
Numpy 연산
Numpy도 연산이 가능합니다.
1. 산술 연산
1) 산술연산의 종류
- 더하기 : +, add()
- 빼기 : -, subtract()
- 나누기 : /, divide()
- 곱하기 : *, multiply()
- 지수곱 표현 : exp()
- 제곱근 : sqrt()
- 로그 : log()
- 내적(행렬곱) : dot()
행렬 생성
- 산술 연산을 진행할 a, b 두개의 행렬을 생성합니다.
- a : 1 ~ 9 사이 3x3 행렬

- b : 4 ~ 12 사이 3x3 행렬

- c : 10 ~ 21 사이 3x4 행렬

- a : 1 ~ 9 사이 3x3 행렬
(1) 더하기
- 배열 + 배열
- np.add(arr1, arr2)

- c는 a, b 와 다르게 3x4 배열로 자료 개수가 맞지 않으므로 에러 출력 이는 다른 산술 연산도 동일
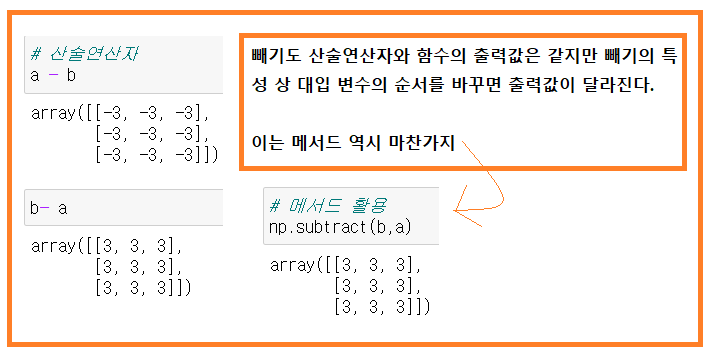
(2) 빼기
- 배열 - 배열
- np.subtract(arr1, arr2)
(3)나누기
- 배열 / 배열
- np.divide(arr1, arr2)
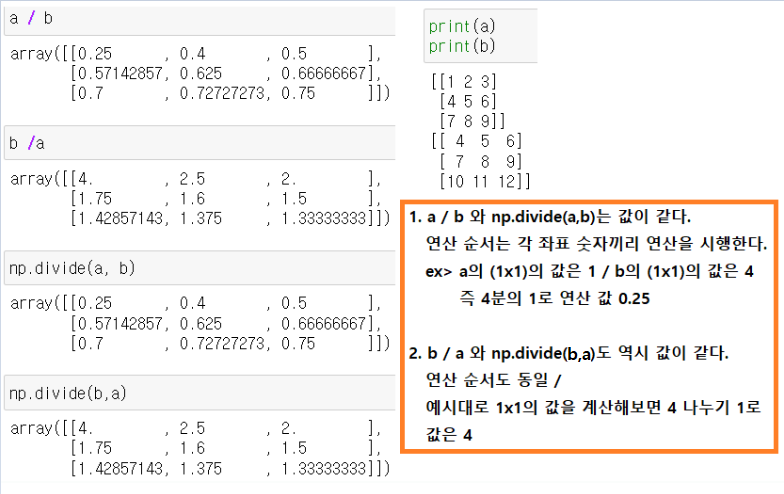
- 특이점은 두 연산 모두 값이 1을 향해 가고 있다 (극한값이 1에 가까워지고 있다.)
(4)곱하기
- 배열 * 배열
- np.multiply(arr1, arr2)
- 곱하기 역시 방식은 동일하다.

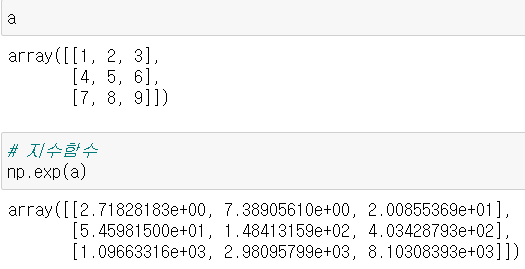
(5)지수곱 표현
-
지수(exponent) : 부동 소수점으로 숫자를 표시할 때 거듭제곱을 사용하여 표현.
- (예) 2.14e+2 = 2.14 x 102 = 214 / 2.98e-8 = 2.98 x 10-8 = 0.0000000298
-
np.exp(arr) : 밑(base)이 자연상수 e 인 지수함수로 변환(y = e**x)
-
매우 어렵기 때문에 정확한 이해는 다음에 하기로 한다.
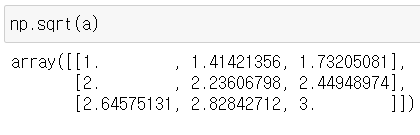
(6)제곱근

- 1의 제곱근은 1입니다. (1x1에서 확인)
- 9의 제곱근은 3입니다. (3x3에서 확인)
(7)행렬곱
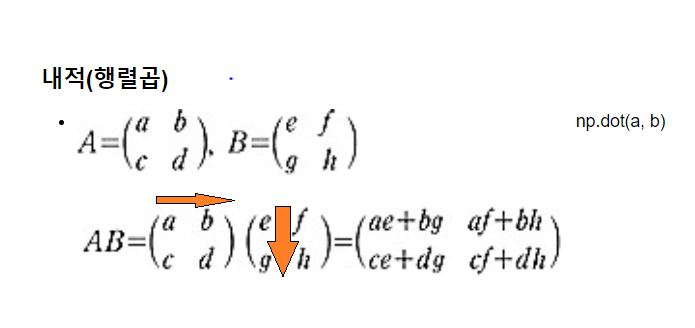

2. 비교 연산
-
1) 요소 (같은 좌표에 있는 자료들끼리 비교)
-
값에 대한 비교 : ==, !=
-
크기에 대한 비교 : >, <, >=, <=
-
-
2) 배열 (배열 간의 비교)
- 두 배열 전체에 대한 비교 : array_equal(a, b)
-
비교연산에서는 출력값이 참/거짓으로 도출이 된다.

3. Numpy 배열 연산
- 3) 집계 함수
- Numpy 배열에 대해 집계 함수를 적용할 때는 반드시 axis로 설정된 기준에 따라 연산 수행
- 별도로 값을 지정하지 않으면 기본값은 axis = None으로 지정
- axis


- 집계 함수 : 배열객체에 대한 메소드로 사용하거나 Numpy 라이브러리의 메소드로 사용하는 두 가지 방법
- 합계 : sum()
- 최소값 : min()
- 최대값 : max()
- 누적 합계 : cumsum()
- 평균 : mean()
- 중앙값 : median()
- 크기 순으로 나열된 데이터에 대해 중앙에 위치하는 값
- 상관계수 : corrcoef()
- 데이터 간의 상관관계를 나타내는 수치(-1 <= r <= 1)
- 표준편차 : std()
- 분산의 제곱근, 데이터가 평균으로부터 흩어져 있는 정도
- 분산 = 편차(요소-전체평균)제곱의 평균
- 고유값 : unique()
- 위의 함수를 실행할 배열 객체를 만들어 줍니다.

- (1) 합계
- 전체 기준 : 모든 요소에 대한 합
- 배열 타입의 메서드 : arr.sum()
- numpy 함수 : np.sum(arr)
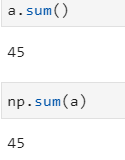
- 가로축 : row, 가로축별 합산
- 메서드, np함수의 파라미터 값 : axis =1
- 결과값 : [0번 row의 합, 1번 row의 합, 2번 row의 합]
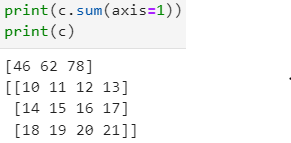
- 세로축 : column, 세로축별 합산
- 메서드, np함수의 파라미터 값 : axis =0
- 결과값 : [0번 column의 합, 1번 column의 합, 2번 column의 합]

- 전체 기준 : 모든 요소에 대한 합
- (2) 최소값(min()), 최대값(max())
- 전체 기준 : 모든 요소 중 최소, 최대값
- 배열 타입의 메서드 : arr.min() / arr.max()
- numpy 함수 : np.min(arr) / np.max(arr)

- 가로축 : 가로축 최소, 최대값 (axis = 1)

- 세로축 : 세로축 최소, 최대 (axis = 0)

- 전체 기준 : 모든 요소 중 최소, 최대값
- (3) 누적합계
- 전체 기준 : 누적합은 분기별 수출량이나, 월별 수입 증가량 같은 기간별 누적 수치가 필요할 때 쓴다.
- 배열 타입의 메서드 : arr.cumsum()
- numpy 함수 : np.cumsum()

- 가로축
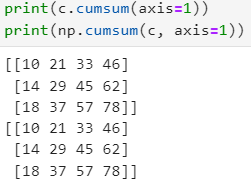
- 세로축

- 전체 기준 : 누적합은 분기별 수출량이나, 월별 수입 증가량 같은 기간별 누적 수치가 필요할 때 쓴다.
- (4) 평균
- 평균 역시 문법이 똑같다. (가로 : axis = 1 / 세로 : axis = 0)

- 평균 역시 문법이 똑같다. (가로 : axis = 1 / 세로 : axis = 0)
- (5) 중위값 : !! 중위값은 c.median() 문법이 불가능하다. !!
- Numpy의 중위값 도출 방법 : 중간 등위의 자료값이 없을 경우 맨 앞 자료와 맨 뒤 자료의 인덱스 번호의 평균을 중간 번호를 도출한다.
- 0번 인덱스 + 11번 인덱스 = 11/2 = 5.5인덱스 -> 5번째 자료와 6번째 자료의 평균을 도출
- c[5] = 15 , c[6] = 16 -> 평균은 15.5
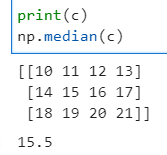
- 중위값 역시 가로중위값(axis = 1), 세로중위값(axis = 0)을 구할 수 있다.
4. 상관계수
-
상관계수란 ?
- 상관계수 : 등간척도 이상의 두 변수 중에서 한 변수의 변화가 다른 변수의 변화에 따라 어떤 변화가 일어나는지를 보여주는 지표입니다.
- 상관관계 : 한 변수의 변화에 따른 다른 변수의 변화 정도와 방향을 예측하는 분석기법입니다.
- 키 : 160 170 180 중 무게가 가장 나갈거 같은 키는? -> 180을 유추 : 우리 머리 속에 키가 클수록 몸무게가 높을 확률이 높다는 경험치가 존재
- 몸무게 : 몸무게가 높을수록 키가 클것이다라고 예측
- 이 관계를 수치화 시킨 것이 상관계수 -> 가장 상관이 있는 상태는 1로 가정
- 양의 상관관계 : 한쪽 수치가 늘어나면 상대쪽 수치가 늘어나는 관계
- 음의 상관관계 : 한쪽 수치가 늘어나면 상대쪽 수치가 줄어드는 관계
-
상관관계를 갖는 상이한 분야의 수치들을 비교했을 때 상대비교가 가능하다.(표준편차와 비슷한 역할을 한다.)
- ex> 성적에 어떤 요소가 더 큰 영향을 미치는가? -> 사교육비 vs 공부시간 : 상관계수로 상대 비교가 가능하다.
-
(1) numpy 함수 : np.corrcoef(arr1, arr2)

- 출력값이 1인 부분은 표본과 대상이 같은 비교(x를 x와, y를 y와 비교)이다. (오른쪽 아래로 향하는 대각선은 자기 자신과의 상관관계(항상 1) )
- 1에 가까울수록 상관이 높다는 뜻으로 x와 y의 상관관계지수가 0.7이므로 대단히 높은 상관관계를 가지고 있다는 뜻이다.
- 상관관계를 판단하는 대략적 수치 :
0.3 까지는 상관관계가 없다고 본다.
0.5 는 어느정도 상관관계가 있다고 본다.
0.7 은 매우 높은 상관관계.
0.9 이상은 같은 자료인지 의심을 해봐야 한다.
- 상관관계를 판단하는 대략적 수치 :
-
numpy에서는 2개를 초과하는 요소들의 상관도를 구하는 것은 불가능하다. (판다스는 2개요소씩 짝지은 다수 요소들의 상관도 판단 가능)
-
앞에서 말했듯 상관관계는 표준편차와 아주 유사한 개념이기 때문에 표준편차 역시 구할 수 있다.
- 표준편차 함수 :
- 배열타입 메서드 - arr.std()
- numpy 함수 - np.std(arr)
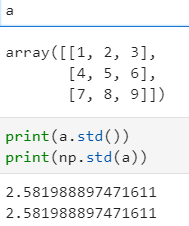
- 1~9까지 평균은 5 /(-4,-3,-2,-1,0,1,2,3,4) 분산은 6.66 이므로 6.66의 제곱근은 2x2=4 와 3x3=9 사이에 위치한다 : 즉 위 계산대로 2.58정도라고 볼 수 있다. (함수 계산이 맞다는 이야기)
- 표준편차 함수 :
5. 브로드캐스팅
-
(1) 브로드캐스팅(BroadCasting)
-
서로 다른 구조(shape)를 가진 배열에 대해 연산을 수행할 때 구조를 맞추는 과정을 브로드캐스팅이라고 합니다.
-
배열과 스칼라값 간의 연산
-
배열과 배열 간의 연산
-
브로드캐스팅 규칙 : 축의 길이가 일치하거나 둘 중 하나의 길이가 1인 두 배열에 대해 호환성을 가짐(주의 : 1일때만 성립)
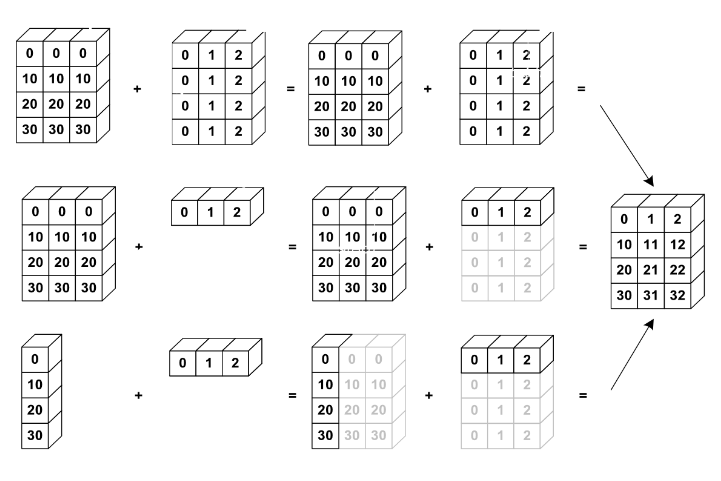
-
서로 행과 열이 안맞을 때 사용 가능한 브로드캐스팅
-
-
사용할 행렬 준비

- 그냥 합 연산은 좌표별 합으로 출력된다.

- 그냥 합 연산은 좌표별 합으로 출력된다.
-
(2) 배열과 값(single value, scala)
- 스칼라 값을 배열의 구조와 동일한 배열로 변형하여 연산 수행 (스칼라 값 : 단일 값을 의미)
- 구조가 다른 배열간의 연산 (a배열의 모든 요소에 각각 10씩 더하기)

- 스칼라 -> 배열 변형 (3행 3열의 구조에 모든 요소가 10인 배열 생성)
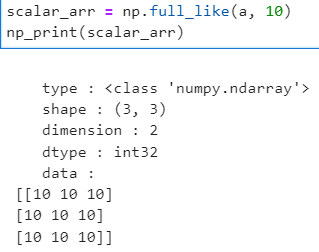
- a + 10 과 a + scalar(10) 함수는 같은 값을 도출한다.

-
(3) 서로 다른 구조의 배열
- 행, 열의 최대 길이를 기준으로 구조를 생성한 배열로 변형하여 연산 수행
- 확장된 행, 열에 대해서 기존 배열과 동일한 데이터로 구성
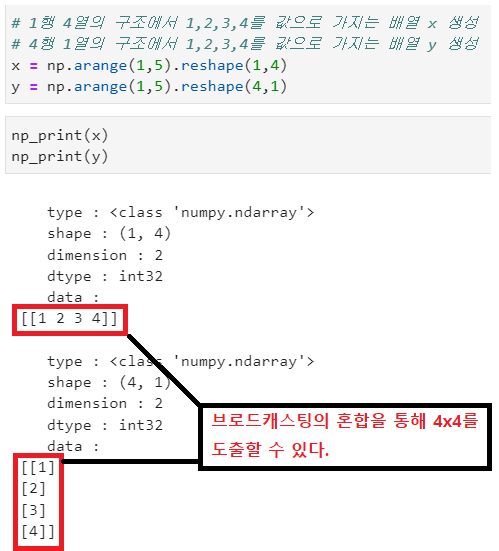
- 배열 x 를 동일한 값으로 4행으로 확장한 새로운 배열 생성
- 행 방향으로 배열 추가(세로길이 증가) 메서드 : np.append(arr1, arr2, axis=0) : 합산 시 내부 값이 합산되므로 append로 추가한다.

- 배열 y도 가능

-
결국 스칼라 함수에서 봤던 결론과 같이 x+y 의 결과값과 new_x + new_y의 결과값은 같다.

6. 벡터 연산
-
요소들에 대한 연산을 벡터 연산으로 처리하면 일반적인 for 반복문으로 연산 작업을 처리하는 것보다 월등히 뛰어난 처리 속도로 효율적인 작업 가능합니다.
-
Numpy는 연산 부분이 C언어로 구축되어 있어 연산속도가 파이썬보다 굉장히 빠르다.
- 예제 : 0 부터 시작하여 1억 개 요소를 가진 배열 생성

- time 함수를 사용하여 Numpy와 파이썬 기본 문법 간 연산 시간을 비교해봅시다.(해당 셀을 수행하는데 소요된 시간을 표기해주는 주피터노트북 명령어로 셀의 가장 상단에 위치해야됨 (주석 포함해서 가장 상단에 위치해야함.))
- 1억개의 자료를 누적합하는 함수를 시행합니다.

- 파이썬 기본 문법은 19.3초가 소요되었습니다.
- Numpy 문법으로 누적합을 도출하는 함수를 시행합니다.

- Numpy 문법은 약 50밀리세컨이 소요되었습니다.(즉,0.05초 걸림)
Numpy 연산을 애용합시다.
- 예제 : 0 부터 시작하여 1억 개 요소를 가진 배열 생성
