https://pandas.pydata.org/docs/reference/frame.html
DataFrame의 구조
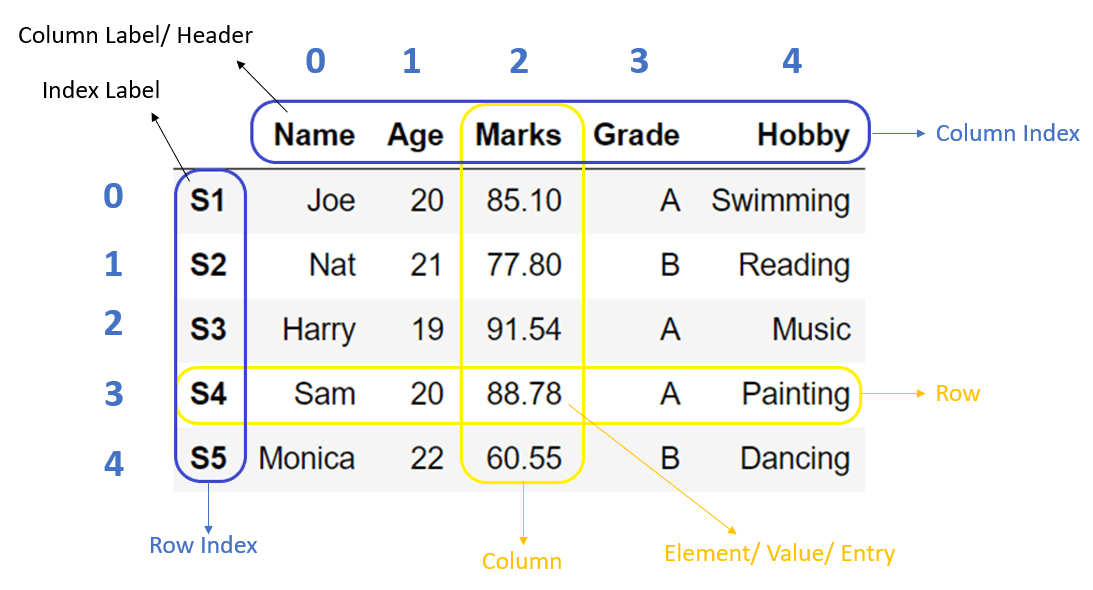
pandas는 파이썬에서 데이터를 처리하기 위한 라이브러리 중 하나로, 데이터를 다루기 위한 강력한 도구인 DataFrame을 제공한다. DataFrame은 표 형태의 데이터를 다루는 자료구조로, 행과 열을 가지며 각각의 열은 다양한 데이터 타입을 포함할 수 있다.
주로 쓰이는 함수
| 명령어 | 설명 |
|---|
pd.DataFrame(data) | DataFrame을 생성. data는 DataFrame을 생성하기 위한 데이터이며, 리스트, 딕셔너리, Numpy 배열 등 다양한 형태가 가능 |
df.head(n) | DataFrame의 상위 n개의 행을 출력. 기본값은 n=5 |
df.tail(n) | DataFrame의 하위 n개의 행을 출력. 기본값은 n=5 |
df.shape | DataFrame의 행과 열의 수를 출력. |
df.columns | DataFrame의 열 이름을 출력. |
df.index | DataFrame의 행 인덱스를 출력. |
df.info() | DataFrame의 정보를 출력. 각 열의 데이터 타입과 누락된 값의 개수 등을 보여줌. |
df.describe() | DataFrame의 요약 통계 정보를 출력. 각 열의 개수, 평균, 표준편차, 최소값, 25%, 50%, 75%, 최대값 등을 보여줌. |
df.sort_values() | DataFrame을 지정한 열을 기준으로 정렬. |
df.groupby() | DataFrame을 지정한 열을 기준으로 그룹화. |
df.merge() | 두 개의 DataFrame을 병합. |
df.dropna() | DataFrame에서 누락된 값을 가지는 행을 삭제. |
df.fillna() | DataFrame에서 누락된 값을 지정한 값으로 채움. |
판다스 모듈 임포트 하기
import pandas as pd
Pandas에서 엑셀 및 텍스트 파일 읽기
data = pd.read_csv('./data/01.data.csv', encoding='utf-8')
data.columns
data.columns[0]
data.rename(coulumns={data.columns[0]:'변경할 이름'}, inplace=True)
data.head()
excel_data = pd.read_excel('./data/01.excel.xls')
- 엑셀 설정
- 자료를 읽기 시작할 행(header) 지정
- 읽어올 엑셀의 컬럼을 지정(usecols)
excel_data = pd.read_excel(('./data/01.excel.xls'), header=2, usecols='B,D,G,J,N')
excel_data.rename(
coulumns={
data.columns[0]:'변경할 이름1',
data.columns[1]:'변경할 이름2',
data.columns[2]:'변경할 이름3'
},
inplace=True,
)
- Pandas의 데이터형을 구성하는 기본은 Series이다.
s = pd.Series([1,3,5,np.nan,6,8]
Series
- index와 value로 이루어져 있다.
- 한 가지 데이터 타입만 가질 수 있다.
pd.Series([1,2,3,4], dtype=np.float64)
0 1.0
1 2.0
2 3.0
3 4.0
dtype: float64
pd.Series([1,2,3,4], dtype=str)
0 1
1 2
2 3
3 4
dtype: object
pd.Series(np.array([1,2,3]))
0 1
1 2
2 3
dtype: int32
pd.Series({'key':'value'})
key value
dtype: object
data = pd.Series([1,2,'4',6])
data
0 1
1 2
2 4
3 6
dtype: object
data = pd.Series([1,2,3,4,5,6])
data % 2
0 1
1 0
2 1
3 0
4 1
5 0
dtype: int64
날짜 데이터
dates = pd.date_range('2023-03-27', periods=6)
DataFrame
- pd.Series()
- pd.DataFrame()
data = np.random.randn(6,4)
data
array([[ 1.30525756, 0.73862939, 0.60714642, 1.05939792],
[ 0.33454717, 0.38086935, 0.43812032, 0.16190495],
[-1.08102524, 0.30435644, -1.02498264, -1.67737907],
[ 2.10420039, 1.08870891, -1.29674975, 0.65929457],
[-0.15597073, 0.98285898, 0.45967896, -1.03715274],
[-1.44675823, 0.70153244, -0.86002622, 0.15041849]])
df = pd.DataFrame(data, index=dates, columns=["A","B","C","D"])
df
|
A |
B |
C |
D |
| 2023-03-27 |
1.305258 |
0.738629 |
0.607146 |
1.059398 |
| 2023-03-28 |
0.334547 |
0.380869 |
0.438120 |
0.161905 |
| 2023-03-29 |
-1.081025 |
0.304356 |
-1.024983 |
-1.677379 |
| 2023-03-30 |
2.104200 |
1.088709 |
-1.296750 |
0.659295 |
| 2023-03-31 |
-0.155971 |
0.982859 |
0.459679 |
-1.037153 |
| 2023-04-01 |
-1.446758 |
0.701532 |
-0.860026 |
0.150418 |
데이터 프레임 정보 탐색
df.head()
|
A |
B |
C |
D |
| 2023-03-27 |
1.305258 |
0.738629 |
0.607146 |
1.059398 |
| 2023-03-28 |
0.334547 |
0.380869 |
0.438120 |
0.161905 |
| 2023-03-29 |
-1.081025 |
0.304356 |
-1.024983 |
-1.677379 |
| 2023-03-30 |
2.104200 |
1.088709 |
-1.296750 |
0.659295 |
| 2023-03-31 |
-0.155971 |
0.982859 |
0.459679 |
-1.037153 |
df.tail()
|
A |
B |
C |
D |
| 2023-03-28 |
0.334547 |
0.380869 |
0.438120 |
0.161905 |
| 2023-03-29 |
-1.081025 |
0.304356 |
-1.024983 |
-1.677379 |
| 2023-03-30 |
2.104200 |
1.088709 |
-1.296750 |
0.659295 |
| 2023-03-31 |
-0.155971 |
0.982859 |
0.459679 |
-1.037153 |
| 2023-04-01 |
-1.446758 |
0.701532 |
-0.860026 |
0.150418 |
df.index
DatetimeIndex(['2023-03-27', '2023-03-28', '2023-03-29', '2023-03-30',
'2023-03-31', '2023-04-01'],
dtype='datetime64[ns]', freq='D')
df.columns
Index(['A', 'B', 'C', 'D'], dtype='object')
df.values
array([[ 1.30525756, 0.73862939, 0.60714642, 1.05939792],
[ 0.33454717, 0.38086935, 0.43812032, 0.16190495],
[-1.08102524, 0.30435644, -1.02498264, -1.67737907],
[ 2.10420039, 1.08870891, -1.29674975, 0.65929457],
[-0.15597073, 0.98285898, 0.45967896, -1.03715274],
[-1.44675823, 0.70153244, -0.86002622, 0.15041849]])
df.info()
<class 'pandas.core.frame.DataFrame'>
DatetimeIndex: 6 entries, 2023-03-27 to 2023-04-01
Freq: D
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 A 6 non-null float64
1 B 6 non-null float64
2 C 6 non-null float64
3 D 6 non-null float64
dtypes: float64(4)
memory usage: 240.0 bytes
df.describe()
|
A |
B |
C |
D |
| count |
6.000000 |
6.000000 |
6.000000 |
6.000000 |
| mean |
0.176708 |
0.699493 |
-0.279469 |
-0.113919 |
| std |
1.366892 |
0.313361 |
0.868914 |
1.040889 |
| min |
-1.446758 |
0.304356 |
-1.296750 |
-1.677379 |
| 25% |
-0.849762 |
0.461035 |
-0.983744 |
-0.740260 |
| 50% |
0.089288 |
0.720081 |
-0.210953 |
0.156162 |
| 75% |
1.062580 |
0.921802 |
0.454289 |
0.534947 |
| max |
2.104200 |
1.088709 |
0.607146 |
1.059398 |
데이터 정렬
- sort_values()
- 특정 컬럼(열)을 기준으로 데이터를 정렬한다.
- 기본은 오름차순, ascending=False 내림차순
df.sort_values(by='A')
|
A |
B |
C |
D |
| 2023-04-01 |
-1.446758 |
0.701532 |
-0.860026 |
0.150418 |
| 2023-03-29 |
-1.081025 |
0.304356 |
-1.024983 |
-1.677379 |
| 2023-03-31 |
-0.155971 |
0.982859 |
0.459679 |
-1.037153 |
| 2023-03-28 |
0.334547 |
0.380869 |
0.438120 |
0.161905 |
| 2023-03-27 |
1.305258 |
0.738629 |
0.607146 |
1.059398 |
| 2023-03-30 |
2.104200 |
1.088709 |
-1.296750 |
0.659295 |
df.sort_values(by='B', ascending=False, inplace=True)
df
|
A |
B |
C |
D |
| 2023-03-30 |
2.104200 |
1.088709 |
-1.296750 |
0.659295 |
| 2023-03-31 |
-0.155971 |
0.982859 |
0.459679 |
-1.037153 |
| 2023-03-27 |
1.305258 |
0.738629 |
0.607146 |
1.059398 |
| 2023-04-01 |
-1.446758 |
0.701532 |
-0.860026 |
0.150418 |
| 2023-03-28 |
0.334547 |
0.380869 |
0.438120 |
0.161905 |
| 2023-03-29 |
-1.081025 |
0.304356 |
-1.024983 |
-1.677379 |
데이터 선택
df['A']
2023-03-30 2.104200
2023-03-31 -0.155971
2023-03-27 1.305258
2023-04-01 -1.446758
2023-03-28 0.334547
2023-03-29 -1.081025
Name: A, dtype: float64
type(df['A'])
pandas.core.series.Series
df.A
2023-03-30 2.104200
2023-03-31 -0.155971
2023-03-27 1.305258
2023-04-01 -1.446758
2023-03-28 0.334547
2023-03-29 -1.081025
Name: A, dtype: float64
df[['A','B']]
|
A |
B |
| 2023-03-30 |
2.104200 |
1.088709 |
| 2023-03-31 |
-0.155971 |
0.982859 |
| 2023-03-27 |
1.305258 |
0.738629 |
| 2023-04-01 |
-1.446758 |
0.701532 |
| 2023-03-28 |
0.334547 |
0.380869 |
| 2023-03-29 |
-1.081025 |
0.304356 |
offset index
- [n:m] : n부터 m-1 까지
- 인덱스나 컬럼의 이름으로 slice 하는 경우는 끝을 포함한다.
df[0:3]
|
A |
B |
C |
D |
| 2023-03-30 |
2.104200 |
1.088709 |
-1.296750 |
0.659295 |
| 2023-03-31 |
-0.155971 |
0.982859 |
0.459679 |
-1.037153 |
| 2023-03-27 |
1.305258 |
0.738629 |
0.607146 |
1.059398 |
df['20230327':'20230329']
|
A |
B |
C |
D |
| 2023-03-27 |
1.305258 |
0.738629 |
0.607146 |
1.059398 |
| 2023-03-28 |
0.334547 |
0.380869 |
0.438120 |
0.161905 |
| 2023-03-29 |
-1.081025 |
0.304356 |
-1.024983 |
-1.677379 |
- loc : location
- index 이름으로 특정 행, 열을 선택한다.
df.loc[:,['A','B']]
|
A |
B |
| 2023-03-30 |
2.104200 |
1.088709 |
| 2023-03-31 |
-0.155971 |
0.982859 |
| 2023-03-27 |
1.305258 |
0.738629 |
| 2023-04-01 |
-1.446758 |
0.701532 |
| 2023-03-28 |
0.334547 |
0.380869 |
| 2023-03-29 |
-1.081025 |
0.304356 |
df.loc['20230327':'20230329',['A','D']]
|
A |
D |
| 2023-03-27 |
1.305258 |
1.059398 |
| 2023-03-28 |
0.334547 |
0.161905 |
| 2023-03-29 |
-1.081025 |
-1.677379 |
df.loc['20230330':'20230401','B':'D']
|
B |
C |
D |
| 2023-03-30 |
1.088709 |
-1.296750 |
0.659295 |
| 2023-03-31 |
0.982859 |
0.459679 |
-1.037153 |
| 2023-04-01 |
0.701532 |
-0.860026 |
0.150418 |
df.loc['20230328',['A','B']]
A 0.334547
B 0.380869
Name: 2023-03-28 00:00:00, dtype: float64
df
|
A |
B |
C |
D |
| 2023-03-30 |
2.104200 |
1.088709 |
-1.296750 |
0.659295 |
| 2023-03-31 |
-0.155971 |
0.982859 |
0.459679 |
-1.037153 |
| 2023-03-27 |
1.305258 |
0.738629 |
0.607146 |
1.059398 |
| 2023-04-01 |
-1.446758 |
0.701532 |
-0.860026 |
0.150418 |
| 2023-03-28 |
0.334547 |
0.380869 |
0.438120 |
0.161905 |
| 2023-03-29 |
-1.081025 |
0.304356 |
-1.024983 |
-1.677379 |
df.iloc[3]
A -1.446758
B 0.701532
C -0.860026
D 0.150418
Name: 2023-04-01 00:00:00, dtype: float64
df.iloc[3,2]
-0.8600262185096724
df.iloc[3:5, 0:2]
|
A |
B |
| 2023-04-01 |
-1.446758 |
0.701532 |
| 2023-03-28 |
0.334547 |
0.380869 |
df.iloc[[1,2,4], [0,2]]
|
A |
C |
| 2023-03-31 |
-0.155971 |
0.459679 |
| 2023-03-27 |
1.305258 |
0.607146 |
| 2023-03-28 |
0.334547 |
0.438120 |
df.iloc[:,1:3]
|
B |
C |
| 2023-03-30 |
1.088709 |
-1.296750 |
| 2023-03-31 |
0.982859 |
0.459679 |
| 2023-03-27 |
0.738629 |
0.607146 |
| 2023-04-01 |
0.701532 |
-0.860026 |
| 2023-03-28 |
0.380869 |
0.438120 |
| 2023-03-29 |
0.304356 |
-1.024983 |
condition
df
|
A |
B |
C |
D |
| 2023-03-30 |
2.104200 |
1.088709 |
-1.296750 |
0.659295 |
| 2023-03-31 |
-0.155971 |
0.982859 |
0.459679 |
-1.037153 |
| 2023-03-27 |
1.305258 |
0.738629 |
0.607146 |
1.059398 |
| 2023-04-01 |
-1.446758 |
0.701532 |
-0.860026 |
0.150418 |
| 2023-03-28 |
0.334547 |
0.380869 |
0.438120 |
0.161905 |
| 2023-03-29 |
-1.081025 |
0.304356 |
-1.024983 |
-1.677379 |
df['A'] > 0
2023-03-30 True
2023-03-31 False
2023-03-27 True
2023-04-01 False
2023-03-28 True
2023-03-29 False
Name: A, dtype: bool
df[df['A'] > 0]
|
A |
B |
C |
D |
| 2023-03-30 |
2.104200 |
1.088709 |
-1.296750 |
0.659295 |
| 2023-03-27 |
1.305258 |
0.738629 |
0.607146 |
1.059398 |
| 2023-03-28 |
0.334547 |
0.380869 |
0.438120 |
0.161905 |
df[df > 0]
|
A |
B |
C |
D |
| 2023-03-30 |
2.104200 |
1.088709 |
NaN |
0.659295 |
| 2023-03-31 |
NaN |
0.982859 |
0.459679 |
NaN |
| 2023-03-27 |
1.305258 |
0.738629 |
0.607146 |
1.059398 |
| 2023-04-01 |
NaN |
0.701532 |
NaN |
0.150418 |
| 2023-03-28 |
0.334547 |
0.380869 |
0.438120 |
0.161905 |
| 2023-03-29 |
NaN |
0.304356 |
NaN |
NaN |
컬럼 추가
- 기존 컬럼이 없으면 추가
- 기존 컬럼이 있으면 값 수정
df
|
A |
B |
C |
D |
| 2023-03-30 |
2.104200 |
1.088709 |
-1.296750 |
0.659295 |
| 2023-03-31 |
-0.155971 |
0.982859 |
0.459679 |
-1.037153 |
| 2023-03-27 |
1.305258 |
0.738629 |
0.607146 |
1.059398 |
| 2023-04-01 |
-1.446758 |
0.701532 |
-0.860026 |
0.150418 |
| 2023-03-28 |
0.334547 |
0.380869 |
0.438120 |
0.161905 |
| 2023-03-29 |
-1.081025 |
0.304356 |
-1.024983 |
-1.677379 |
df['E'] = ['one','one','two','three','four','five']
df
|
A |
B |
C |
D |
E |
| 2023-03-30 |
2.104200 |
1.088709 |
-1.296750 |
0.659295 |
one |
| 2023-03-31 |
-0.155971 |
0.982859 |
0.459679 |
-1.037153 |
one |
| 2023-03-27 |
1.305258 |
0.738629 |
0.607146 |
1.059398 |
two |
| 2023-04-01 |
-1.446758 |
0.701532 |
-0.860026 |
0.150418 |
three |
| 2023-03-28 |
0.334547 |
0.380869 |
0.438120 |
0.161905 |
four |
| 2023-03-29 |
-1.081025 |
0.304356 |
-1.024983 |
-1.677379 |
five |
df['E'].isin(['two'])
2023-03-30 False
2023-03-31 False
2023-03-27 True
2023-04-01 False
2023-03-28 False
2023-03-29 False
Name: E, dtype: bool
df['E'].isin(['two','five'])
2023-03-30 False
2023-03-31 False
2023-03-27 True
2023-04-01 False
2023-03-28 False
2023-03-29 True
Name: E, dtype: bool
df[df['E'].isin(['two','five'])]
|
A |
B |
C |
D |
E |
| 2023-03-27 |
1.305258 |
0.738629 |
0.607146 |
1.059398 |
two |
| 2023-03-29 |
-1.081025 |
0.304356 |
-1.024983 |
-1.677379 |
five |
특정 컬럼 제거
del df['E']
df
|
A |
B |
C |
D |
| 2023-03-30 |
2.104200 |
1.088709 |
-1.296750 |
0.659295 |
| 2023-03-31 |
-0.155971 |
0.982859 |
0.459679 |
-1.037153 |
| 2023-03-27 |
1.305258 |
0.738629 |
0.607146 |
1.059398 |
| 2023-04-01 |
-1.446758 |
0.701532 |
-0.860026 |
0.150418 |
| 2023-03-28 |
0.334547 |
0.380869 |
0.438120 |
0.161905 |
| 2023-03-29 |
-1.081025 |
0.304356 |
-1.024983 |
-1.677379 |
df.drop(['D'], axis=1)
|
A |
B |
C |
| 2023-03-30 |
2.104200 |
1.088709 |
-1.296750 |
| 2023-03-31 |
-0.155971 |
0.982859 |
0.459679 |
| 2023-03-27 |
1.305258 |
0.738629 |
0.607146 |
| 2023-04-01 |
-1.446758 |
0.701532 |
-0.860026 |
| 2023-03-28 |
0.334547 |
0.380869 |
0.438120 |
| 2023-03-29 |
-1.081025 |
0.304356 |
-1.024983 |
df.drop(['20230401'])
|
A |
B |
C |
D |
| 2023-03-30 |
2.104200 |
1.088709 |
-1.296750 |
0.659295 |
| 2023-03-31 |
-0.155971 |
0.982859 |
0.459679 |
-1.037153 |
| 2023-03-27 |
1.305258 |
0.738629 |
0.607146 |
1.059398 |
| 2023-03-28 |
0.334547 |
0.380869 |
0.438120 |
0.161905 |
| 2023-03-29 |
-1.081025 |
0.304356 |
-1.024983 |
-1.677379 |
apply()
df
|
A |
B |
C |
D |
| 2023-03-30 |
2.104200 |
1.088709 |
-1.296750 |
0.659295 |
| 2023-03-31 |
-0.155971 |
0.982859 |
0.459679 |
-1.037153 |
| 2023-03-27 |
1.305258 |
0.738629 |
0.607146 |
1.059398 |
| 2023-04-01 |
-1.446758 |
0.701532 |
-0.860026 |
0.150418 |
| 2023-03-28 |
0.334547 |
0.380869 |
0.438120 |
0.161905 |
| 2023-03-29 |
-1.081025 |
0.304356 |
-1.024983 |
-1.677379 |
df['A'].apply('sum')
1.060250919434379
df['A'].apply('mean')
0.1767084865723965
df['A'].apply('min'), df['A'].apply('max')
(-1.4467582258668867, 2.104200385522421)
df[['A','D']].apply('sum')
A 1.060251
D -0.683516
dtype: float64
df['A'].apply(np.sum)
2023-03-30 2.104200
2023-03-31 -0.155971
2023-03-27 1.305258
2023-04-01 -1.446758
2023-03-28 0.334547
2023-03-29 -1.081025
Name: A, dtype: float64
df['A'].apply('mean')
0.1767084865723965
def plusminus(num):
return 'plus' if num > 0 else 'minus'
df['A'].apply(plusminus)
2023-03-30 plus
2023-03-31 minus
2023-03-27 plus
2023-04-01 minus
2023-03-28 plus
2023-03-29 minus
Name: A, dtype: object
df['A'].apply(lambda num:'plus' if num>0 else 'minus')
2023-03-30 plus
2023-03-31 minus
2023-03-27 plus
2023-04-01 minus
2023-03-28 plus
2023-03-29 minus
Name: A, dtype: object
Pivot Table이란?
Pivot table은 데이터를 재구성하여 요약하는 테이블 형태의 데이터이다. 데이터를 행과 열을 바꾸고, 행과 열에 대한 요약 통계량을 표시하여 데이터를 쉽게 이해할 수 있게 한다. Pivot table은 엑셀에서도 유사한 기능으로 제공되고 있다.
Pivot Table 만들기
Pivot table을 만들기 위해서는 pandas의 pivot_table() 함수를 사용한다. 다음은 pivot_table() 함수의 기본적인 사용 방법이다.
import pandas as pd
df = pd.DataFrame({
'A': ['foo', 'foo', 'bar', 'bar', 'foo', 'foo', 'bar', 'bar'],
'B': ['one', 'one', 'one', 'two', 'two', 'two', 'one', 'two'],
'C': [1, 2, 3, 4, 5, 6, 7, 8],
'D': [10, 20, 30, 40, 50, 60, 70, 80]
})
table = pd.pivot_table(df, values='D', index=['A', 'B'], columns=['C'], aggfunc='sum')
print(table)
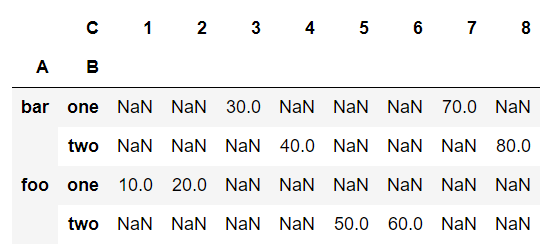
- df: pivot table을 만들기 위한 데이터프레임
- values: pivot table에 표시할 값의 열 이름
- index: pivot table의 행 인덱스로 사용할 열 이름 리스트
- columns: pivot table의 열 인덱스로 사용할 열 이름 리스트
- aggfunc: pivot table에서 각 셀에 대한 집계 함수 (기본값은 평균)
import pandas as pd
df = pd.DataFrame({
'A': ['foo', 'foo', 'bar', 'bar', 'foo', 'foo', 'bar', 'bar'],
'B': ['one', 'one', 'one', 'two', 'two', 'two', 'one', 'two'],
'C': [1, 2, 3, 4, 5, 6, 7, 8],
'D': [10, 20, 30, 40, 50, 60, 70, 80]
})
table = pd.pivot_table(df, values='D', index=['A', 'B'], columns=['C'], aggfunc=['mean', 'sum'])
print(table)
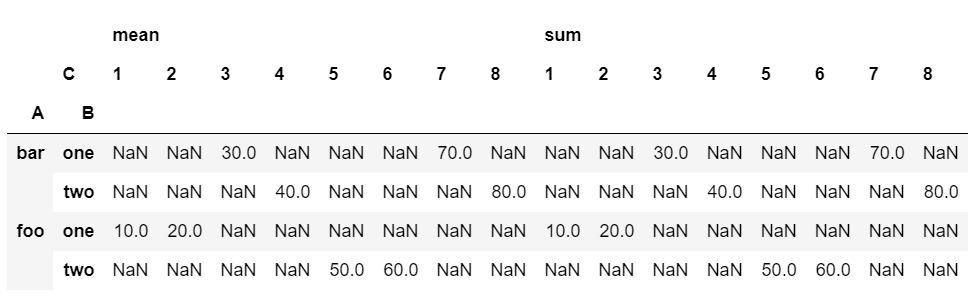
Pandas의 pivot table에서 aggfunc 인자는 집계 함수를 지정하는데 사용된다. aggfunc 인자에는 다양한 집계 함수들이 지정될 수 있다. 이 함수들은 각 셀에 대해 어떤 연산을 적용할지 결정한다.
sum: 각 셀의 값들의 합계
mean: 각 셀의 값들의 평균
count: 각 셀에 있는 값의 개수
min: 각 셀의 값들 중 최솟값
max: 각 셀의 값들 중 최댓값
aggfunc 인자에 여러 개의 함수를 리스트 형태로 지정하여 각 셀에 대해 여러 개의 집계 함수를 적용할 수도 있다.
