Scikit-learn이란?
머신러닝 알고리즘을 파이썬에서 쉽게 활용할 수 있도록 도와주는 라이브러리.
- 다양한 분류, 회귀, 클러스터링 알고리즘을 제공하며 쉽게 활용 가능
- 데이터 전처리, 세부조정, 모델 평가 등을 쉽게 수행할 수 있음
- 머신러닝 실습에 활용 가능한 샘플 데이터셋을 제공
- Numpy 등 다른 라이브러리와 호환성이 좋음
사이킷런의 주요 모듈
- 예시 데이터
sklearn.datasets : 사이킷런에 내장된 예제 데이터 세트 제공 - feature 처리
sklearn.preprocessing : 데이터 전처리에 필요한 다양한 가공 기능 제공
sklearn.feature_selection : 중요한 feature를 우선순위로 선택하기 위한 수행 기능 제공
sklearn.feature_extraction : 데이터의 벡터화된 feature 추출 기능 제공 - feature 처리&차원 축소
sklearn.decomposition : 차원 축소와 관련된 알고리즘 제공 (PCA, NMF, Truncated SVD) - 데이터 분리, 검증 & 파라미터 튜닝
sklearn.model_selection : 교차 검증을 위한 데이터 세트(Train&Test) 등 제공 - 평가
sklearn.metrics : Classification, Regression, Clustering 등 성능 측정 방법 제공(Accuracy, Precision, Recall, ROC-AUC, RMSE 등) - 머신러닝 알고리즘
sklearn.ensemble : 앙상블 알고리즘 제공(랜덤 포레스트, 에이다 부스트, 그래디언트 부스팅)
sklearn.linear_model : 회귀 관련 알고리즘 제공(선형 회귀 및 로지스틱 회귀 등)
sklearn.naive_bayes : 나이브 베이즈 알고리즘 제공(가우시안NB, 다항 분포 NB 등)
sklearn.neighbors : 최근접 이웃 알고리즘 제공(k-NN 등)
sklearn.svm : Support Vector Machine 알고리즘 제공
sklearn.tree : 의사결정 트리 알고리즘 제공
sklearn.cluster : 클러스터링 알고리즘 제공(k-means, 계층형, DBSCAN)
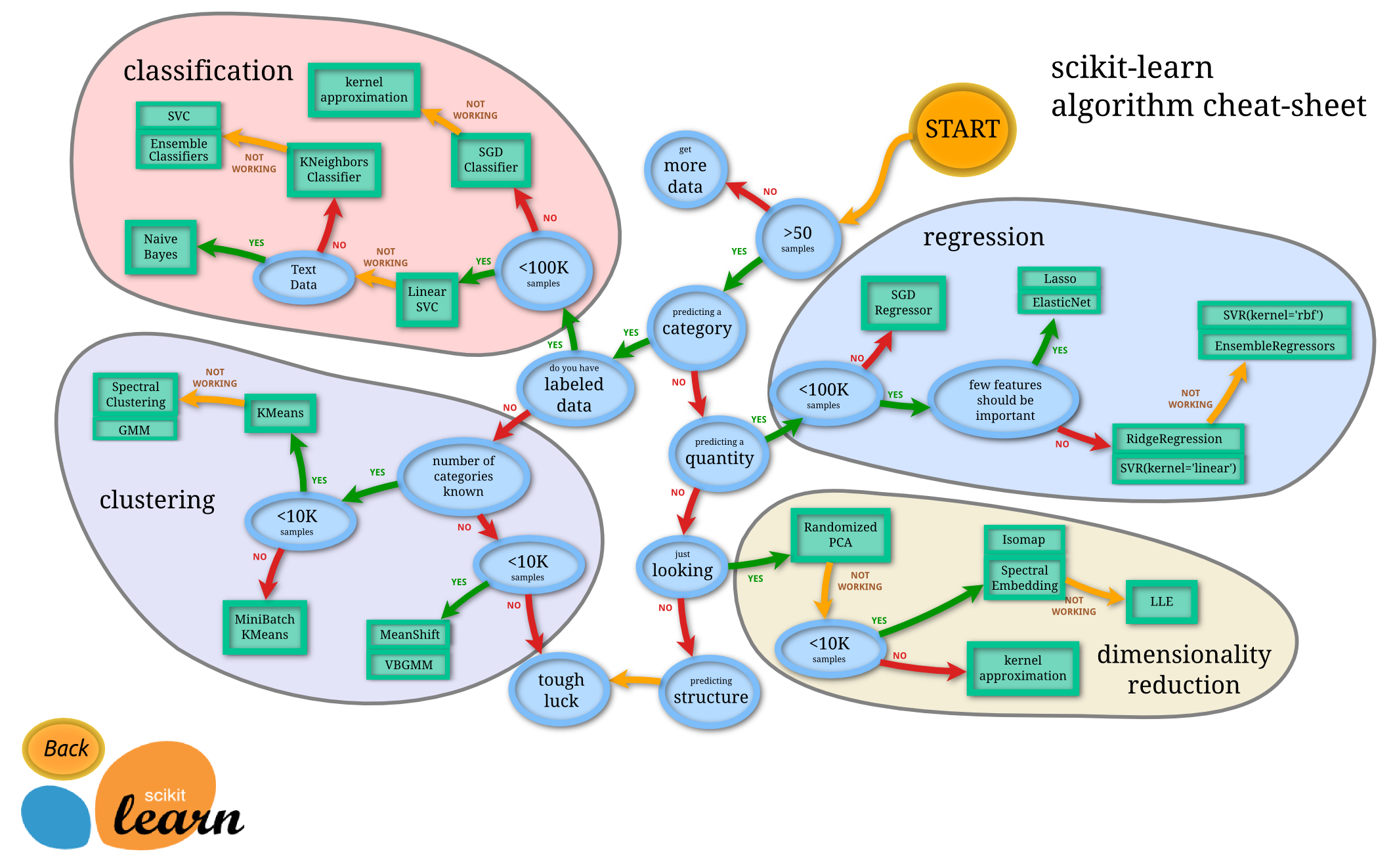
머신러닝 프로세스
데이터 준비 및 탐색 -> 특징(속성) 선택 -> 데이터셋 분리 -> 머신러닝 모델 훈련 -> 평가
샘플 데이터셋으로 실습해보기
데이터 : iris(붓꽃 데이터)
머신러닝 알고리즘 : 의사결정 나무(Decision Tree), K-최근접 이웃(K-Nearest Neighbor)
# 패키지/모듈 추가
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
import pandas as pd
from sklearn.metrics import accuracy_score
import seaborn as sns
#데이터셋 준비 및 탐색/특징 선택
iris = load_iris()
iris_data = iris.data
iris_label = iris.target
iris_df = pd.DataFrame(data=iris_data,columns=iris.feature_names)
iris_df ['label'] = iris.target
sns.pairplot(iris_df, x_vars=["sepal length (cm)"],
y_vars=["sepal width (cm)"], hue="label", height=5
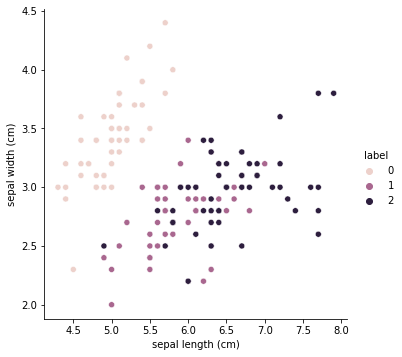
# 머신러닝 수행
X_train, X_test, y_train, y_test = train_test_split(iris_data, iris_label, test_size=0.2)
dt_clf = DecisionTreeClassifier()
knn_clf = KNeighborsClassifier()
dt_clf.fit(X_train, y_train)
knn_clf.fit(X_train, y_train)
y1_pred = dt_clf.predict(X_test)
y2_pred = knn_clf.predict(X_test)
print('DecisionTree 예측정확도 : {0:.4f}'.format(accuracy_score(y_test, y1_pred)))
print('k-NN 예측정확도 : {0: .4f}'.format(accuracy_score(y_test, y2_pred))) DecisionTree 예측정확도 : 0.9000
k-NN 예측정확도 : 0.9333
데이터 : 농구게임 성적
import pandas as pd
import numpy as np
df = pd.read_csv("https://raw.githubusercontent.com/wikibook/machine-learning/2.0/data/csv/basketball_stat.csv")
df.head()
df.Pos.value_counts() SG 50
C 50
Name: Pos, dtype: int64
# 스틸, 2점슛 데이터 시각화
import matplotlib.pyplot as plt
import seaborn as sns
sns.lmplot(x='STL', y='2P', data=df, fit_reg=False,
scatter_kws={"s": 150},
markers=["o", "x"],
hue="Pos") 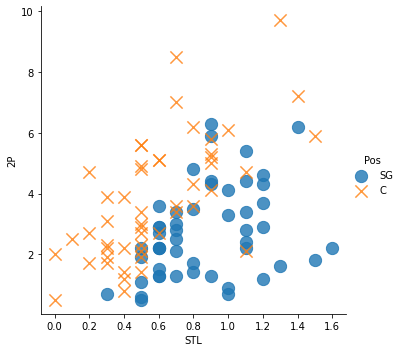
# 블로킹, 3점슛 데이터 시각화
sns.lmplot(x='BLK', y='3P', data=df, fit_reg=False,
scatter_kws={"s": 150},
markers=["o", "x"],
hue="Pos") 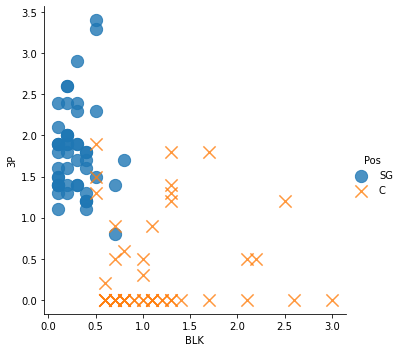
# 리바운드, 3점슛 데이터 시각화
sns.lmplot(x='TRB', y='3P', data=df, fit_reg=False,
scatter_kws={"s": 150},
markers=["o", "x"],
hue="Pos") 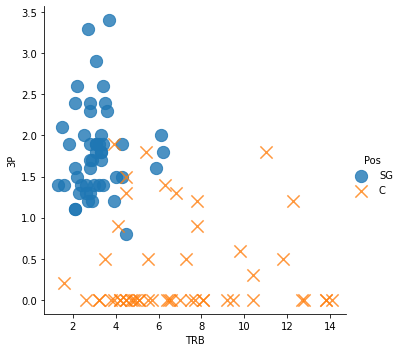
# 데이터 다듬기
df.drop(['2P', 'AST', 'STL'], axis=1, inplace = True)
df.head()
# 데이터 나누기(train,test용)
from sklearn.model_selection import train_test_split
train, test = train_test_split(df, test_size=0.2)
print(train.shape[0])
print(test.shape[0])
# 라이브러리 import
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
np.random.seed(5)
# 최적의 kNN파라미터 찾기
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import cross_val_score
max_k_range = train.shape[0] // 2
k_list = []
for i in range(3, max_k_range, 2):
k_list.append(i)
cross_validation_scores = []
x_train = train[['3P', 'BLK' , 'TRB']]
y_train = train[['Pos']]
for k in k_list:
knn = KNeighborsClassifier(n_neighbors=k)
scores = cross_val_score(knn, x_train, y_train.values.ravel(),
cv=10, scoring='accuracy')
cross_validation_scores.append(scores.mean())
cross_validation_scores
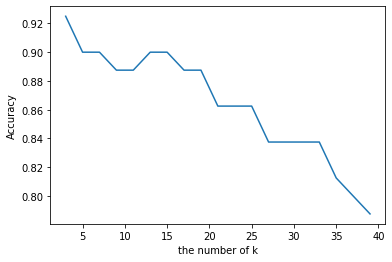
# k의 변화에 따른 정확도 시각화
plt.plot(k_list, cross_validation_scores)
plt.xlabel('the number of k')
plt.ylabel('Accuracy')
plt.show()
cvs = cross_validation_scores
k = k_list[cvs.index(max(cross_validation_scores))]
print("The best number of k : " + str(k) )
# k-NN 모델 테스트
from sklearn.metrics import accuracy_score
knn = KNeighborsClassifier(n_neighbors=k)
x_train = train[['3P', 'BLK', 'TRB']]
y_train = train[['Pos']]
knn.fit(x_train, y_train.values.ravel())
x_test = test[['3P', 'BLK', 'TRB']]
y_test = test[['Pos']]
pred = knn.predict(x_test)
print("accuracy : "+
str(accuracy_score(y_test.values.ravel(), pred)) )
comparison = pd.DataFrame({'prediction':pred, 'ground_truth':y_test.values.ravel()})
comparison.head(10) accuracy : 0.95

씨앗 데이터 분석가.