
5. 배열 생성 및 초기화
- 범위와 조건이 있는 데이터를 가지는 1차원 배열 생성합니다.
- np.linspace()
- np.arange()
- np.logspace()
-
2-1. np.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
- 시작값(start)부터 마지막값(stop) 사이의 범위에서 균등한 간격으로 일정 개수(num)개의 데이터를 가지는 배열 생성합니다.
- num : 데이터 개수, 기본값 = 50
- endpoint : 마지막값에 stop을 포함/제외하는 조건 지정, 기본값 = True(포함)
- retstep : True로 전달하면 (배열, 데이터 사이의 간격)의 데이터를 담은 tuple을 반환
- dtype : 배열의 데이터 타입을 지정, 기본값 = None

- 0이상 1이하의 범위에서 발생한 숫자 5개를 포함하는 배열로 0이 시작점입니다.
- 범위 안에서 지정한 등분(5)로 나눈 값을 출력합니다.
- 다만 보통 끝지점이 포함이 안되는 파이썬의 기본 문법과는 다르게 여기선 포함이 되는 모습을 보입니다.
- 만약 파이썬 기본 문법처럼 끝지점 숫자를 포함하지 않고자 할때 endpoint를 False로 변환하면 됩니다.

- retstep 설정 -> 반환값 tuple => (배열객체, 간격값) => 출력에서 간격값을 보여준다는 점에서 활용이 가능합니다.

-
2-2. np.arange(start=0, stop, step=1, dtype=None)
-
시작값(start)부터 마지막값(stop) 사이의 범위에서 지정한 간격(step)으로 일정 개수(num)개의 데이터를 가지는 배열을 생성하는 함수입니다.
-
파이썬 내장함수 range()와 유사하다고 보면 됩니다.
- start : 시작값, 기본값 = 0
- stop : 마지막값으로 범위에 포함되지 않음
- step : 데이터 사이의 간격, 기본값 = 1
- dtype : 배열의 데이터 타입을 지정, 기본값 = None
-
0이상 5미만의 범위에서 1식 증가하는 숫자(정수)를 가지는 배열을 생성해봅시다. (리스트함수와 비교)
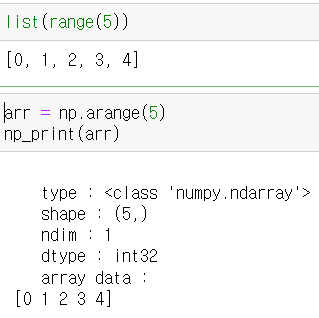
-
arange() 메서드로 생성된 배열과 shape(1, 5)인 배열은 동일해 보이지만 shape와 dimension이 서로 다릅니다.
- 그냥 내부자료가 4개짜리 배열 (arnage()) - ndim : 1

- 1X4 배열 (reshape()) - ndim : 2

- 그냥 내부자료가 4개짜리 배열 (arnage()) - ndim : 1
-
-
2-3 np.logspace(start, stop, num=50, endpoint=True, dtype=None)
- 시작값(start)부터 마지막값(stop) 사이의 로그 스케일로 지정된 범위에서 균등한 간격으로 일정 개수(num)개의 데이터를 가지는 배열 생성하는 함수입니다.
- num : 데이터 개수, 기본값 = 50
- endpoint : 마지막 값에 stop을 포함/제외하는 조건 지정, 기본값 = True(포함)
- dtype : 배열의 데이터 타입을 지정, 기본값 = None
- 로그의 등장
- 밑의 함수의 의미는 0부터 시작해서 10의 3승(1000) 사이의 값 중 로그값으로 균등하게 4개를 출력하시오의 의미입니다.
- 즉 log10의 0승 1승 2승 3승을 출력하게 되는 것입니다.
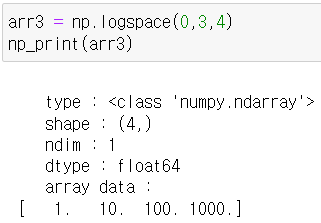
- 마지막 숫자를 포함하지 않으려면 위에서 썼듯 endpoint = False를 설정해두면 됩니다.
- 시작값(start)부터 마지막값(stop) 사이의 로그 스케일로 지정된 범위에서 균등한 간격으로 일정 개수(num)개의 데이터를 가지는 배열 생성하는 함수입니다.
참고
분산과 표준편차
분산과 표준편차
어떤 집단간 평균이 같다고해서 반드시 분포가 같지는 않습니다.
평균에서 어떤 요소가 얼마나 멀리 떨어져있는지를 나타내는 분산값을 구한 다음
분산에 제곱근을 씌워 표준편차를 구하면 비로소 분포가 눈에 보입니다.
평균, 분산, 표준편차를 통해 상대평가가 가능합니다.
6. 배열 생성 및 초기화
-
난수(특정한 순서나 규칙을 가지지 않는 무작위의 수)를 데이터로 가지는 배열을 생성합니다.
- np.random.normal()
- np.random.rand()
- np.random.randn()
- np.random.randint()
- np.random.random()
-
3-1. np.random.normal(loc=0.0, scale=1.0, size=None)
- [정규 분포] 확률 밀도에서 표본을 추출하여 데이터로 가지는 배열을 생성합니다.
- loc : 정규분포의 평균, 기본값 = 0.0
- scale : 정규분포의 표준편차, 기본값 = 1.0
- size : (행,열,차원)의 배열 구조, 기본값 = single value(배열이 아닌 하나의 값을 반환)
- 평균 0 표준편차 1인 난수를 뽑아봅시다.
- 물론 2나 3 같은 숫자가 나올 수 있지만
- 보통 1 ~ 1 사이값은 10번에 7번정도 나온다.
(제 1 표준편차 : 68.2%)

- 여기서 size를 설정하여 행렬로 표현할 수도 있다.
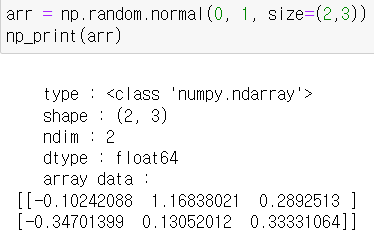
- 특이한 점은 사이즈 적용시 iterator면 적용이 가능하기 때문에 리스트 형식으로 넣어도 작동이 가능합니다. (iterator : for문에 적용이 가능한 반복가능한 자료형식)
- 시각화
- 위의 랜덤함수로 출력된 자료들을 시각화해봅시다.
- 정규분포 데이터로 이루어진 배열에 대한 시각화
- 예제 : 평균 10, 표준편차 2인 정규분포에서 추출한 10000개의 데이터 (표준편차 1 인 정규분포를 표준 정규분포라고 한다.)
- 함수 설정
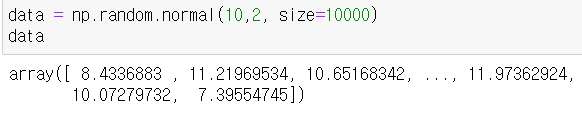
- 시각화 라이브러리 불러오기(matplotlib) 및 시각화 작업

- [정규 분포] 확률 밀도에서 표본을 추출하여 데이터로 가지는 배열을 생성합니다.
-
3-2 np.random.rand(d0, d1, ..., dn)
- 지정한 shape(d0, d1...)에 따라 배열을 생성한 후 난수로 초기화 합니다.
- 사용되는 난수는 0 이상 1미만의 범위에서 [균등 분포]로 추출하는 함수 입니다.
- 2행 3열 구조로 난수 추출을 해봅시다.

- 시각화 예제 (10000개의 데이터를 10개 구간으로 시각화)
- 고정 범위에서 난수를 추출하고 이를 시각화해봅시다.
- 균등분포이므로 그래프의 높이가 비슷할 것을 예상합니다.
 (먼저 난수를 추출합니다.)
(먼저 난수를 추출합니다.)
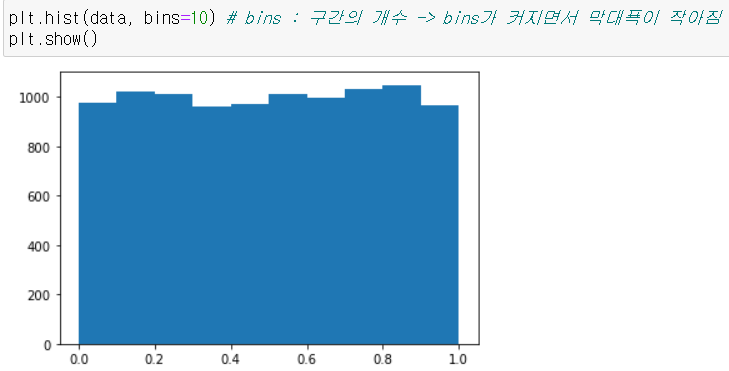 (예측대로 그래프가 거의 균일한 것을 볼 수 있습니다.)
(예측대로 그래프가 거의 균일한 것을 볼 수 있습니다.) - 기타 활용 (평균, 분산)

- 시각화 예제 (10000개의 데이터를 10개 구간으로 시각화)
참고사항 : Numpy 배열은 곱하기를 받았을 때 반복해서 연장하는 것이 아니라 내장된 데이터 하나하나에 곱해줍니다.
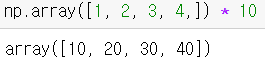
-
3-3 np.random.randn(d0, d1, ..., dn)
- 지정한 shape(d0, d1...)에 따라 배열을 생성한 후 난수로 초기화합니다.
- 사용되는 난수는 표준정규분포에서 추출된 데이터입니다.
- 평균 0 표준편차 1의 조건에서 2행 4열의 shape으로 난수를 출력해봅시다.

- randn 시각화 (10000개 데이터, 100개 구간)
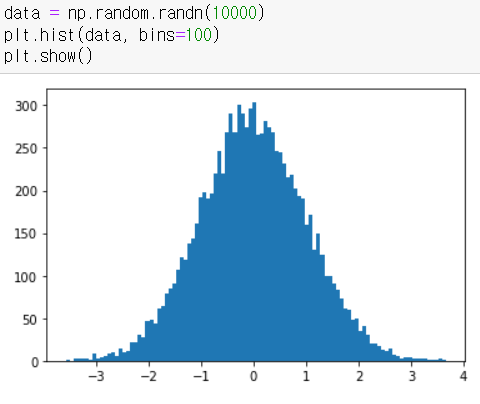
-
3-4 np.random.randint(low, high=None, size=None, dtype='I')
- low 이상 high 미만의 범위에서 정수로 구성된 데이터를 가지고 지정한 size의 배열을 생성합니다.
- low : high 값이 지정되지 않으면 low 값이 최대값(포함하지 않음)으로 설정됩니다.
- high : 최대값(포함하지 않음), 기본값 = None
- size : 배열의 구조, 기본값 = None (배열이 아닌 하나의 값으로 반환)
- 예제 : 3 미만의 양수를 10개 무작위로 추출해봅시다.
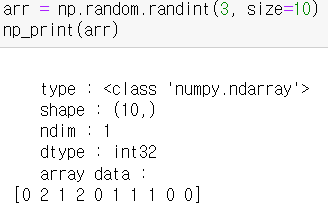
- 이걸 응용해서 Numpy 신에게 이번주 로또번호를 점지받아 봅시다.
- 출력 shape 형식을 추가해서 출력해봅시다.(4~10/2행4열)

- 예제 : 3 미만의 양수를 10개 무작위로 추출해봅시다.
7. ※ 난수 = 무작위 숫자
-
프로그래밍에서 추출되는 난수는 무작위로 만들어진 것처럼 보이지만 실제로는 고정된 기준(시작점)을 가지고 규칙적으로 생성됩니다.
-
시작점을 설정한다면 동일한 난수를 똑같이 생성 가능합니다.
-
난수의 시작점 설정 : np_random.seed()

- 시작점을 설정 후 두 컴퓨터에서 0~1사이의 값들인 3행 3열의 난수를 출력하였더니 같은 출력값이 산출되었습니다.
- 이러한 고정 산출을 해제하려면 다시 np_random.seed() 함수를 입력하여 시작점 설정을 해제할 수 있습니다.
