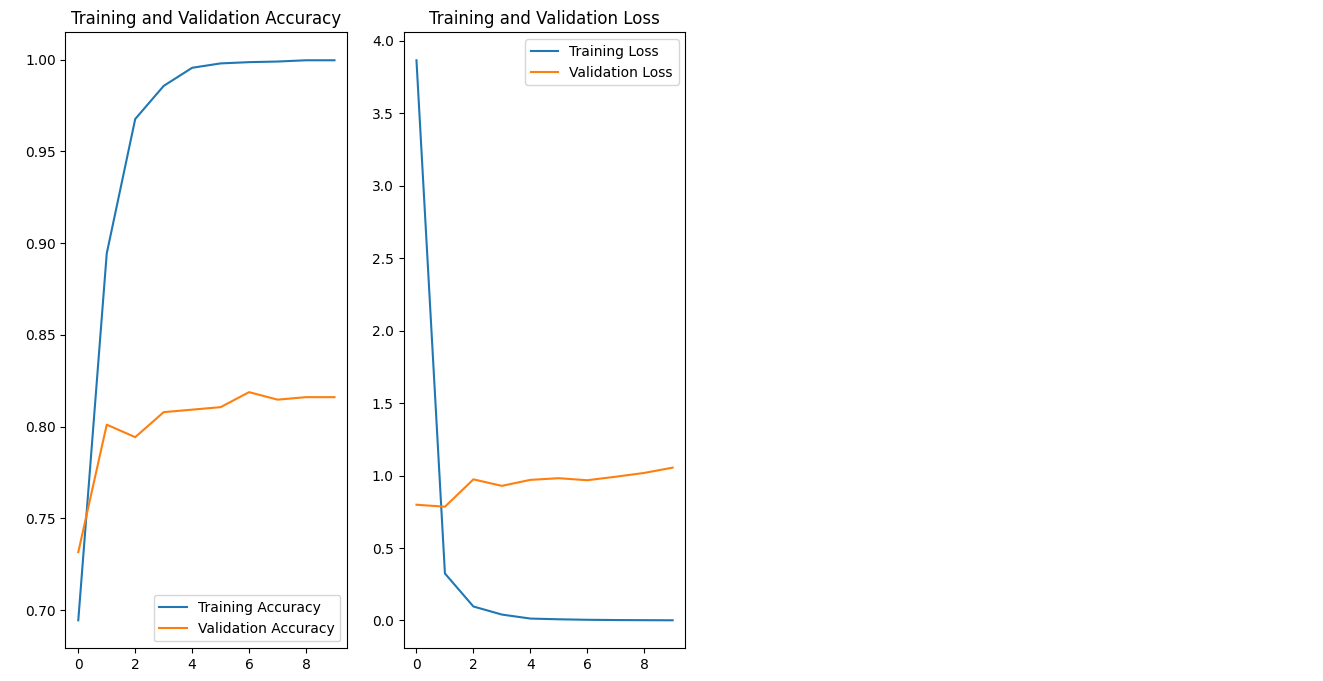
history = model.evaluate(val_ds)23/23 [==============================] - 2s 66ms/step - loss: 1.0547 - accuracy: 0.8161# loss
print("loss value: {:.3f}".format(history[0]))
# accuracy
print("accuracy value: {:.3f}".format(history[1]))#loss value: 1.055
#accuracy value: 0.816
AI, Information and Communication, Electronics, Computer Science, Bio, Algorithms