
행렬 자료의 활용
1. 배열 정렬
-
sort(axis = -1) 메서드 : axis를 기준으로 요소를 오름차순 정렬
- 기본값(axis = -1) : 현재 배열의 마지막 axis
- axis = 0 : 열 단위 정렬
- axis = 1 : 행 단위 정렬
- 원본 객체에 정렬 결과가 반영됨
-
np.sort(axis = -1) : axis를 기준으로 요소를 오름차순 정렬
- 기본값(axis = -1) : 현재 배열의 마지막 axis
- axis = 0 : 열 단위 정렬
- axis = 1 : 행 단위 정렬
- 정렬된 새로운 배열을 반환함
-
np.argsort(arr) : 정렬 순서를 반환
- 기본값(axis = -1) : 현재 배열의 마지막 axis
- axis = 0 : 열 단위 정렬
- axis = 1 : 행 단위 정렬
-
(1) 기존 문법에서의 자료 순번 변경
- 1차원 배열을 생성 후 내림차순 배열을 만듭니다.

- 1차원 배열을 생성 후 내림차순 배열을 만듭니다.
-
(2) Numpy 문법
- 일단 랜덤 출력시 자료값을 고정해둡니다.(정렬 시 비교)
- 1행으로 이루어진 5개의 무작위 숫자를 출력합니다.

- 오름차순 정렬
- np.sort(arr) 는 출력값만 보여줄 뿐 원본에 반영되지는 않습니다.
- arr.sort() 는 원본에 자료 변경이 반영됩니다.

- argsort() : 오름차순으로 변경시 이동할 인덱스 번호들을 출력합니다.

- array([1, 0, 4, 2, 3], dtype=int64) : [2,0,6,8,5] => b 행렬의 값이 아닌 인덱스 번호로 바꾸는 순서를 보여줌
- [1, 0, 4, 2, 3] => b 행렬의 인덱스번호 [1]이 첫번째로 와야한다는 뜻 : b[1] : 0 / b[0] : 2 / b[4] : 5 / b[2] : 6 / b[3] : 8
-
(3) 2차원 배열
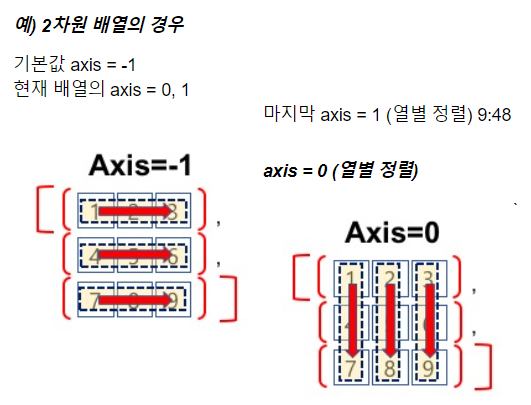
- 적용 배열 생성
- 0 이상 1 미만의 범위에서 무작위로 실수값을 가지는 3행 3열의 배열 2개 생성

- 0 이상 1 미만의 범위에서 무작위로 실수값을 가지는 3행 3열의 배열 2개 생성
- 기본 방향(axis = -1) -> 행별 정렬

- 열별 정렬(axis = 0)

- 적용 배열 생성
2. 인덱싱(Indexing), 슬라이싱(Slicing)
1. 인덱싱 : 하나의 요소에 대해 참조
-
각 차원에 따라 배열이 참조하는 인덱스의 개수가 다름
- 1차원 배열 : 인덱스 1개
- 2차원 배열 : 인덱스 2개
- 3차원 배열 : 인덱스 3개
-
인덱싱으로 참조한 요소에 대해 수정 가능
-
인덱스 배열을 전달하여 여러 개의 요소 참조
-
0 부터 23 까지 1씩 증가하는 값을 아이템으로 가지는 1차원 배열 생성

-
1차원 배열 : 인덱싱 문법과 동일하게 적용된다. (출력 및 변환)

-
2차원 배열 : reshape 후 인덱싱으로 자료 접근
- 2차원 배열 인덱싱 문법 : 2차원 배열[행인덱스, (열인덱스)]
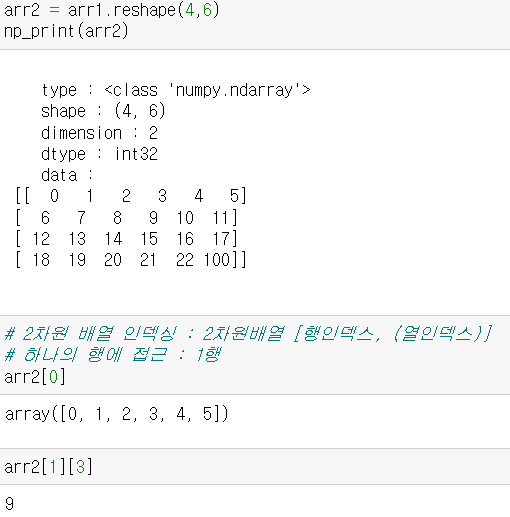
- 모든 열에 대하여 하나의 행 접근
([:] - row는 전체 / [,1] - 1번째 행을 출력)

- 응용 : 여러 개의 열 조회
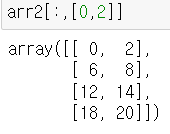
- 어려운 문제 : 0번째, 2번째 로우의 3번째, 5번째 행을 가져오도록 처리해보세요.

- 2차원 배열 인덱싱을 통한 값 수정
- 하나의 행/열에 대해 모두 동일한 값으로 수정 : 전달하는 값을 스칼라값으로 전달

- 서로 다른 값으로 수정 : 배열 구조에 맞춰서 자료 전달

- 2차원 배열 인덱싱 문법 : 2차원 배열[행인덱스, (열인덱스)]
-
3차원 배열
- 3차원 배열 생성구조 : 2개의 층 (페이지, 면), 4행 3열

- 3차원 배열 인덱싱 : arr[면, 행, 열]

- 3차원 배열 역시 배열 인덱싱으로 값 수정이 가능합니다.

- 여러 면,행,렬 수정하기

- 다중 조회 : 배열로 전달
((0행 0열), (1행 1열), (2행 2열))- 3차원 배열일 경우에 문법 : [페이지, [[0, 1, 2], [0, 1, 2]]]

- 3차원 배열일 경우에 문법 : [페이지, [[0, 1, 2], [0, 1, 2]]]
- 3차원 배열 역시 배열 인덱싱으로 값 수정이 가능합니다.
- 3차원 배열 생성구조 : 2개의 층 (페이지, 면), 4행 3열
2. 슬라이싱 : 여러 개의 요소에 대해 참조
-
axis 별로 범위 지정
- from_index : 시작 인덱스(포함), 0일 경우 생략 가능
- to_index : 종료 인덱스(미포함), 마지막 인덱스일 경우 생략 가능
- step : 연속되지 않은 범위의 경우 간격 지정
-
열만 조회하는 경우 : 전체 행에 슬라이싱으로 접근 후 특정 열을 조회
-
기본 문법 슬라이싱
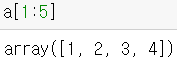
- 0 부터 23 까지 1씩 증가하는 정수값을 가지는 1차원 배열 생성

- 1차원 배열 슬라이싱 : 1번부터 4번까지 접근
- 1번째 인덱스로부터 14번째 인덱스까지 2개씩 건너뛰며 접근

- 0 부터 23 까지 1씩 증가하는 정수값을 가지는 1차원 배열 생성
-
2차원 배열
- 2차원 배열 슬라이싱 : 0행부터 3행까지 접근
- 문법 : 2d_array[행(:열:간격)]

- 문법 : 2d_array[행(:열:간격)]
- 응용
- 1행부터 4행에 대해서, 2열부터 3열까지 접근 후
- 0번째 행과 마지막 열을 제외한 모든 값을 99로 수정하기.

- 2차원 배열 슬라이싱 : 0행부터 3행까지 접근
-
신기한 것은 얕은 복사로 인해 원본 역시 변경이 일어났다는 점이다. (s_arr = b로 처리한 결과)

연습문제
- 아래 정보는 학생들의 학번, 영어 성적, 국어 성적, 수학 성적 정보 입니다.
- 해당 정보를 첫번째 행(row)에 학번, 두번째 행에 영어 성적, 세번째 행에 국어 성적, 네번째 행에 수학 성적을 저장한 배열로 만들고 학생별로 영어 성적을 오름차순 기준으로 각 열(column)을 정렬하세요.

- 일단 데이터를 행렬화 하고

- 내가 받은 힌트는 argsort() 이용하라는 것이었다.

- 여기까진 나도 할 줄 아는데... 결국 못풀었다. 정답은

- 그 인덱스 번호를 전체 행에 적용하시면 됩니다. 라고 하는데 어렵다.
- 일단 데이터를 행렬화 하고
3. 조건 색인(Boolean indexing)
- 배열의 요소에 대해 조건을 적용하여 True, False로 조건에 대한 결과 반환
- True에 해당하는 요소만 조회하여 조건을 만족하는 결과 반환
- 적용해볼 배열을 만들어보자.

- 스칼라 연산을 이용해 조건을 부여할 수 있다.

- 조건색인의 문법은 자료[자료를 포함한 조건식] 의 형태가 기본이다.
- 조건색인에 2개 이상의 조건을 걸고 싶을 때
- 각 조건마다 ()로 감싸주고 조건 사이를 and인 경우 & 로, or 인 경우 | 로 연결하면 된다.
- 조건색인에 2개 이상의 조건을 걸고 싶을 때
연습문제
- 조건색인을 활용해 공무원시험의 합격자 평균을 구해주세요.
합격점수는 60점 이상입니다. 아래는 시험 점수 결과입니다.

- 답은... 진도가 무지막지하여 어제 배웠는데 까먹은 mean() 함수

- 그래.. 평균을 내려면 mean이지
- 답은... 진도가 무지막지하여 어제 배웠는데 까먹은 mean() 함수
4. 배열복사
-
인덱싱, 슬라이싱을 통해 반환된 배열은 원본 배열에 대해 독립적인 새로운 객체가 아닌 원본 배열과 종속적인 객체
-
원본과 독립적인 복사본인 배열을 생성 : arr.copy() / np.copy(arr)
-
얕은 복사와 깊은 복사
- 얕은 복사(=)는 원본에 영향을 미치고 깊은 복사(.copy())는 자료 자체를 복사해서 새로 쓴다고 생각하면 쉽다.

- 배열로 해봐도 마찬가지

- 얕은 복사(=)는 원본에 영향을 미치고 깊은 복사(.copy())는 자료 자체를 복사해서 새로 쓴다고 생각하면 쉽다.
-
다른 배열로 확인해 보자

- 깊은 복사시 원본에 반영이 안되는 것을 확인할 수 있다.
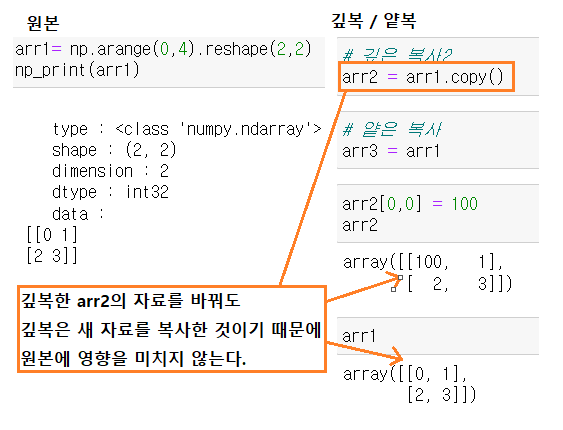
- 깊은 복사시 원본에 반영이 안되는 것을 확인할 수 있다.
5. 배열 변환
1. 전치(Transpose)
- 배열의 행/열 인덱스가 바뀌는 변환
- 배열객체.T : 행/열 인덱스가 바뀐 새로운 배열을 반환하며 원본은 변경되지 않음

- 예제

2. 배열 형태 변경
-
arr.ravel(), np.ravel(arr)
- 다차원 배열을 1차원 배열로 변환
- np.ravel() : 1차원으로 변환되는 결과는 원본 배열에 반영되지 않음
- arr.ravel() : 1차원으로 변환하는 배열의 요소가 변경되면 원본 배열에도 반영됨
-
!!!! 확인 결과 깊은 복사를 위해서는 .copy()함수를 통해 복사했을 때만 원본에 영향이 없는 깊은 복사가 일어난다. np.ravel()과 arr.ravel()은 형식 상관없이 얕은 복사가 일어난다(원본에 영향)
-
arr.reshape(new_shape), np.reshape(arr, new_shape)
- 원본 배열 객체의 구조(shape)를 변경
- 변경하려는 구조의 전체 요소 개수와 원본 배열의 전체 요소 개수가 동일해야 함
- 변경하려는 구조의 튜플 중 하나의 원소는 -1로 대체할 수 있고 다른 하나의 원소를 기준으로 계산되어 사용됨
- reshape() 메서드가 반환하는 배열의 요소가 변경되면 원본 배열에도 반영됨
-
다차원 배열을 1차원으로 변환

- 변환된 배열의 자료를 수정 시 원본에도 영향이 미침(얕은 복사)

- arr1을 6 * 2로 바꾸되 하나의 축에 대해 -1을 사용해봅시다.(-1 기입한 곳의 숫자를 알아서 계산해서 행렬을 맞춰줍니다.)

- 자료를 변환해봅시다.

- 역시 얕복이 일어난다. 깊은 복사를 위해서는 .copy()함수를 통해 복사했을 때만 원본에 영향이 없는 깊은 복사가 일어난다.
- 변환된 배열의 자료를 수정 시 원본에도 영향이 미침(얕은 복사)
3. 요소 변경, 추가, 삭제 (행렬 수가 안맞아도 맞춰줌 - 자료 반복을 통해 / 자료 삭제를 통해)
1) 요소 변경
- arr.resize(new_shape), np.resize(arr, new_shape)
- 배열 메서드를 사용하면 원본 변경, np 함수를 사용하면 새로운 배열 반환
- 배열의 구조(shape)를 변경하며 원본 배열의 요소 수와 동일하지 않아도 변경 가능
- 변경되는 배열의 요소 수가 동일할 경우 : reshape() 메서드와 동일한 결과
- 변경되는 배열의 요소 수가 더 많을 경우
- np.resize(arr, new_shape) : 원본을 변경하지 않고, 모자란 부분을 기존 배열 값에서 복사해서 추가
- arr.resize(new_shape) : 원본을 변경하고, 모자란 부분을 0으로 채움
- 공통적으로 new_shape은 튜플로 추가
- 변경되는 배열의 요소 수가 더 작을 경우 : 마지막 남은 요소 삭제
- 리사이즈 (1 이상 10 미만의 범위의 랜덤 정수값으로 3 * 5 구조를 가진 배열 생성)

- 변경되는 배열의 요소 수가 동일한 경우 : reshape()와 동일하게 동작

- 변경 후 배열의 요소 개수가 더 많은 경우 (refcheck = False인 경우만 크기가 다를 때 0으로 남는 자리를 채워줌)

- 변경되는 배열의 요소 수가 더 적은 경우 : 마지막 남은 요소를 삭제
- 크기가 원본과 resize를 이용했을 때 다르다면 refcheck=False를 반드시 넣는다. (안넣으면 에러 출력)

- 변경되는 배열의 요소 수가 동일한 경우 : reshape()와 동일하게 동작
2) 요소 추가
-
np.append(arr, values, axis=None)
- arr 마지막에 values를 추가
- axis 지정하지 않는 경우(기본값) : 1차원 배열로 변형되어 결합
- axis = 0 : 행 방향으로 결합 (단, 열의 개수가 동일해야 함)
- axis = 1 : 열 방향으로 결합 (단, 행의 개수가 동일해야 함)
- 원본 배열들에 반영되지 않음
-
각자의 범위에서 1씩 증가하는 숫자로 3*3 구조 배열 a와 b 생성

- axis 지정하지 않은 경우 : np.append(arr1, arr2) => axis = None
- arr1, arr2 모두 1차원으로 변형해서 추가함

- arr1, arr2 모두 1차원으로 변형해서 추가함
- 행단위(axis=0) / 열단위(axis=1) 추가

- 배열이 다른 경우 출력시 에러가 나므로 가로 혹은 세로 숫자가 맞다면 거기에 맞춰서 결합하거나 reshape, resize를 해서 결합하는 방법이 있다.
- axis 지정하지 않은 경우 : np.append(arr1, arr2) => axis = None
-
np.insert(arr, idx, values, axis=None)
- 지정한 인덱스(idx)에 value를 추가
- axis 지정하지 않는 경우(기본값) : 1차원 배열의 변형되고 해당 인덱스에 추가
- axis = 0 : 행 방향으로 n번째 행에 추가
- axis = 1 : 열 방향으로 n번째 열에 추가
- 원본 배열에 반영되지 않음
-
여기에

- 자료 추가하기
- axis 지정하지 않은 경우 : arr를 1차원 배열로 변형한 후 변형된 배열의 지정 index에 값 추가

- axis = 0 : 행 방향으로 index 번째 행을 추가

- axis = 1 : 열 방향으로 index 번째 행을 추가

- 요소마다 다른 값으로 행/열 추가하기

- axis 지정하지 않은 경우 : arr를 1차원 배열로 변형한 후 변형된 배열의 지정 index에 값 추가
- 자료 추가하기
3) 요소 삭제
- np.delete(arr, idx, axis=None)
- 지정한 인덱스(idx)에 해당하는 요소를 삭제
- axis 지정하지 않는 경우(기본값) : 1차원 배열로 변형되어 해당 인덱스에 해당하는 요소를 삭제
- axis = 0 : 행 방향으로 n번째 행을 삭제
- axis = 1 : 열 방향으로 n번째 열을 삭제
- 원본 배열에 반영되지 않음
- 여기에

- axis를 지정 안 하는 경우 : 1차원 배열로 변환 -> 지정한 index에 해당하는 요소를 삭제

- delete는 원본에 영향을 안미치는 듯 함

- 가로배열 / 세로배열 삭제

- delete는 원본에 영향을 안미치는 듯 함
- axis를 지정 안 하는 경우 : 1차원 배열로 변환 -> 지정한 index에 해당하는 요소를 삭제
4) 배열 결합
-
np.concatenate((arr1, arr2, ...), axis=0)
- axis = 0(기본값) : 행 방향으로 두 배열 결합 (단, 열의 개수가 동일)
- axis = 1 : 열 방향으로 두 배열 결합 (단, 행의 개수가 동일)
- 원본 배열들은 변경되지 않음
-
배열들 생성

- concatenate() 함수
- axis = 0(기본값) : 행 방향으로 두 배열 결합

- axis = 1 : 열 방향으로 두 배열 결합

- axis = 0 : 행 방향으로 두 배열 결합

- axis = 0(기본값) : 행 방향으로 두 배열 결합
- !!! 결합방향의 자료 개수가 맞지 않으면 에러 출력(행이나 열은 맞아야 병합 가능)
- concatenate() 함수
5) 배열 분리
- np.split(arr, indices_or_sections, axis=0)
- axis = 0(기본값) : 행 단위로 분리
- axis = 1 : 열 단위로 분리
- 원본 배열은 변경되지 않음
- 배열 생성

- 스칼라 값을 넘기면 균등하게 개수를 맞춰서 쪼개줍니다.
- 스칼라 값으로 처리시 반드시 나눈 개수가 정수로 떨어져야 합니다.
- [1,2,3]으로 쪼갠다는 의미 :
1번째 인덱스 시작 전 분할, 2번째 인덱스 시작 전 분할, 3번째 인덱스 시작 전 분할- 그래서 0리스트/1리스트/2리스트/3리스트(나머지)로 분할됨

- 그래서 0리스트/1리스트/2리스트/3리스트(나머지)로 분할됨
- 균등한 간격으로 열 기준으로 3개 분리

여기까지~
